Search — 混合检索与智能排序
三模式统合搜索 + 七信号加权排序,让知识在正确的时机被找到。
问题场景
用户问 AI:"项目里网络请求怎么写?" AI 需要从知识库中找到最相关的 Recipe。但 "网络请求" 可能匹配到:
@network-layer-pattern(核心网络层架构,高度相关)@api-timeout-config(超时配置,部分相关)@error-handling-retry(重试策略,间接相关)@url-builder-pattern(URL 构建,弱相关)
关键词搜索可以找到包含 "网络" 的 Recipe,但无法理解 "怎么写" 意味着要看架构模式而非配置细节。语义搜索能理解意图,但可能在关键词完全匹配时反而排名不高。
核心问题:如何在关键词精确度和语义理解力之间取得平衡?
还有一个容易忽略的问题:即使找到了相关的 Recipe,排在第一位的就一定是最好的吗?一条 Recipe 可能相关度极高但已经过时;另一条稍微不那么相关但被团队高频使用、质量评分很高。找到知识只是第一步,排好知识才是真正的挑战。
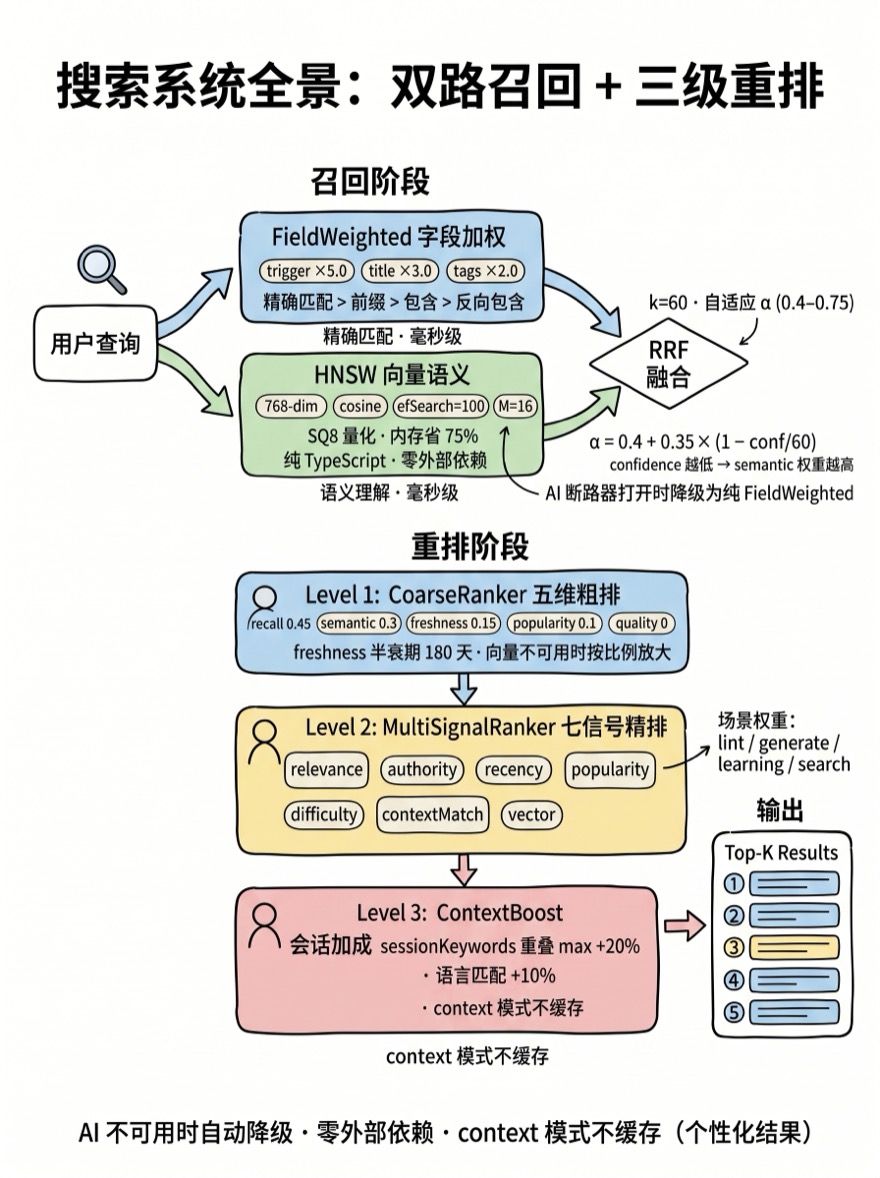
设计决策
三模式统合
Alembic 的搜索引擎提供五种模式(auto、keyword、weighted、semantic、context),但核心设计思想是两种召回策略的统合:
| 策略 | 强项 | 弱项 |
|---|---|---|
| 字段加权 | 精确匹配“dispatch_sync”一定能找到,trigger/title 高权重命中 | “网络请求”找不到 “HTTP call” |
| 向量语义 | “网络请求”能匹配到 “HTTP call” | “dispatch_sync”精确匹配时反而分数不高 |
两种策略各有盲区——只用一种永远有漏洞。Alembic 用 RRF(Reciprocal Rank Fusion) 把两种策略的排名融合为一个统一分数:
// lib/service/search/HybridRetriever.ts
// RRF 融合公式
RRF_score = Σ(i ∈ {dense, sparse}) alpha_i × 1 / (k + rank_i)
// k = 60(融合平滑系数)
// alpha = 自适应(0.4–0.75,根据 confidence 动态调整)RRF 的优雅之处在于它只用排名,不用分数。字段加权的分数范围可能是 0–15,向量相似度的范围是 0–1——两者直接相加毫无意义。但排名是可比的:字段加权排第 1 + 向量排第 3 = 融合后排名很高。
例:
Recipe A: Weighted rank 1, Vector rank 5
α = 0.6 (某 confidence 下)
RRF = α × 1/(60+1) + (1-α) × 1/(60+5)
= 0.6/61 + 0.4/65
≈ 0.0098 + 0.0062 = 0.0160
Recipe B: Weighted rank 10, Vector rank 1
RRF = α × 1/(60+1) + (1-α) × 1/(60+10)
= 0.6/61 + 0.4/70
≈ 0.0098 + 0.0057 = 0.0155
Recipe A > B:两路都排前列 > 单路极好auto 模式是默认模式——它同时执行 FieldWeighted 和向量搜索,用 RRF 融合结果。关键创新是自适应 alpha:融合权重不再固定,而是根据 FieldWeighted 搜索的 confidence 动态调整。confidence 越低(关键词越不确定),semantic 权重越高:
| confidence | α | 含义 |
|---|---|---|
| 0(完全不确定) | 0.75 | 语义主导 |
| 30(中等) | 0.575 | 趋于均衡 |
| 55(较高) | 0.42 | 关键词主导 |
| ≥60 | 跳过 semantic | 纯关键词 |
如果向量服务不可用(AI 断路器打开),自动降级为纯 FieldWeighted,搜索不会中断。
查询路由:何时跳过语义搜索
真实性能测试揭示了一个关键事实:语义搜索的 99.5% 时间花在 Embedding API 调用上(2–22 秒不等),HNSW 图搜索本身只需 8–19ms。这意味着——是否调用 embed 是性能的生死线。
对于 @video-player-reuse 这样的精确查询,weighted 用 40ms 就能以 12.98 分精确命中正确条目。语义搜索花了 22 秒,反而返回了错误结果(VideoPlayerView 响应式状态管理 排在了正确答案 VideoPlayerManager 单例播放器复用模式 前面)。问题是:auto 模式无差别地对所有查询都调用 embed,白白浪费了等待时间。
解决方案是 Weighted-First + Confidence Gate——先执行 weighted 搜索(~40ms),根据结果的"置信度"决定是否值得再等 embed。同时,当决定走语义分支时,融合权重 alpha 根据 confidence 自适应调整——关键词越不确定,semantic 权重越高:

// SearchEngine.ts — auto 模式路由逻辑
const scorerItems = getScorerResults(); // ~40ms
const confidence = computeWeightedConfidence(query, scorerItems);
if (confidence >= 60) {
// weighted 已经很有把握 → 跳过 embed,直接返回
results = scorerItems;
actualMode = 'auto(weighted-only)';
} else {
// weighted 不确定 → 调用 embed 做 RRF 融合
// 自适应 alpha:confidence 越低,semantic 权重越高
const alpha = 0.4 + (0.75 - 0.4) * (1 - confidence / 60);
const rrfResults = await vectorService.hybridSearch(query, { alpha });
// ...
}置信度由五个正向信号叠加,三个负向信号抑制:
| 信号 | 效果 | 逻辑 |
|---|---|---|
| Title/Trigger 精确匹配 | +95 | Top-1 的 title 或 trigger 包含查询原文 |
| CamelCase 类名识别 | +75 | 查询像 NetworkClient,且 Top-1 分数远超 Top-2 |
| 分数断崖 | +60 | Top-1 与 Top-2 分差 > 2 倍(一枝独秀) |
| 代码术语识别 | +50 | 查询包含下划线/点号/驼峰标记(代码符号) |
| 短查询高分 | +40 | 查询 ≤ 3 token 且 Top-1 得分 > 5.0 |
| 中文疑问句 | 置零 | 包含"如何/怎样/什么/为什么/怎么" → 一定走语义 |
| 英文疑问句 | 置零 | 以 how/what/why/when 开头 → 一定走语义 |
| 多词短语 | 置零 | 超过 3 个词 → 倾向语义理解 |
实际路由效果(BiliDili 知识库,17 组测试):
"WBISigner" → conf 70, skip (40ms)
"BaseViewController" → conf 80, skip (35ms)
"@video-player-reuse" → conf 95, skip (38ms)
"Cookie持久化" → conf 35, α=0.55 (340ms)
"数据竞争怎么避免" → conf 0, α=0.75 (420ms)
"网络请求怎么做" → conf 0, α=0.75 (380ms)
"how to make API calls" → conf 0, α=0.75 (450ms)与云端 Embedding API(2–22 秒延迟)不同,配合本地 Ollama 模型(qwen3-embedding),语义搜索延迟降至 200–500ms,使得 auto 模式的语义分支也变得实用——不再是 "10 秒 vs 40ms" 的取舍,而是 "400ms vs 40ms" 的微小代价换取更好的语义理解。
路由准确率在 BiliDili 知识库的 17 组测试查询中达到 100%——所有精确查询被正确跳过,所有概念性查询走了语义融合。自适应 alpha 确保了融合后的 Top-1 全部正确命中预期条目。
FieldWeighted 字段加权
知识库不是一堆无结构的文本——每条 Recipe 有 trigger、title、tags、description、content、language、category 等字段。不同字段的匹配意义不同:
| 字段 | 权重 | 匹配含义 |
|---|---|---|
| trigger | 5.0 | 唯一标识符,匹配即精确命中 |
| title | 3.0 | 主题匹配,高度相关 |
| tags | 2.0 | 分类匹配,领域相关 |
| description | 1.5 | 描述匹配,IDF 加权 |
| content | 1.0 | 内容匹配,IDF 加权 |
| facets | 0.5 | language/category 精确匹配 |
传统 BM25 的做法是把所有字段拼接为一段文本,然后整体计分。但对于结构化知识库来说这行不通——BM25 把字段拼接后做 tokenize 去重,导致 TF(词频)永远为 1,BM25F 的字段 boost 完全失效。因此 Alembic 放弃了 BM25,改用 FieldWeightedScorer 独立字段评分策略。
FieldWeightedScorer 采用独立评分策略:对每个字段单独计算匹配分,再加权合并。trigger 和 title 使用精确匹配 + token 重叠双重评分,description 和 content 使用 IDF 加权的 token 重叠:
// lib/service/search/FieldWeightedScorer.ts
// trigger 评分:精确匹配 > 前缀匹配 > 包含匹配
function _stringMatchScore(query: string, field: string): number {
if (field === query) { return 1.0; } // 精确相等
if (field.startsWith(query)) { return 0.7; } // 前缀匹配
if (field.includes(query)) { return 0.5; } // 包含匹配
if (query.length > 3 && query.includes(field)) { return 0.3; } // 反向包含
return 0;
}
// description/content:IDF 加权 token 重叠
// IDF(term) = log((N - df + 0.5) / (df + 0.5))
// 越稀有的词匹配分越高——"dispatch_sync" 比 "使用" 值钱得多facets 评分针对 language、category、knowledgeType 做精确匹配——当查询包含 swift 时,Swift 语言的 Recipe 获得额外 0.5 分、同 category 加 0.25、同 knowledgeType 加 0.25。这让搜索结果自然向用户当前的技术上下文聚拢。
七信号加权排序
召回阶段解决的是“找到相关内容”——但相关性只是排序的维度之一。MultiSignalRanker 用七个信号对候选结果进行精排:
| 信号 | 计算方式 | 范围 | 语义 |
|---|---|---|---|
| Relevance | 召回分 + trigger/title/content 匹配加成 | [0, 1] | 与查询的相关度 |
| Authority | qualityScore × 0.5 + authorityScore × 0.3 + usageCount × 0.2 | [0, 1] | 知识的可靠度 |
| Recency | [0, 1] | 内容新鲜度 | |
| Popularity | [0, 1] | 使用热度 | |
| Difficulty | [0, 1] | 难度匹配度 | |
| ContextMatch | 语言 +0.4、类别 +0.25、标签重叠 +0.25 | [0, 1] | 上下文匹配度 |
| Vector | 向量空间余弦相似度 | [0, 1] | 语义相似度 |
七个信号归一化到 [0, 1] 后,根据场景分配不同权重。同一条 Recipe,在 lint 场景和 learning 场景中的排名可能完全不同:
// lib/service/search/MultiSignalRanker.ts
const SCENARIO_WEIGHTS = {
lint: { // Guard 检测需要精确规则
relevance: 0.35, authority: 0.20, recency: 0.15,
popularity: 0.10, difficulty: 0.05, contextMatch: 0.05, vector: 0.10,
},
generate: { // 代码生成需要热门且可靠的模式
relevance: 0.25, authority: 0.15, recency: 0.10,
popularity: 0.15, difficulty: 0.10, contextMatch: 0.10, vector: 0.15,
},
learning: { // 学习需要难度适配和上下文匹配
relevance: 0.15, authority: 0.10, recency: 0.05,
popularity: 0.10, difficulty: 0.25, contextMatch: 0.20, vector: 0.15,
},
search: { // 通用搜索偏向语义理解
relevance: 0.20, authority: 0.15, recency: 0.10,
popularity: 0.10, difficulty: 0.05, contextMatch: 0.10, vector: 0.30,
},
};对比两个极端场景:
- lint 场景:Guard 需要找到精确的编码规则。此时 relevance(0.35)远远领先——"这条 Recipe 是否准确描述了当前违规"比"它是否热门"重要得多。
- learning 场景:用户正在学习设计模式。此时 difficulty(0.25)和 contextMatch(0.20)成为主角——一条 expert 级别的 Recipe 对 beginner 毫无帮助,即使它相关度最高。
最终的 rankerScore 是七个信号的加权和:
其中
搜索管线
三级重排架构
RRF 融合给出了一个初步排名。但初步排名不够精确——相关度只是排名依据的冰山一角。Alembic 用三级重排管线逐步精炼结果:
召回 (FieldWeighted + Vector, RRF 融合)
│ 3× 过采样
│
├── Level 1: CoarseRanker 粗排 ← 五维
│ recall 0.45 + semantic 0.3 + freshness 0.15 + popularity 0.1
│
├── Level 2: MultiSignalRanker 精排 ← 七信号
│ 场景化权重 × 归一化信号
│
└── Level 3: ContextBoost 会话加成 ← 个性化
会话关键词重叠 +20% · 语言匹配 +10%
│
截断 → Top-K 返回Level 1: CoarseRanker 五维粗排
快速的工程化排序。五个维度加权合成:
| 维度 | 默认权重 | 数据源 |
|---|---|---|
| recall | 0.45 | FieldWeighted 召回分 |
| semantic | 0.30 | 向量相似度 |
| quality | 0(可调) | 内容完整性评分 |
| freshness | 0.15 | 时间衰减(半衰期 180 天) |
| popularity | 0.10 |
注意 CoarseRanker 的 freshness 半衰期是 180 天——比 MultiSignalRanker 的 90 天长一倍。粗排阶段不希望新鲜度过度惩罚经典 Recipe。
当向量服务不可用时,semantic 维度权重自动归零,其他维度按比例放大以保持总权重为 1.0。例如 recall 从 0.45 变为 0.649、freshness 从 0.15 变为 0.214——系统无缝降级,不需要手动切换配置。
Level 2: MultiSignalRanker 七信号精排(前文已详述)
Level 3: ContextBoost 会话加成
最后一级利用会话历史做个性化加成。收集当前会话中所有消息的 token 集合(sessionKeywords),计算和候选 Recipe 的重叠度:
// lib/service/search/contextBoost.ts
boost = 0;
overlap = count(queryToken ∈ sessionKeywords);
if (overlap > 0) {
boost += 0.2 × min(overlap / 5, 1.0); // 最多 +20%
}
if (context.language === item.language) {
boost += 0.1; // 语言匹配 +10%
}
contextScore = baseScore × (1 + boost); // 最多 +30%会话加成最多提升 30%——足以让相关结果上浮两三位,但不会颠覆整体排名。这保证了加成是"微调"而不是"覆盖"。
含 sessionHistory 的搜索不进入缓存——因为同一个 query 在不同会话上下文中的排序应该不同。
中英文混合分词
整个搜索系统的基石是分词器。知识库是多语言的——Recipe 的 title 可能是中文("网络层架构模式"),content 包含英文代码(URLSession),tags 混合中英文。tokenizer.ts 实现了三种策略的组合:
camelCase 拆分:URLSession → ["url", "session"],PascalCase → ["pascal", "case"]。这让搜索 "session" 时能命中 URLSession。
中文 bigram + 完整片段:
"网络请求" → ["网", "络", "网络", "络请", "请求", "网络请求"]单字+bigram+完整片段的三级组合确保了短查询和长查询都有召回能力。中文停用词(~160 个:的、了、着、过……)和英文停用词(~70 个:the、is、are……)被过滤,避免高频无意义词干扰评分。
向量引擎
纯 JavaScript HNSW
Alembic 是一个通过 npm install 分发的 CLI 工具。所有依赖必须是纯 JavaScript——不能要求用户编译 C++ 扩展、安装 CUDA 驱动或配置 Python 环境。这排除了 FAISS、Annoy、Milvus 等常见向量数据库。
HnswIndex 是一个完整的 HNSW(Hierarchical Navigable Small World)近似最近邻索引,纯 TypeScript 实现,零外部依赖。
核心参数:
| 参数 | 值 | 含义 |
|---|---|---|
| 向量维度 | 768 | OpenAI/Gemini 标准 embedding 维度 |
| M | 16 | 每层最大邻居数 |
| M0 | 32 | Layer 0 最大邻居数( |
| efConstruction | 200 | 构建时搜索宽度 |
| efSearch | 100 | 查询时搜索宽度 |
| 层级采样因子 |
HNSW 的多层图结构:
Level 3: [A] ─── [B] ← 极少节点,跨度大
Level 2: [A] ─ [C] ─ [B] ─ [D] ← 更多节点
Level 1: [A]-[E]-[C]-[F]-[B]-[G]-[D]-[H] ← 密集连接
Level 0: [A][E][I][C][J][F][K][B][G][L][D][M][H] ← 所有节点每个节点的层级由几何分布随机决定:
绝大多数节点只在 Level 0,少数节点出现在高层。搜索时从最高层的入口节点开始贪心下降——高层跨度大、快速逼近目标区域;低层密度高、精确定位最近邻。这实现了
查询性能:对于 1000 条 Recipe(知识库的典型规模),单次向量搜索延迟在 1–10ms——远快于任何外部向量数据库的网络往返。
SQ8 标量量化
当知识库规模超过 3000 条时,768 维 Float32 向量的内存开销变得不可忽视:ScalarQuantizer 把每个维度从 Float32(4 字节)压缩为 Uint8(1 字节),内存节省 75%:
量化是 per-dimension 的——先从一批向量中统计每个维度的 min/max,然后线性缩放到 [0, 255]。这是最简单的量化方案,但对于余弦相似度搜索来说 Recall 保留 > 95%,足够用于知识库场景。
量化后搜索采用 2-Pass 策略:先用 Uint8 整数运算粗排(微秒级),再用原始 Float32 精排 Top-K。粗排大幅减少精排的候选集,整体速度提升显著。
持久化与WAL
向量索引不能每次启动都重建——构建一次需要调用 embedding API,这有 Token 成本。HnswVectorAdapter 实现了二进制持久化(.asvec 格式)+ WAL(Write-Ahead Log)双重保障:
┌────────────────────────────────┐
│ HnswVectorAdapter │
│ ┌────────────┐ ┌──────────┐ │
│ │ HnswIndex │ │ SQ8 │ │
│ │ (图结构) │ │ (量化器) │ │
│ └────────────┘ └──────────┘ │
│ ┌────────────┐ ┌──────────┐ │
│ │ .asvec │ │ WAL │ │
│ │ (二进制) │ │ (操作日志)│ │
│ └────────────┘ └──────────┘ │
└────────────────────────────────┘每次 upsert 先追写 WAL,然后标记 dirty。实际的二进制持久化(.asvec)通过 2 秒防抖定时器延迟执行——避免频繁写磁盘。如果进程崩溃,重启时回放 WAL 恢复未刷盘的修改,数据不会丢失。
BatchEmbedder:批量 Embedding
知识库冷启动时需要对所有 Recipe 生成向量。逐条调用 embedding API 极慢——100 条 Recipe × 300ms/条 = 30 秒。BatchEmbedder 把文本按 32 条一批打包,最多 2 批并发:
串行: 100 条 × 300ms = 30s
批量: 100 条 / 32 = 4 批 × 300ms / 2 并发 ≈ 0.6s
加速: ~50×// lib/infrastructure/vector/BatchEmbedder.ts
constructor(aiProvider, options: {
batchSize: 32, // 每批文本数
maxConcurrency: 2, // 最多并发批次
})降级策略分三级:
- 批量 API(
embed(texts[]))——最快,OpenAI 和 Gemini 原生支持 - 单条降级——如果批量 API 返回格式不符,退化为逐条调用
- 异常容错——某一批失败不影响其他批,继续处理
Embedding 服务还有断路器保护:连续 3 次失败后打开断路器,60 秒内所有 embed 请求自动短路返回 null。搜索系统感知到向量不可用后,自动降级为纯关键词搜索。
索引构建管线
向量搜索的前提是索引存在。IndexingPipeline 负责从 Recipe 文件构建向量索引,分五个阶段:
1. 扫描 (Scan)
遍历 recipes/ 目录 → 计算 sourceHash 检测变更
│
2. 分块 (Chunk)
Chunker v2 自动选择策略(AST / section / fixed)
│
3. 富化 (Enrich) [可选]
ContextualEnricher 为每个 chunk 生成上下文前缀
│
4. 嵌入 (Embed)
BatchEmbedder (32 batch × 2 concurrency)
│
5. 写入 (Upsert)
VectorStore.batchUpsert() → HnswIndex增量检测:每次构建前对文件内容计算 SHA256 hash。如果某条 Recipe 的 hash 与上次构建时一致,跳过 embed 和 upsert,只处理有变化的条目。这让日常增量更新几乎零成本。
上下文富化(ContextualEnricher)是一个基于 Anthropic "Contextual Retrieval" 论文的可选优化。它对每个 chunk 生成 50–100 token 的上下文描述前缀,让 chunk 在被 embedding 时保留文档层面的语义。论文数据显示,配合 reranking 可以将检索失败率降低 35–67%。
为了控制成本,富化使用轻量模型(Haiku 4.5/Gemini Flash),并利用 Prompt Caching——同一文档的多个 chunk 共享 system prompt 缓存,后续 chunk 的 Token 成本降至首个的 10%。
运行时行为
以四个场景展示搜索系统的实际工作方式:
场景 1:通用搜索
用户查询: "网络请求怎么写"
模式: auto
→ FieldWeighted 召回:
匹配 title "网络层架构模式" → score 2.8
匹配 tags ["网络", "HTTP"] → score 1.5
→ Vector 召回:
语义最近邻 "HTTP request pattern" → similarity 0.87
"API timeout config" → similarity 0.72
→ RRF 融合 (k=60):
"@network-layer-pattern": rank 1 + rank 2 → RRF 0.0161
"@api-timeout-config": rank 3 + rank 4 → RRF 0.0155
→ CoarseRanker 粗排:
"@network-layer-pattern" quality 高、freshness 高 → 维持第 1
→ MultiSignalRanker 精排 (search 权重):
vector 0.30 占大头 → 语义最相关的确认第 1 位
→ 返回 Top-5场景 2:Guard lint 搜索
Guard 需要检查 "dispatch_sync" 相关规则
模式: auto, 场景: lint
→ FieldWeighted: trigger "@swift-no-main-thread-sync" 精确命中 → score 5.0
→ MultiSignalRanker (lint 权重):
relevance 0.35 → 这条规则完全匹配
authority 0.20 → qualityScore 95 (高)
→ 排名第 1,无争议场景 3:会话上下文搜索
会话历史中已讨论 "SwiftUI", "MVVM", "ObservableObject"
当前查询: "数据绑定"
模式: context
→ 常规搜索返回 Top-10
→ ContextBoost:
sessionKeywords = {"swiftui", "mvvm", "observable", ...}
"@swiftui-data-binding" 包含 "swiftui" tag → overlap=2 → boost +8%
"@swiftui-data-binding" language=swift 匹配 → boost +10%
总加成 +18% → 从第 4 位升到第 1 位
→ 不缓存(个性化结果)场景 4:学习场景
初学者搜索 "设计模式"
模式: auto, 场景: learning, userLevel: beginner
→ 召回 15 条相关 Recipe
→ MultiSignalRanker (learning 权重):
difficulty 0.25 → 权重最高
"@simple-factory-pattern" difficulty=beginner → diff=0 → score 1.0
"@abstract-factory-pattern" difficulty=expert → diff=3 → score 0.1
contextMatch 0.20 → 次高
与用户语言/类别匹配的 Recipe 额外加分
→ 结果: beginner 级 Recipe 排在前面
即使 expert 级的相关度更高(relevance 更高),
difficulty 权重压制了它真实性能剖析
以下数据来自 BiliDili 项目知识库(~50 条 Recipe,Gemini gemini-embedding-001 768d)的 15 组实际搜索测试。
延迟分解:
| 阶段 | 云端 API (Gemini) | 本地模型 (Ollama) |
|---|---|---|
| FieldWeighted 全流程 | 35–40ms | 35–40ms |
| Embedding 调用 | 2.3–22.3s(中位 ~6s) | 180–300ms |
| HNSW 图搜索 | 8–19ms | 8–19ms |
| RRF 融合 + 元数据补全 | 5–15ms | 5–15ms |
| 总延迟(auto + semantic) | 2.4–22.5s | 230–380ms |
Alembic 支持 Embedding 双轨配置——LLM 和 Embedding 可以使用不同的 Provider。典型配置是 LLM 走云端 Gemini(强推理),Embedding 走本地 Ollama + qwen3-embedding:0.6b(低延迟零成本)。这让语义搜索摆脱了对云端 API 的延迟依赖——HNSW 在 ~50 条规模上几乎零开销,Embedding 本地化后延迟从秒级降到毫秒级。云端 API 仍然可用作后备,断路器打开时自动降级为纯 weighted。
三种模式在不同查询类型上的真实表现:
| 查询类型 | weighted | semantic | auto (RRF) |
|---|---|---|---|
精确术语 NetworkClient | ✅ 精确命中,40ms | ⚠️ 正确但 ~6s | = weighted 排序,~10s |
Trigger @video-player-reuse | ✅ 12.98 分爆杀 | ❌ 返回错误条目 | = weighted 排序,~7s |
| 自然语言 "如何在列表页复用播放器" | ✅ 竟然也命中 | ⚠️ 语义相近但不同条目 | = weighted 排序 |
| 概念查询 "启动阶段应该做什么初始化" | ✅ 命中"两阶段启动" | ✅ 额外找到 weighted 没有的 | 融合效果最好 |
两个意外发现:
- weighted 搜索表现超预期。自然语言查询"如何在列表页复用播放器",weighted 靠中文 bigram tokenize 匹配"播放器"+"复用"成功命中正确条目(
VideoPlayerManager 单例播放器复用模式),而 semantic 反而返回了语义相近但不同的VideoPlayerView 响应式状态管理。 - semantic 搜索的独有价值是语义泛化。在"怎样保护接口请求的并发安全"查询中,semantic 找到了"AuthMiddleware 并发安全认证"和"RequestDeduplicator 并发请求去重"——这些条目的 title/trigger 中不包含查询的任何原始词汇,weighted 完全触及不到。这就是向量搜索存在的意义。
自适应 alpha 的效果:早期版本使用固定权重 0.6:0.4 偏向 sparse,导致 semantic 信号几乎被淹没。引入自适应 alpha 后,低 confidence 查询的 semantic 权重最高可达 0.75,修复了此前 Cookie持久化(概念查询)和 数据竞争怎么避免(疑问句)等场景下 Top-1 排序错误的问题。17 组测试中所有查询的 Top-1 均正确命中。
权衡与替代方案
为什么不用 Elasticsearch
Elasticsearch 是搜索领域的标准方案,支持 BM25、向量搜索、字段加权、聚合分析。Alembic 不用它有两个原因:
- 安装成本。Alembic 通过
npm install -g alembic安装,整个工具是一个 Node.js package。如果依赖 Elasticsearch,用户还需要安装 Java(ES 的运行时)、下载 ES 二进制包、配置并启动 ES 服务——这对于一个 CLI 工具来说成本不可接受。 - 规模不匹配。知识库的典型规模是 50–500 条 Recipe。ES 为百万级文档优化的分片和集群机制,对这个规模完全多余。纯内存的 FieldWeighted + HNSW 在这个量级上的延迟(1–10ms)比 ES 的 HTTP 往返(50–200ms)快一到两个数量级。
为什么不纯用向量搜索
向量搜索能理解语义,但有三个致命弱点:
- 关键词精确匹配差。用户输入
@swift-no-main-thread-sync时期望 trigger 精确命中。向量搜索把这个字符串编码为 768 维向量后,可能和@swift-no-force-cast的向量距离很近(都是 Swift 安全规则),但用户要的是精确这一条。实测数据:trigger@video-player-reuse在 weighted 中以 12.98 分精确命中,在 semantic 中排第一的却是另一个条目。 - 延迟不可控(云端 API 场景)。实测云端 Embedding API 延迟从 2.3 秒到 22.3 秒不等,中位数约 6 秒——而 HNSW 图搜索本身只需 8–19ms。不过,Alembic 的 Embedding 双轨配置支持使用本地模型(如 Ollama + qwen3-embedding:0.6b),延迟降至 180–300ms,使语义搜索成本变得可接受。
- 依赖 AI 服务。向量搜索的前提是 embedding API 可用。断路器打开、网络故障、API Key 过期时,纯向量搜索完全瘫痪。实测中偶发
fetch failed导致搜索降级耗时高达 40 秒。FieldWeighted 是纯本地计算,零外部依赖——它是搜索系统的安全兜底。
RRF 融合让两者互补:关键词精确匹配时 FieldWeighted 得分碾压,语义模糊查询时向量搜索补位。
七信号排序的调参成本
七个信号 × 五种场景 = 35 个权重参数。这看起来是一个调参噩梦。实际上,这些权重不需要精确优化:
- 信号归一化到 [0, 1]:每个信号的取值范围一致,权重直接反映"这个信号值多少钱"。
- 场景语义清晰:lint 场景需要精确规则(relevance 高)、learning 场景需要难度匹配(difficulty 高)——这些不需要 A/B 测试,根据产品直觉就能定义合理的初始值。
- CoarseRanker 兜底:即使 MultiSignalRanker 的权重不够理想,Level 2 的粗排已经提供了一个合理的基准排序。精排权重的偏差最多影响前几位的相对顺序,不会导致完全不相关的结果上浮。
真正需要关注的是两个参数:RRF 的
小结
Search 的设计可以归结为三个核心原则:
- 融合优于单一。没有哪种搜索策略能覆盖所有场景——字段加权精确但不理解语义,向量理解语义但不擅长精确匹配。RRF 用排名取代分数做融合,优雅地回避了不同策略之间分数不可比的问题。自适应 alpha 更进一步——根据关键词搜索的 confidence 动态调整融合权重,而非固定比例。
- 路由优于蛮力。不是每次搜索都需要调用 Embedding——Weighted-First Confidence Gate 用 40ms 的预判省去了大多数场景下的 embed 等待。配合本地 Embedding 模型,即使走语义分支的延迟也降到 400ms 以内。
- 排序即理解。七信号加权排序把"找到"变成了"找对"——同样相关的两条 Recipe,质量高的优先、新鲜的优先、与当前上下文匹配的优先。场景动态权重让排序策略适应不同的使用意图。
- Prime 语义增强。MCP task prime 的搜索管线(PrimeSearchPipeline)在 auto + keyword 之外,始终为主查询追加一路
semantic搜索参与 RRF 融合。即使 auto 模式因 confidence 高而跳过语义,Prime 的结果中仍保证有语义召回兜底——概念性查询不会因为 confidence gate 被意外截断。
下一章我们将深入向量引擎的内部——从 HNSW 图算法的每一步到 SQ8 量化的数学公式、从 .asvec 二进制格式的每一个字节到 AST 感知分块的语法树遍历。
下一章