MCP 协议与六通道交付
知识如何到达 AI — 从 MCP 工具调用到 IDE 原生文件推送。
问题场景
知识库建好了。几百条 Recipe 安静地躺在 SQLite 里。但 AI 怎么用它?
最直接的方式是通过 MCP(Model Context Protocol)—— AI 调用 asd_search 工具,按需获取相关 Recipe。这种模式灵活、精确,但有一个前提:AI 需要"知道"自己该搜索。首次对话时,Agent 对项目一无所知,不知道有哪些约束、哪些模式——它不会主动搜索一个它不知道存在的知识库。
更优的方式是主动推送:把最重要的知识直接写入 IDE 的原生配置文件(.cursor/rules/、AGENTS.md、.github/copilot-instructions.md),AI 在每次对话开始时就自动读取。这不占用工具调用额度,不需要 AI 主动搜索——知识在对话前就已经注入了上下文。
但推送不能无限制——IDE 的上下文窗口有限。把 500 条 Recipe 全部推送进去,等于用知识噪声淹没了用户的实际问题。必须选择、压缩、分层。
Alembic 用六通道交付覆盖两种模式——按需查询(MCP 工具调用)和主动推送(IDE 文件写入),让知识从数据库到 AI 的路径既完整又可控。
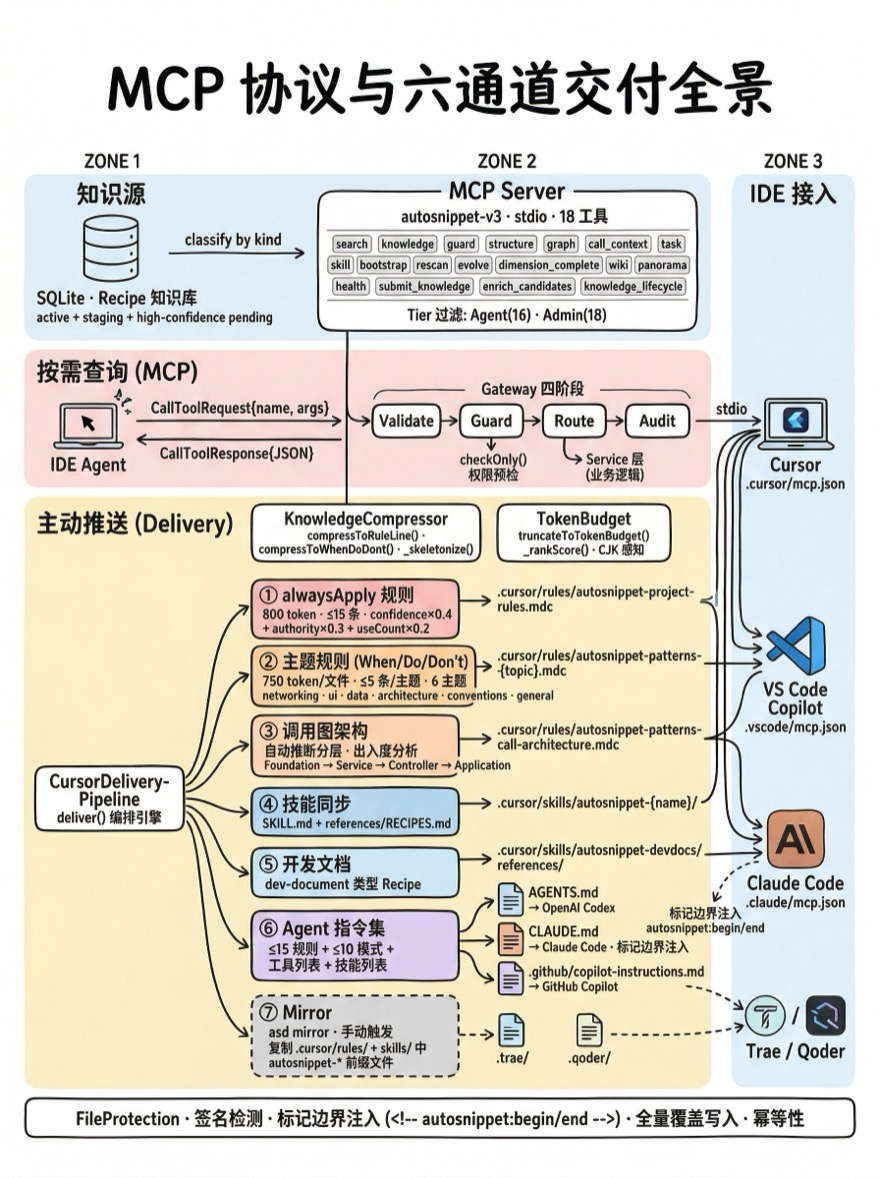
设计决策
MCP Server——18 个工具的协议层
MCP(Model Context Protocol)是 Anthropic 提出的标准协议,定义了 AI Agent 与外部工具之间的通信方式。协议提供三种能力——Tool(工具调用)、Resource(数据资源)和 Prompt(提示模板)。Alembic 使用 Tool 能力,注册了 18 个工具:
| # | 工具名 | 层级 | 职责 |
|---|---|---|---|
| 1 | asd_health | Agent | 服务健康检查 · KB 统计 |
| 2 | asd_search | Agent | 知识搜索(auto/keyword/semantic/context) |
| 3 | asd_knowledge | Agent | 知识浏览(list/get/insights/confirm_usage) |
| 4 | asd_structure | Agent | 项目结构发现 |
| 5 | asd_graph | Agent | 知识图谱查询 |
| 6 | asd_call_context | Agent | 调用上下文分析 |
| 7 | asd_guard | Agent | 代码合规检查 |
| 8 | asd_submit_knowledge | Agent | 知识提交(统一管线) |
| 9 | asd_skill | Agent | 技能管理(list/load/create/update/delete) |
| 10 | asd_bootstrap | Agent | 冷启动扫描 |
| 11 | asd_rescan | Agent | 增量重扫(保留 Recipe,重新分析项目) |
| 12 | asd_evolve | Agent | 批量 Recipe 进化决策 |
| 13 | asd_dimension_complete | Agent | 维度补全 |
| 14 | asd_wiki | Agent | Wiki 规划与生成 |
| 15 | asd_panorama | Agent | 项目全景分析 |
| 16 | asd_task | Agent | 意图管理 · 任务生命周期 · 决策记录 |
| 17 | asd_enrich_candidates | Admin | 候选知识富化 |
| 18 | asd_knowledge_lifecycle | Admin | 知识生命周期管理 |
18 个工具分为两个层级——Agent 层(16 个,AI Agent 可调用)和 Admin 层(2 个,仅管理员工具链使用)。层级通过环境变量 ASD_MCP_TIER 控制,MCP Server 在列出工具时过滤:
// ListTools 处理器:根据 Tier 过滤可见工具
setRequestHandler(ListToolsRequestSchema, () => {
const maxTier = TIER_ORDER[process.env.ASD_MCP_TIER || 'agent'];
return { tools: TOOLS.filter(t => TIER_ORDER[t.tier] <= maxTier) };
});请求流程——从 IDE 到知识库再回来:
IDE Agent → CallToolRequest{name, arguments}
→ McpServer._handleToolCall()
→ _gatewayGate() // 权限检查
→ _resolveHandler() // 路由到处理函数
→ handler(ctx, args) // 执行业务逻辑
→ 序列化结果
→ CallToolResponse{content: [{type: 'text', text: JSON}]}
← IDE AgentGateway 关卡是安全边界——不是所有工具调用都需要权限检查。asd_search(只读查询)直接放行;asd_submit_knowledge(写入操作)和 asd_skill(create/update/delete 操作)必须经过 Gateway 的权限验证。路由映射在 TOOL_GATEWAY_MAP 中声明,某些工具使用 resolver 函数根据参数动态决定是否需要关卡——例如 asd_skill 的 list 操作是只读的,create 操作才需要权限。
多 IDE 适配——MCP Server 使用 stdio 传输(标准输入/输出),这是最通用的方式:
| IDE | 连接方式 | 配置文件 |
|---|---|---|
| Cursor | stdio 原生支持 | .cursor/mcp.json |
| VS Code Copilot | stdio + Extension 适配 | .vscode/mcp.json |
| Claude Code | stdio 原生支持 | .claude/mcp.json |
| Trae / Qoder | Mirror 文件映射 | .trae/ · .qoder/ |
配置文件格式几乎相同——指定 node 命令和 mcp-server.js 路径。asd setup 命令自动生成这些文件,用户无需手动配置。Trae 和 Qoder 不直接支持 MCP,通过 Mirror 机制把 .cursor/ 下的规则和技能文件复制到对应目录,利用它们的原生文件加载能力间接交付知识。
六通道交付——分层推送
为什么要六个通道?因为 IDE 读取配置文件的方式不同——.cursor/rules/ 中标记 alwaysApply: true 的文件每次对话都加载,alwaysApply: false 的文件按相关性加载,.cursor/skills/ 是长文档格式的深度参考。不同类型的知识适合不同的交付形态:
| 通道 | 交付物 | 目标文件 | Token 预算 | 加载时机 |
|---|---|---|---|---|
| A | alwaysApply 一行式规则 | .cursor/rules/alembic-project-rules.mdc | 800 · ≤15 条 | 每次对话自动加载 |
| B | When/Do/Don't 主题规则 | .cursor/rules/alembic-patterns-{topic}.mdc | 750/文件 · ≤5 条 | 按主题相关性加载 |
| B+ | 调用图架构规则 | .cursor/rules/alembic-patterns-call-architecture.mdc | — | 架构相关时加载 |
| C | 项目技能同步 | .cursor/skills/alembic-{name}/ | — | Agent 主动引用 |
| D | 压缩开发文档 | .cursor/skills/alembic-devdocs/references/ | — | Agent 主动引用 |
| F | Agent 指令集 | AGENTS.md · CLAUDE.md · .github/copilot-instructions.md | — | 非 Cursor IDE 自动加载 |
| Mirror | IDE 配置镜像 | .trae/ · .qoder/ | — | asd mirror 手动触发 |
通道 A 是最高优先级——每次对话都会被 AI 读取的硬约束。800 token 的预算意味着只能放 15 条最重要的规则。这些规则从所有 active 状态的 rule 类型知识中,按排名得分(confidence × 40% + authority × 30% + useCount × 20% + activeBonus)选出 Top 15,压缩为一行式表述。
通道 B 按主题分组——networking、ui、data、architecture、conventions、general。每个主题文件标记 alwaysApply: false,IDE 根据当前对话内容的相关性决定是否加载。这让 750 条知识中的 networking 规则只在讨论网络代码时出现,不会污染 UI 讨论的上下文。
通道 F 是多 IDE 兼容层。不是所有 IDE 都支持 .cursor/rules/ 格式——Claude Code 读取 CLAUDE.md,GitHub Copilot 读取 .github/copilot-instructions.md,OpenAI Codex 读取 AGENTS.md。通道 F 把相同的知识(≤15 条规则 + ≤10 条模式 + MCP 工具列表 + 技能列表)写入这三种文件。
架构与数据流
CursorDeliveryPipeline——六通道编排
CursorDeliveryPipeline 是交付系统的主引擎——协调六个通道的知识选择、压缩和文件写入。完整的交付流程:
deliver():
① entries ← _loadEntries() // 加载 active + staging + 高置信度 pending
② {rules, patterns, facts, docs} ← _classify(entries) // 按 kind 分类
③ rulesGenerator.cleanDynamicFiles() // 清理旧的动态文件
④ channelA ← _generateChannelA(rules) // 一行式规则
⑤ channelB ← _generateChannelB(patterns, facts) // 主题规则
⑥ archResult ← _generateCallGraphArchitectureRules() // 调用图架构
⑦ channelC ← _generateChannelC() // 技能同步
⑧ channelD ← _generateChannelD(docs) // 开发文档
⑨ channelF ← _generateChannelF(rules, patterns) // Agent 指令集
→ return {channelA, channelB, channelC, channelD, channelF, stats}知识选择的关键在于 _loadEntries()——不是所有知识都参与交付。只有 active(已验证的正式知识)、staging(待发布的准正式知识)和高置信度 pending(尚未完全验证但可信度够高)的条目会被加载。deprecated 和 decaying 状态的知识被排除——它们不应该被推送给 AI。
文件写入策略是全量覆盖——每次交付重新生成所有通道文件。这比增量更新简单且可靠:不需要跟踪"上次交付了哪些知识",也不会因为知识删除而留下废弃文件。cleanDynamicFiles() 先清理上次生成的 alembic-* 文件,再写入新内容,保证幂等性。
KnowledgeCompressor——四种压缩策略
知识从 Recipe 的完整格式(200+ 字符的 markdown + 代码块 + 元数据)压缩到交付格式,是一个有损转换。KnowledgeCompressor 针对不同通道使用不同策略:
规则压缩(通道 A)——compressToRuleLine():
// 输入:完整 Recipe
{
doClause: "Use constructor injection for CookieProviding dependencies",
dontClause: "Don't import concrete implementations across module boundaries",
language: "swift",
scope: "language-specific"
}
// 输出:一行式规则
"- [swift] Use constructor injection for CookieProviding dependencies. Do NOT import concrete implementations across module boundaries."每条知识压缩为一行。语言标签只在 scope 非 universal 时添加。dontClause 的冗余前缀("Don't"、"Do not"、"Never")被去除后拼接为 "Do NOT ..." 后缀。
模式压缩(通道 B)——compressToWhenDoDont():
### @cookie-providing-di-pattern
- **When**: Creating or modifying CookieProviding and its dependencies
- **Do**: Use constructor injection for CookieProviding dependencies
- **Don't**: Import concrete implementations across module boundaries
- **Why**: Ensures testability and decouples module boundaries保留 trigger 标识符(方便 Agent 精确引用)、三条约束子句和理由的第一句话。coreCode 通过 _skeletonize() 裁剪到 ≤15 行,去除注释——保留骨架代码。
TokenBudget——预算与裁剪
每个通道有严格的 Token 预算:
const BUDGET = {
CHANNEL_A_MAX: 800, // 通道 A:整个文件上限
CHANNEL_A_MAX_RULES: 15, // 通道 A:最多 15 条规则
CHANNEL_B_MAX_PER_FILE: 750, // 通道 B:每个主题文件上限
CHANNEL_B_MAX_PATTERNS: 5, // 通道 B:每主题最多 5 条模式
};超预算时的裁剪策略是按排名截断——知识已经按 _rankScore() 排序,排名靠后的直接丢弃:
function truncateToTokenBudget(lines: string[], budget: number) {
const kept: string[] = [];
let tokensUsed = 0;
for (const line of lines) {
const lineTokens = estimateTokens(line); // CJK 感知:约 1.3 token/中文字符
if (tokensUsed + lineTokens <= budget) {
kept.push(line);
tokensUsed += lineTokens;
}
}
return { kept, dropped: lines.length - kept.length, tokensUsed };
}Token 估算使用 CJK 感知算法——中文字符的 token 密度(约 1.3 token/字符)高于英文(约 0.25 token/单词),如果用英文估算器处理中文知识库会严重低估实际消耗。
排名得分决定哪些知识最终进入交付文件:
score = confidence × 0.4 + authorityScore × 0.3
+ min(useCount, cap) × 0.2 + activeBonusconfidence 权重最高——高置信度的知识优先推送。useCount 有上限(避免"老知识"因为历史使用次数高而永远占据头部)。active 状态的知识获得额外加分。
通道 B+——调用图架构规则
通道 B+ 是一个独特的通道——它的内容不来自 Recipe,而是从代码库的调用图中自动推断:
1. 从数据库提取调用边(RawDbCallGraphAdapter.findCallEdges())
2. 聚合为目录级调用矩阵:'src/controllers' → Map('src/services' → count)
3. 计算出入度:in-degree 高 = 低层(被调用多 = 基础服务),out-degree 高 = 高层(调用多 = 控制器)
4. 推断分层架构:Foundation → Service → Controller → Application输出为一条架构规则文件 alembic-patterns-call-architecture.mdc,告诉 AI "这个项目的分层结构是什么,哪些模块不应该跨层调用"。这是用数据驱动的方式自动发现项目架构约束——不需要开发者手动编写架构文档。
通道 C——技能同步
技能(Skills)是比规则更长、更深入的文档——描述一个完整的领域实践(如"项目架构概览"、"编码标准"、"设计模式"等)。SkillsSyncer 把 Alembic 管理的技能同步到 .cursor/skills/ 目录:
同步两类来源:
① 内置技能:从 Alembic 包的 skills/ 目录直接复制
② 项目技能:从 Alembic/skills/project-* 转换
转换规则:
project-architecture → alembic-architecture
project-coding-standards → alembic-coding-standards
project-agent-guidelines → alembic-guidelines
...
每个技能输出:
.cursor/skills/alembic-{name}/SKILL.md
.cursor/skills/alembic-{name}/references/RECIPES.md ← 关联 Recipe 摘要references/RECIPES.md 是技能和知识库的桥梁——列出与该技能主题相关的 Recipe 摘要表格,让 Agent 知道"如果需要更详细的信息,可以通过 asd_search 搜索这些条目"。
通道 F——Agent 指令集
通道 F 的目标是为不支持 .cursor/rules/ 的 IDE 生成等效的指令文件。AgentInstructionsGenerator 生成三种文件:
- AGENTS.md——OpenAI Codex 和通用 Agent 读取
- CLAUDE.md——Claude Code 读取
- .github/copilot-instructions.md——GitHub Copilot 读取
内容结构统一:Coding Standards(≤15 条压缩规则)+ Architecture Patterns(≤10 条触发器表格)+ MCP Tools(16 个 Agent 工具列表)+ Skills(可用技能列表)。
CLAUDE.md 的特殊处理:
CLAUDE.md 通常是开发者手动创建的项目文档——Alembic 不能覆盖用户内容。解决方案是标记边界注入:
# 项目文档(用户编写的内容,不会被修改)
<!-- asd:begin -->
## Coding Standards
- [swift] Use constructor injection...
...
<!-- asd:end -->
更多用户内容...Alembic 只修改 <!-- asd:begin --> 和 <!-- asd:end --> 之间的区域,保留标记外的所有用户内容。如果文件不存在,整体生成并包含标记。
FileProtection 机制保护用户文件不被意外覆盖:
function checkWriteSafety(filePath: string) {
if (!fs.existsSync(filePath)) { return { canWrite: true }; }
// 读取文件头 1024 字节检测签名
const header = fs.readFileSync(filePath, 'utf8').slice(0, 1024);
const SIGNATURE = /auto-generated by (?:\[)?alembic(?:\])?|asd:begin/i;
if (SIGNATURE.test(header)) { return { canWrite: true, reason: 'alembic-owned' }; }
return { canWrite: false, reason: 'user-owned' };
}只有 Alembic 自己生成的文件(头部含签名)或标记区域才会被写入。用户手动创建的 AGENTS.md(不含签名)不会被覆盖。
核心实现
MCP Server 生命周期
MCP Server 的启动、运行和关闭是一个完整的生命周期:
// 启动
async start() {
await this.initialize(); // 加载 Bootstrap · 初始化容器
applyPendingAutoApprove(projectRoot); // 注入 autoApprove 到 mcp.json
const transport = new StdioServerTransport(); // stdio 传输
await this.sdkServer.connect(transport); // 开始监听
}
// 初始化
async initialize() {
const bootstrap = await Bootstrap.create(projectRoot);
bootstrap.configurePathGuard(projectRoot); // 路径安全
const container = await bootstrap.initServiceContainer({
db, auditLogger, gateway, constitution, config
});
this.registerGatewayActions(); // Gateway 路由注册
this.sdkServer = new SdkMcpServer({
name: 'alembic-v3', version: '3.0.0'
});
}Session 追踪——MCP Server 为每个连接维护一个 Session 对象,追踪工具调用次数、使用过的工具、意图状态等。IntentState 是一个状态机,追踪 Agent 从 Prime 到 Close 的完整行为模式:
interface IntentState {
phase: 'idle' | 'active' | 'ended';
primeQuery: string;
primeRecipeIds: string[];
primeLanguage: string | null;
primeModule: string | null;
primeScenario: string;
taskId?: string;
toolCalls: ToolCallRecord[];
searchQueries: string[];
mentionedFiles: string[];
mentionedModules: Set<string>;
decisions: DecisionRecord[];
driftEvents: DriftEvent[];
}IntentState 的完整生命周期——从 Prime 初始化到 Close 持久化为 JSONL 信号——在下方 Task 生命周期 一节详细展开。
Gateway 四阶段管线
Gateway 是 Alembic 的安全和审计中枢——MCP 工具调用和 HTTP API 请求都经过它。四个阶段:
Validate → Guard → Route → Audit
① Validate:请求格式校验——actor、action、resource 字段完整性
② Guard:权限 + 宪法检查——角色权限矩阵 + Constitution 约束
③ Route:分发到注册的 Action Handler——实际业务逻辑执行
④ Audit:审计日志记录——成功或失败都写入 audit_logsMCP Server 使用 Gateway 的两种模式:
checkOnly()——只执行 Validate + Guard,不执行 Route。用于_gatewayGate()的权限预检——在工具调用前验证权限,通过后再调用实际处理函数。execute()——完整四阶段。用于 HTTP API 请求。
这种设计让 MCP 和 HTTP 共享同一套权限和审计逻辑,但 MCP 的处理函数可以独立于 Gateway 的 Action Handler——因为 MCP 工具的参数格式和 HTTP 路由不同,处理逻辑需要各自适配。
Task 生命周期——意图驱动的 Agent 工作流
18 个 MCP 工具中,asd_task 是最特殊的一个——它不操作知识库,不检查代码,而是管理 Agent 自身的行为。当用户说"帮我实现网络缓存中间件"时,Agent 不应该直接开始写代码——它应该先加载相关的项目知识(这个项目怎么写中间件?有没有已有的模式?)、锚定一个任务追踪锚点、编码完成后检查合规性。
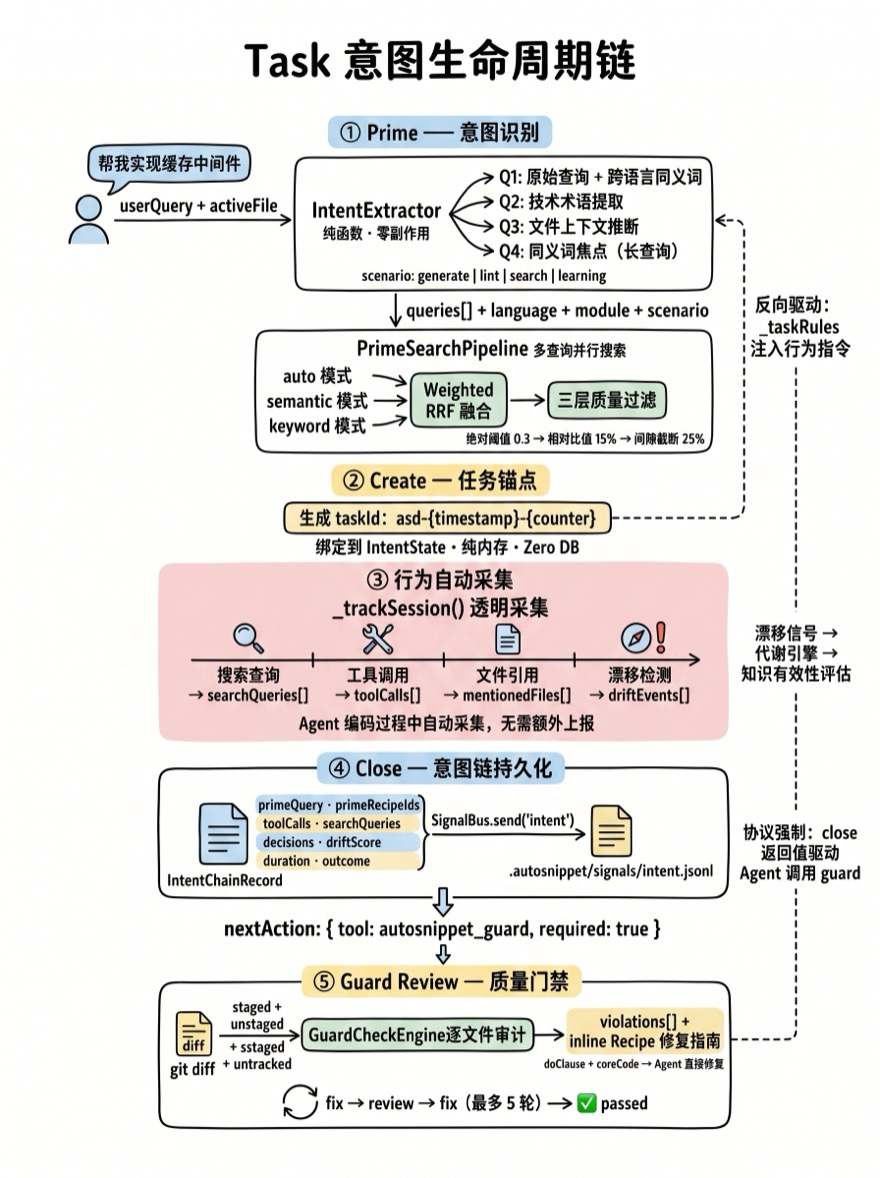
asd_task 的五个 operation 构成了一条完整的意图生命周期链:
prime → create → (Agent 编码过程) → close → guard
│ │ │ │ │
│ │ │ │ └─ 代码合规审计
│ │ │ └─ 持久化意图链 → SignalBus → JSONL
│ │ └─ 行为自动采集(工具调用、搜索查询、文件引用、漂移检测)
│ └─ 生成任务 ID,绑定到 IntentState
└─ 意图提取 + 知识检索 + IntentState 初始化整条链路的架构设计是 Zero DB——所有状态都在内存的 IntentState 状态机中维护,任务结束时通过 SignalBus 一次性持久化为 JSONL 信号。不需要数据库事务,不需要任务表——一个 Agent 会话同一时间只有一个活跃意图。
Prime——意图识别与知识预加载
Agent 在每条用户消息的第一步必须调用 asd_task({ operation: 'prime', userQuery, activeFile, language })。这是整条链路的起点——从用户的自然语言中提取结构化意图,主动检索相关知识。
Prime 的内部实现分为三层——Intake → Enrichment → Delivery:
userQuery + activeFile + language
↓ [IntentExtractor — Intake]
queries[] + keywordQueries[] + language + module + scenario
↓ [PrimeSearchPipeline — Enrichment]
relatedKnowledge (≤5) + guardRules (≤3)
↓ [Delivery]
envelope({ knowledge, searchMeta, _taskRules })Intake 层:IntentExtractor
IntentExtractor 是一组纯函数,无副作用、无 DI 依赖。它从用户查询中提取四类信号:
// lib/service/task/IntentExtractor.ts
export function extract(userQuery, activeFile?, language?): ExtractedIntent {
const queries = buildQueries(userQuery, activeFile); // 多查询集
const keywordQueries = buildKeywordQueries(userQuery); // 跨语言同义词
const inferredLang = inferLanguage(activeFile); // .swift → "swift"
const module = inferFileContext(activeFile); // "Modules/Network Manager"
const scenario = classifyScenario(userQuery); // generate|lint|search|learning
return { queries, keywordQueries, language, module, scenario, raw };
}**多查询集(Q1–Q4)**是 Prime 搜索质量的关键。单一查询只能匹配一种维度的知识——用户说"帮我加个缓存中间件",直接搜只命中标题含"缓存中间件"的 Recipe。多查询把同一个意图展开为四个搜索角度:
| 查询 | 内容 | 目的 |
|---|---|---|
| Q1 | 原始查询 + 跨语言同义词扩展 | 广度匹配:"帮我加个缓存中间件 cache 缓存 middleware 中间件" |
| Q2 | 提取的技术术语 | 精确匹配:"CacheMiddleware" |
| Q3 | 文件上下文推断 | 模块匹配:"Modules/Network NetworkManager" |
| Q4 | 纯同义词焦点(仅长查询) | 防 BM25 稀释:"cache 缓存 middleware 中间件" |
Q1 的跨语言同义词扩展值得展开。Alembic 维护了 40+ 组 EN↔CJK 映射(如 ['inject', 'injection', '注入']、['singleton', '单例']、['cache', 'caching', '缓存']),策略是逐 token 跨脚本扩展:英文 token 只添加中文同义词,中文 token 只添加英文同义词。这样混合语言查询("在 module 里用 singleton")能同时在两个方向上扩展。Q4 在长查询(>50 字符)时单独生成——因为长自然语言句子中,同义词被大量普通词稀释后对 BM25 评分的贡献趋近于零。
场景分类用正则匹配用户意图:
export function classifyScenario(userQuery: string): SearchScenario {
if (/帮我[加写做实现创建]|implement|add|create|新[增加建]/.test(q)) return 'generate';
if (/检查|review|lint|合规|违规|guard/.test(q)) return 'lint';
if (/什么是|怎么[用做]|原理|explain|学习/.test(q)) return 'learning';
return 'search';
}场景标签传递到 PrimeSearchPipeline,影响搜索策略的权重分配(generate 场景更关注 code-pattern 类型的知识,lint 场景更关注 rule 类型)。
Enrichment 层:PrimeSearchPipeline
PrimeSearchPipeline 接收 ExtractedIntent,执行多查询并行搜索并融合结果:
// lib/service/task/PrimeSearchPipeline.ts
async search(intent: ExtractedIntent): Promise<PrimeSearchResult | null> {
// 1. 三模式并行搜索
const autoPromises = intent.queries.map(q =>
this.#search.search(q, { mode: 'auto', limit: 8, rank: false })
);
const semanticPromise = this.#search.search(
intent.queries[0], { mode: 'semantic', limit: 6, rank: false }
);
const kwPromises = intent.keywordQueries.map(q =>
this.#search.search(q, { mode: 'keyword', limit: 8, rank: false })
);
// 2. Weighted RRF 融合
// RRF(d) = Σ origScore / (K + rank),保留原始分数量级
for (const [rank, item] of items.entries()) {
rrfScores.set(item.id, (rrfScores.get(item.id) ?? 0) + origScore / (60 + rank));
}
// 3. 三层质量过滤
const filtered = this.#qualityFilter(allResults);
// 绝对阈值(0.3)→ 相对比值(最高分的 15%)→ 间隙截断(25% 跌落)
// 4. 分类返回
return {
relatedKnowledge: filtered.filter(r => r.kind !== 'rule').slice(0, 5),
guardRules: filtered.filter(r => r.kind === 'rule').slice(0, 3),
searchMeta: { queries, scenario, language, module, resultCount, filteredCount }
};
}为什么 rank: false?PrimeSearchPipeline 自己做 RRF 融合,需要原始分数(BM25/FWS)。如果让搜索引擎的 CoarseRanker 先做 max-normalization + 新鲜度/权威度调整,分数会聚集到 0.35–0.41 区间,质量过滤器无法区分好结果和噪声。
三层质量过滤的设计思路:绝对阈值过滤明显的噪声(分数 <0.3 的一定不是好结果),相对比值适应不同查询的分数分布(搜"singleton"的最高分可能是 0.8,搜"那个什么什么管理器"可能只有 0.4),间隙截断检测分数断崖——如果排在前面的结果和后面的质量差距很大,后面的大概率是噪声。
Delivery 层:返回给 Agent
Prime 的返回值包含三个部分:
return envelope({
data: {
knowledge: { relatedKnowledge, guardRules },
searchMeta,
_taskRules, // ← 任务协议规则
},
message: '📋 Found 3 recipe(s), 1 guard rule(s)...'
});_taskRules 是一个嵌入在返回 JSON 中的指令块——告诉 Agent "你必须按这个协议工作":
📋 TASK RULES (MANDATORY):
🔑 YOU are the task operator — user speaks naturally, you translate to task operations.
• MUST prime on EVERY message BEFORE anything else
• MUST create task for non-trivial work (≥2 files OR ≥10 lines)
• MUST close when done with meaningful reason这是 Alembic 控制 Agent 行为的核心机制——MCP 工具通过返回值反向驱动 Agent。Agent 调用 Prime 获取知识上下文,同时收到了"你接下来该怎么做"的行为指令。通道 F(AGENTS.md、.github/copilot-instructions.md)的指令是静态注入的,_taskRules 是每次动态注入的——双重保障 Agent 遵循任务协议。
Create——任务锚点
当 Agent 判断用户需求是非简单操作(≥2 个文件或 ≥10 行修改)时,调用 asd_task({ operation: 'create', title: '...' })。
Create 的实现极简——只生成 ID 并绑定到 IntentState:
async function _create(ctx, args) {
const taskId = `asd-${Date.now().toString(36)}-${++_taskCounter}`;
const intent = ctx.session?.intent;
if (intent && intent.phase === 'active') {
intent.taskId = taskId;
intent.taskTitle = args.title;
}
return envelope({ data: { id: taskId, title: args.title } });
}不写数据库,不创建文件——纯内存状态。任务 ID 是 Prime→Close 链路的追踪锚点,在 Close 时写入 JSONL 信号。
中间过程——行为自动采集
Agent 在 Create 之后开始编码——搜索知识、读取文件结构、调用 Guard 检查片段。这些中间工具调用都被 McpServer 自动采集,不需要 Agent 额外上报:
// lib/external/mcp/McpServer.ts — _trackSession()
_trackSession(toolName: string, result: unknown): void {
const intent = this._session.intent;
if (intent.phase !== 'active') return;
// 1. 每次工具调用自动记录
intent.toolCalls.push({ tool: toolName, timestamp: Date.now(), args_summary: toolName });
// 2. 搜索查询自动提取
if (toolName === 'asd_search') {
const query = this._extractSearchQuery(result);
if (query) intent.searchQueries.push(query);
}
// 3. 文件引用自动推断模块
const files = this._extractMentionedFiles(toolName, result);
for (const f of files) {
if (!intent.mentionedFiles.includes(f)) {
intent.mentionedFiles.push(f);
const mod = this._inferModule(f);
if (mod) intent.mentionedModules.add(mod);
}
}
// 4. 意图漂移检测
this._detectDrift(toolName, intent);
}意图漂移检测是一个有意思的设计。Prime 时 Agent 说要"实现缓存中间件",但编码过程中它开始搜索"数据库迁移"——这意味着意图发生了漂移。检测逻辑有两个触发条件:
- 模块漂移:Agent 提及的文件所属模块不是 Prime 时推断的模块
- 查询漂移:搜索关键词与
primeQuery的关键词重叠度 <30%
漂移事件记录在 DriftEvent[] 中,Close 时随 IntentChain 一起持久化。这些信号后续被代谢引擎(Ch12)消费——高漂移分数的任务可能揭示知识覆盖的盲区(Agent 搜不到需要的信息才会漂移到其他方向)。
Close——意图链持久化
编码完成后,Agent 调用 asd_task({ operation: 'close', id: 'asd-xxx', reason: '...' })。Close 做两件事:持久化整条意图链,然后强制触发 Guard。
IntentChainRecord 持久化:
function _persistIntentChain(ctx, intent, outcome, reason) {
const chain: IntentChainRecord = {
sessionId, taskId, outcome, // 'completed' | 'failed' | 'abandoned'
// Prime 基准
primeQuery, primeRecipeIds, primeLanguage, primeModule, primeScenario,
searchMeta,
// 累积数据
toolCalls, searchQueries, mentionedFiles, decisions,
// 漂移追踪
driftEvents, driftScore: _computeDriftScore(intent),
// 时间
startedAt, endedAt, duration, closeReason
};
// 通过 SignalBus 发射 → SignalTraceWriter 订阅写入 JSONL
signalBus.send('intent', 'TaskHandler', driftScore, { target: taskId, metadata: { chain } });
}一条 IntentChainRecord 完整记录了"Agent 在这次任务中做了什么"——从 Prime 时的意图到 Close 时的结果,中间用了哪些工具、搜了什么、看了哪些文件、做了什么决策、意图有没有漂移。写入 .asd/signals/intent.jsonl 后,代谢引擎用这些数据做知识有效性评估——频繁被 Prime 检索到但 Agent 最终没用的 Recipe 可能需要衰退。
强制触发 Guard:
Close 的返回值包含一个 nextAction 字段——这不是建议,而是强制指令:
return envelope({
data: {
closed: { id, reason, closedAt: Date.now() },
nextAction: {
tool: 'asd_guard',
args: {},
required: true,
reason: 'Post-close compliance review — check diff for violations before moving on.'
}
},
message: '✅ Closed: asd-xxx\n⚠️ REQUIRED: You MUST call asd_guard NOW...'
});Agent 读到 nextAction.required: true,必须在下一步调用 asd_guard()。这个设计保证了每次编码后都有质量门禁——不依赖 Agent 的"自觉性",而是通过协议层强制执行。
Guard Review——编码后质量门禁
Guard 被 Close 触发后,进入 Review 模式——自动检测变更文件、逐文件审计、内联 Recipe 修复指南:
// lib/external/mcp/handlers/guard.ts — guardReview()
export async function guardReview(ctx, args) {
// 1. 轮次追踪——防无限 fix-review 循环(上限 5 轮)
const round = (_reviewRounds.get(projectRoot) || 0) + 1;
if (round > MAX_REVIEW_ROUNDS) return { passed: true, maxRoundsReached: true };
// 2. 文件确定:无参数 → git diff(staged + unstaged + untracked)
const filePaths = args.files?.length
? resolveExplicit(args.files)
: _detectChangedFiles(projectRoot);
// 3. 逐文件审计
for (const fp of filePaths) {
const auditResult = engine.auditFile(fp, code);
// 4. 内联 Recipe 修复指南——违规项关联对应的 Recipe
for (const v of auditResult.violations) {
const recipe = recipeMap.get(v.ruleId);
if (recipe) {
v.recipe = { title, doClause, dontClause, coreCode };
}
}
}
// 5. 违规 → Agent 按 recipe 修复 → 再次调用 guard → 直到 passed 或 5 轮
return { passed, files, totalViolations, reviewRound, capabilityReport };
}Guard Review 的几个关键设计:
自动检测变更文件:无参数调用时从 git status 提取 staged + unstaged + untracked 文件,过滤掉二进制和非源码文件。Agent 不需要告诉 Guard "我改了哪些文件"——Guard 自己知道。
Violation 内联 Recipe:每个违规项关联到知识库中对应的 Recipe,返回给 Agent 时带上 doClause(该怎么做)和 coreCode(代码骨架)。Agent 不需要再搜索怎么修——修复指南就在违规报告里。
轮次追踪:Agent 修完后再调 Guard、Guard 又报问题、Agent 又修……这个循环可能无限下去。MAX_REVIEW_ROUNDS = 5 设置了上限——5 轮后强制通过,剩余问题标记为 follow-up。这平衡了代码质量和开发效率。
Capability Report:Guard 不能检查所有类型的问题——跨文件的架构依赖分析、协议一致性校验等超出了静态检查能力。capabilityReport 把这些不确定结果结构化上抛给 Agent,让 Agent 自行判断是否需要人工审查:
capabilityReport: {
executedChecks: { swift: { total: 12, executed: 10, skipped: 2 } },
uncertainResults: [
{ ruleId: 'layer-isolation', message: '...', reason: 'requires-cross-file-analysis' }
],
boundaries: ['layer-isolation', 'protocol-conformance']
}完整交互时序
用户说"帮我实现网络缓存中间件"时,Agent 和 MCP Server 之间的完整交互:
User: "帮我实现网络缓存中间件"
│
Agent ──── ① asd_task({ operation: "prime", userQuery: "帮我实现网络缓存中间件" })
│ IntentExtractor: scenario=generate
│ queries=["帮我实现网络缓存中间件 cache 缓存 middleware 中间件", "CacheMiddleware"]
│ PrimeSearchPipeline: 3 recipes + 1 guard rule (RRF 融合 + 三层质量过滤)
│ ← relatedKnowledge + guardRules + _taskRules
│
Agent ──── ② asd_task({ operation: "create", title: "实现网络缓存中间件" })
│ ← { id: "asd-m2x8k-1" }
│
Agent ──── ③ asd_search({ query: "Alamofire middleware" })
│ → _trackSession: intent.toolCalls + intent.searchQueries 自动采集
│ ← 搜索结果
│
Agent ──── ④ asd_structure({ operation: "files", target: "NetworkKit" })
│ → _trackSession: intent.mentionedFiles + intent.mentionedModules 自动采集
│ ← 文件列表
│
│ ... Agent 按 Recipe 指导编写 CacheMiddleware.swift ...
│
Agent ──── ⑤ asd_task({ operation: "close", id: "asd-m2x8k-1", reason: "Implemented" })
│ → _persistIntentChain → SignalBus → intent.jsonl
│ → IntentState 重置为 idle
│ ← nextAction: { tool: "asd_guard", required: true }
│
Agent ──── ⑥ asd_guard({})
│ → guardReview: git diff → 审计变更文件 → 内联 Recipe 修复指南
│ ← { passed: false, violations: [...], reviewRound: 1 }
│
│ ... Agent 按 violation.recipe.coreCode 修复 ...
│
Agent ──── ⑦ asd_guard({})
│ ← { passed: true, reviewRound: 2 }
│
Agent ──── "Done. 已实现 CacheMiddleware,Guard 审计通过。"这条链路的设计理念:用户只说自然语言,Agent 是操作者。_taskRules 通过 Prime 返回值注入行为指令,nextAction 通过 Close 返回值强制触发 Guard——两个反向控制点让 MCP 工具驱动 Agent 遵循任务协议,而不是依赖 Agent 自觉记住"我应该在完成后检查代码"。
HTTP API——RESTful 路由
HTTP Server 为 Dashboard 和外部集成提供 RESTful API:
GET /api/v1/health → 健康检查
GET /api/v1/health/ready → 就绪检查
GET /api/v1/knowledge → 知识列表(分页 · 过滤)
POST /api/v1/search → 搜索
POST /api/v1/guard → Guard 检查
GET /api/v1/guard/rules → Guard 规则列表
GET /api/v1/panorama → 全景数据
GET /api/v1/recipes → Recipe 浏览
GET /api/v1/skills → 技能列表
POST /api/v1/bootstrap → 启动 Bootstrap
GET /api/v1/audit → 审计日志
GET /api/v1/task → 任务列表
GET /api-spec → OpenAPI 规范中间件栈的顺序经过精心排列:
performanceMonitor → 性能追踪(计时开始)
helmet → 安全头(CSP · XSS 保护)
requestLogger → HTTP 日志
express.json(10mb) → JSON 解析(10MB 限制)
cors → 跨域(Dashboard 需要)
roleResolver → 角色检测
gatewayMiddleware → 注入 Gateway 实例
timeout → 超时配置(扫描 600s · 普通 60s)roleResolver 从请求头中检测调用者角色——Dashboard(本地请求)自动获得 developer 角色,外部请求降级为 contributor 或 visitor。不同角色在 Gateway 中有不同的权限范围。
错误响应格式统一为:
{
"success": false,
"error": {
"message": "Permission denied for action: knowledge:create",
"code": "PERMISSION_DENIED",
"statusCode": 403
},
"timestamp": 1712833200000
}错误码映射:PERMISSION_DENIED → 403、CONSTITUTION_VIOLATION → 422、NOT_FOUND → 404、INTERNAL_ERROR → 500。
Mirror 机制
Mirror 不是自动触发的——它通过 asd mirror CLI 命令手动执行。原因是:Trae 和 Qoder 的用户是少数,自动 Mirror 会为大多数用户创建不需要的目录。
Mirror 的实现很直接:
_mirrorToIDE(targetDirName: string) {
// 1. 复制 .cursor/rules/alembic-* → {target}/rules/
const rules = fs.readdirSync(rulesPath)
.filter(f => f.startsWith('alembic-'));
for (const file of rules) {
fs.cpSync(src, dest, { recursive: true, force: true });
}
// 2. 复制 .cursor/skills/alembic-* → {target}/skills/
const skills = fs.readdirSync(skillsPath)
.filter(d => d.startsWith('alembic-'));
for (const dir of skills) {
fs.cpSync(src, dest, { recursive: true, force: true });
}
}只复制 alembic- 前缀的文件和目录——用户自己创建的规则和技能不会被 Mirror。这避免了"Alembic 把用户在 Cursor 里手动写的规则推到 Trae 里"的意外行为。
运行时行为
场景 1:首次 Setup——六通道文件生成
用户执行 asd setup。Bootstrap 完成后调用 CursorDeliveryPipeline.deliver():
知识库:120 条 active Recipe(50 rules · 40 patterns · 20 facts · 10 documents)
→ 通道 A:Top 15 规则 → alembic-project-rules.mdc (780 tokens)
→ 通道 B:5 主题文件
networking (5 patterns) → alembic-patterns-networking.mdc
ui (4 patterns) → alembic-patterns-ui.mdc
data (3 patterns) → alembic-patterns-data.mdc
architecture (5 patterns) → alembic-patterns-architecture.mdc
conventions (3 patterns) → alembic-patterns-conventions.mdc
→ 通道 B+:调用图分析 → alembic-patterns-call-architecture.mdc
→ 通道 C:3 技能同步 → alembic-architecture/ · alembic-coding-standards/ · ...
→ 通道 D:10 文档 → alembic-devdocs/references/*.md
→ 通道 F:AGENTS.md + .github/copilot-instructions.md用户打开 Cursor,开始对话——AI 自动读取通道 A 的 15 条硬约束。讨论网络代码时,Cursor 自动加载 alembic-patterns-networking.mdc。Agent 需要深入了解架构时,引用 alembic-architecture 技能。
场景 2:新知识批准——增量交付
Agent 产出了一条新的 code-pattern,经过 Guard 验证后进入 active 状态。系统触发增量交付——重新执行 deliver(),六个通道全部重新生成。
为什么不只更新受影响的通道?因为新知识的排名可能影响通道 A 的 Top 15 选择——一条新的高置信度规则可能把原来的第 15 条挤出去。全量重新生成保证一致性,而生成过程本身只需要几十毫秒(内存中的字符串拼接 + 文件写入)。
场景 3:MCP 工具调用——搜索知识
AI Agent 需要了解"这个项目的 Cookie 管理方式",调用 asd_search({ query: "cookie management pattern", mode: "auto" }):
McpServer._handleToolCall('asd_search', {query, mode})
→ _gatewayGate():搜索是只读操作,不在 TOOL_GATEWAY_MAP 中,直接放行
→ _resolveHandler():映射到 consolidated.consolidatedSearch()
→ consolidatedSearch():mode='auto' 路由到 searchHandlers.search()
→ SearchEngine:三路召回 + RRF 融合 + 三级重排
→ 返回 Top-5 Recipe,序列化为 JSON
← Agent 获得精准的 Cookie 管理模式描述搜索结果经过通道 A/B 已经推送的知识不会重复——因为 Agent 已经在上下文中看到了 Top 15 规则,搜索目的是获取更深入的、不在 Top 15 中的知识。
场景 4:Mirror 同步
用户同时使用 Cursor 和 Trae。.cursor/ 下的规则通过正常交付生成后,执行 asd mirror:
→ 检测 .cursor/rules/alembic-* 文件(6 个)
→ 复制到 .trae/rules/ (保持文件名不变)
→ 检测 .cursor/skills/alembic-* 目录(3 个)
→ 复制到 .trae/skills/
→ 完成。用户在 Trae 中获得相同的知识覆盖权衡与替代方案
为什么不只用 MCP 按需查询
纯 MCP 模式的问题在于冷启动——Agent 首次对话时不知道搜索什么。通道 A 的 15 条 alwaysApply 规则解决了这个问题:即使 Agent 从不调用 asd_search,它也遵守了项目的核心约束。
实际行为是两种模式的互补:通道 A/B/F 提供"基线知识"(最重要的 20-30 条),MCP 搜索提供"长尾知识"(剩余的几百条)。基线知识保证 AI 不犯低级错误,搜索补充具体场景的深度信息。
为什么不只用文件推送
纯推送模式的问题在于规模限制。500 条 Recipe 全部推送进 IDE 文件,通道 A 就需要 50,000+ token——远超 AI 的上下文窗口容量。Token 预算的存在意味着推送必须筛选和压缩,大量知识无法通过推送覆盖。
MCP 搜索没有这个限制——它按需获取,搜索结果通常 5-10 条,token 消耗可控。
六通道 vs 更少通道
为什么不合并成三个通道(规则 · 技能 · 指令)?因为 IDE 的文件加载粒度不同:
- 通道 A(alwaysApply)和通道 B(按需加载)的区别不是内容格式,而是加载策略。合并它们意味着要么所有规则都 alwaysApply(浪费上下文),要么都按需加载(核心约束可能被遗漏)。
- 通道 C(技能)和通道 D(文档)的区别是来源和更新频率——技能来自 Alembic 管理的 SKILL.md,文档来自 Recipe 中的 dev-document 类型。它们的同步逻辑不同。
六通道的复杂度是真实的维护成本。但每个通道解决了一个具体的交付问题,合并任何两个都会丢失重要的区分能力。
小结
MCP 协议和六通道交付是 Alembic 知识价值链的最后一环——知识从数据库到达 AI 的"最后一公里":
- MCP Server 注册 18 个工具,通过 stdio 传输服务 Cursor / VS Code / Claude Code,Gateway 四阶段管线保证安全和审计
- 六通道交付把知识推送到 IDE 原生文件——通道 A 的 15 条 alwaysApply 规则保证冷启动不犯错,通道 B 的主题规则按需加载,通道 F 的 Agent 指令覆盖非 Cursor IDE
- KnowledgeCompressor 在 800 token 的预算内压缩规则为一行式表述,排名得分决定谁进入 Top 15
- FileProtection 保护用户文件不被覆盖,标记边界注入让 Alembic 和用户内容和平共存
- Mirror 让 .cursor/ 的知识资产跨 IDE 复用
两种模式互补:推送提供基线知识(核心约束 · 高频模式),MCP 搜索提供长尾知识(特定场景 · 深度细节)。知识库的几百条 Recipe 通过这两条路径,最终在每次 AI 对话中发挥价值。