KnowledgeEntry — 一个实体表达所有知识
代码模式、架构决策、最佳实践、项目约定 — 一个统一实体承载所有知识类型。
前置阅读:ch05 代码理解(AST 分析产出的结构信息是本章知识实体的输入源)
问题场景
一个团队的编码知识有很多种形态:一段错误处理的固定写法是"代码模式",选择 Repository 模式而非直接访问数据库是"架构决策",变量命名用 camelCase 是"项目约定"。如果为每种知识类型定义一个独立的数据模型,你会得到 Pattern、Decision、Convention、Practice 四个类,各自有一套 CRUD,各自有一套搜索,各自有一套生命周期 —— 然后发现它们 80% 的字段是重复的。
核心问题:如何在避免类型爆炸的同时,保留每种知识类型的语义区分?
设计决策
方案对比:继承 vs 统一实体
最直觉的方案是面向对象继承——定义一个 BaseKnowledge 基类,然后为每种类型派生子类:
BaseKnowledge
├── Pattern (代码模式)
├── Decision (架构决策)
├── Convention (编码约定)
└── Practice (最佳实践)这个方案在教科书里很优雅,但在知识引擎的实际场景中会产生三个棘手的问题:
- 搜索需要 UNION:用户输入一个关键词,系统要同时搜索四张表,然后合并排序。搜索是知识引擎最高频的操作——每次 AI 请求都会触发至少一次搜索。
- 生命周期复制:四种类型都需要 pending → active → deprecated 的状态机、都需要审核流程、都需要衰退检测。你不得不在基类中实现,但基类的字段又不完全适用于所有子类。
- 分类边界模糊:一条"所有 HTTP 请求必须通过
NetworkKit封装"的知识,它是 Convention 还是 Pattern?如果答案取决于你怎么看待它,那分类本身就不该是类型层面的硬约束。
Alembic 选择了另一条路:统一实体 + 分类标签。
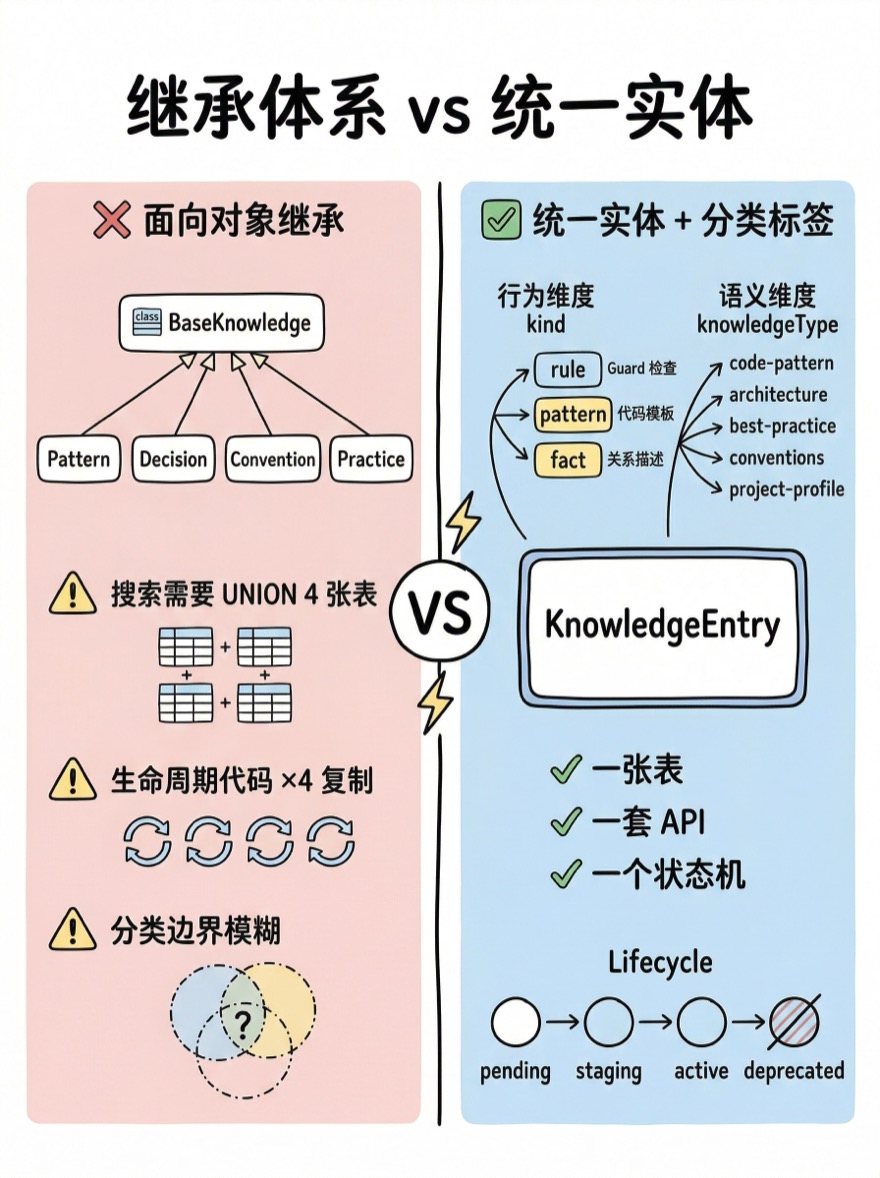
统一 KnowledgeEntry
所有知识——无论是代码模式、架构决策还是项目约定——都是一个 KnowledgeEntry 实例。一张表、一套 API、一套生命周期。语义区分通过两个分类字段实现:
kind:行为维度——这条知识被怎样消费。rule(Guard 可以用它做代码检查)、pattern(作为代码模板交付给 AI)、fact(只读的关系描述)。knowledgeType:语义维度——这条知识描述的是什么。code-pattern、architecture、best-practice、project-profile、conventions等。
kind 不需要手工指定——系统根据 knowledgeType 自动推断:
// lib/domain/knowledge/Lifecycle.ts
export function inferKind(knowledgeType: string): string {
switch (knowledgeType) {
case 'code-standard':
case 'code-style':
case 'best-practice':
case 'boundary-constraint':
return 'rule';
case 'code-pattern':
case 'architecture':
case 'solution':
case 'anti-pattern':
return 'pattern';
case 'code-relation':
case 'inheritance':
case 'call-chain':
case 'data-flow':
return 'fact';
default:
return 'pattern';
}
}这个映射表的逻辑很清晰:如果一条知识描述的是"必须怎么做"(标准、约束),它天然是 rule;如果描述的是"一种做法"(模式、架构),它是 pattern;如果描述的是"一种关系"(调用链、数据流),它是 fact。
这个设计的权衡是明确的:coreCode 字段对于 fact 类型的知识可能无意义,constraints.guards 对于 pattern 类型是空的。部分字段在某些 kind 下必然闲置——我们用一些字段的空间换来了架构的统一性。对于一个知识引擎来说,搜索和生命周期的统一性远比字段空间的精简性重要。
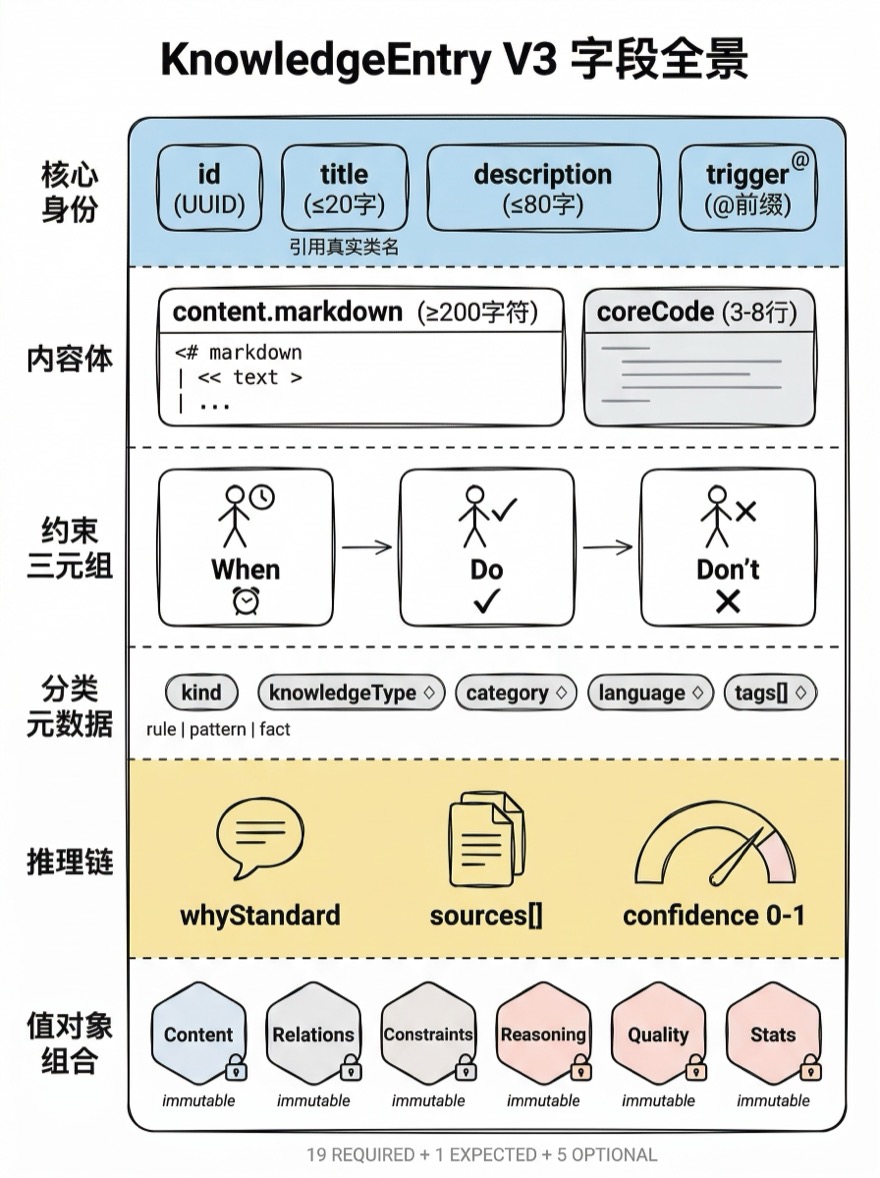
V3 字段设计
KnowledgeEntry 经历了三次大的字段重构,当前 V3 版本的字段按职责分为六层:
第一层:核心身份
| 字段 | 约束 | 用途 |
|---|---|---|
id | UUID v4,自动生成 | 全局唯一标识 |
title | 中文 ≤20 字,引用项目真实类名 | 搜索 + 去重 + 质量评分 |
description | 中文简述 ≤80 字 | 搜索结果展示 |
trigger | @ 前缀 kebab-case,全局唯一 | Cursor 交付文件标题 + 过滤键 |
title 的 20 字限制不是随意选择——它来自实际的交付场景。Cursor Rules 文件的标题行空间有限,超过 20 字的标题在 IDE 侧边栏中会被截断。同时,标题必须引用项目中真实存在的类名或模块名(比如"NetworkKit 请求封装规范"而非通用的"网络请求模式"),这是为了确保知识条目与具体项目紧密绑定。
第二层:内容体
// 内容通过值对象 Content 承载
interface ContentProps {
markdown?: string; // ≥200 字符,项目特写(含代码块 + 来源标注)
rationale?: string; // 设计原理说明
pattern?: string; // 代码片段(可选,与 markdown 二选一)
}content.markdown 是知识的主体。200 字符的下限看起来不高,但它有效地过滤掉了"一句话知识"——比如 "使用 async/await" 这种过于空泛的描述。真正有价值的知识需要上下文:为什么在这个项目里这样做?用了哪些代码来证明?这 200 字符迫使知识作者(通常是 AI Agent)提供充分的论据。
与 content.markdown 并列的是 coreCode——一段 3-8 行的纯代码骨架:
// 示例:一条 Swift 项目的 coreCode
coreCode: `let provider = CookieProviding(
storage: .keychain,
session: URLSession.shared
)
let cookies = try await provider.fetchCookies(for: url)`coreCode 的定位是"可直接复制粘贴的代码种子"。它不是完整的实现(那是 content.markdown 的职责),而是模式的骨架——3 行太短无法表达一个模式的结构,8 行以上就变成了教程。这个限制迫使知识作者提炼最核心的代码形态。
第三层:约束三元组
doClause: string; // "Use CookieProviding for all cookie operations"
dontClause: string; // "Do NOT access HTTPCookieStorage directly"
whenClause: string; // "When implementing cookie-dependent features"这三个字段构成了一条知识的"行为规范":什么时候(When)该怎么做(Do),不该怎么做(Don't)。它们被直接注入到 Cursor Rules 的 .mdc 文件中,成为 AI 编码时的实时约束。
这三个字段都要求英文,因为它们的消费方是 LLM——多数大模型在理解英文祈使句时的准确度显著高于中文。doClause 限制 60 tokens,这是 Cursor Rules 文件中单行规则的最佳长度经验值。
第四层:分类元数据
kind: string; // rule | pattern | fact(从 knowledgeType 推断)
knowledgeType: string; // code-pattern | architecture | best-practice | ...
category: string; // View | Service | Network | Storage | ...
language: string; // swift | typescript | python | ...
tags: string[]; // 自由标签 + 系统标签(dimension: / bootstrap:)category 的取值范围随项目类型变化。对于一个 Swift iOS 项目,View、Service、Model、Network 是自然的选择;对于一个 TypeScript 后端项目,Controller、Repository、Middleware 可能更合适。系统维护一个标准列表(约 30 个值),但允许非标准值——只是会在验证时产生 warning。
tags 字段有一个特殊约定:以 dimension:、bootstrap:、internal:、system: 前缀开头的标签是系统内部标签,在 API 输出时会被 sanitizeForAPI() 过滤掉。这些标签用于内部路由和统计,不应暴露给终端用户。
第五层:推理链
interface ReasoningProps {
whyStandard?: string; // "CookieProviding encapsulates the complex..."
sources?: string[]; // ["BiliDili/Modules/Network/CookieProviding.swift"]
confidence?: number; // 0.85
}reasoning 是知识的"证据链"。whyStandard 解释为什么这是标准做法——不是泛泛的"这是最佳实践",而是结合项目上下文的具体论述。sources 是非空的文件路径数组,指向知识提取的原始来源。confidence 是 0-1 的置信度分数,由 AI Agent 在提取时自评,后续由 QualityScorer 校准。
置信度为什么用 0-1 而非百分制?因为它的语义本质是概率——"这条知识有 85% 的可能是项目级的标准做法"。概率值可以直接参与 ConfidenceRouter 的路由决策,而百分制数字需要额外的归一化步骤。
第六层:值对象组合
KnowledgeEntry 的复杂状态通过六个值对象(Value Object)管理:
content: Content; // 知识内容(markdown + rationale + steps + codeChanges)
relations: Relations; // 知识间关系(14 种关系桶)
constraints: Constraints; // 约束规则(regex guards + AST guards)
reasoning: Reasoning; // 推理链(证据 + 置信度)
quality: Quality; // 质量评分(completeness · adaptation · documentation)
stats: Stats; // 使用统计(views · adoptions · guardHits · searchHits)Stats 使用可变流式 API——increment() 直接修改当前实例并返回 this,支持链式调用:
// lib/domain/knowledge/values/Stats.ts
increment(counter: StatsCounter, delta = 1): Stats {
this[counter] += delta;
return this;
}这种设计让高频统计场景(Guard 命中、搜索命中)避免了频繁创建新对象的 GC 压力,同时通过返回 this 保持链式调用的便利性。
架构与数据流
FieldSpec:字段的唯一权威来源
Alembic 对每个字段的约束不是散落在代码各处的 if 检查,而是集中定义在一个声明式规范中——FieldSpec:
// lib/domain/knowledge/FieldSpec.ts
export const V3_FIELD_SPEC = [
{
name: 'title',
level: FieldLevel.REQUIRED,
type: 'string',
rule: '中文 ≤20 字,引用项目真实类名(不以项目名开头)',
pipeline: 'identity + dedup + search + QualityScorer(completeness 0.25)',
},
{
name: 'content.markdown',
level: FieldLevel.REQUIRED,
type: 'string',
rule: '≥200 字符的「项目特写」,含代码块+来源标注',
pipeline: 'search + Skill content + display',
},
{
name: 'doClause',
level: FieldLevel.REQUIRED,
type: 'string',
rule: '英文祈使句 ≤60 tokens,以动词开头',
pipeline: '⚠️ HARD filter dependency — missing → 0 output',
},
// ...共 19 个 REQUIRED + 1 个 EXPECTED + 5 个 OPTIONAL
];每个字段定义包含四个维度:
level:三级分类——REQUIRED(缺少立即拒绝)、EXPECTED(缺少产生 warning)、OPTIONAL(缺少不报问题)type:数据类型约束rule:人类可读的约束描述pipeline:该字段被哪些下游管线消费
pipeline 字段是 FieldSpec 独特的设计点。它的存在不是为了运行时验证,而是为了开发者理解——当你看到 doClause 的 pipeline 标注为 HARD filter dependency — missing → 0 output,你立刻知道:缺少这个字段会导致 Cursor 交付管线整条产出为零。这比文档注释更有效,因为它和字段定义放在一起,不会失同步。
FieldSpec 的消费方不只是 UnifiedValidator。它还被以下模块引用:
| 消费方 | 用途 |
|---|---|
UnifiedValidator | 运行时字段完整性检查 |
dimension-text.js | 生成 AI 提交指引中的字段描述 |
bootstrap-producer.js | 冷启动时的字段列表 |
MissionBriefingBuilder | Agent 任务简报中的提交规范 |
lifecycle.js | JSON Schema 的 required 数组生成 |
一处定义,多处消费——这是 DDD 中"领域知识不要散落在代码各处"原则的具体体现。
UnifiedValidator:三层验证链
在 V3 之前,系统有两个独立的验证器:CandidateGuardrail(验证候选提交)和 RecipeReadinessChecker(验证 Recipe 发布就绪度)。问题是两者的验证逻辑有 70% 重叠,维护两份几乎相同的代码意味着修改一个验证规则要改两个地方——而且改漏一个不会立即报错,只会在运行时产生不一致的行为。
UnifiedValidator 合并了这两个验证器,提供单一入口的三层验证:
// lib/domain/knowledge/UnifiedValidator.ts
export class UnifiedValidator {
#titles; // 已提交标题 (小写)
#codeFingerprints; // 已提交代码指纹
validate(candidate, options = {}) {
const errors = [];
const warnings = [];
const systemInjected = new Set(options.systemInjectedFields || []);
// Layer 1: 字段完整性 (基于 V3_FIELD_SPEC)
this.#checkFields(candidate, systemInjected, errors, warnings);
// Layer 2: 内容质量 (启发式检查)
this.#checkContentQuality(candidate, errors, warnings);
// Layer 3: 唯一性 (标题 + 代码指纹去重)
if (!options.skipUniqueness) {
this.#checkUniqueness(candidate, errors);
}
return { pass: errors.length === 0, errors, warnings };
}
}Layer 1(字段完整性) 遍历 V3_FIELD_SPEC 中的每个字段定义——REQUIRED 缺失产生 error,EXPECTED 缺失产生 warning,OPTIONAL 缺失不报。同时执行格式校验:content 和 reasoning 必须是对象而非字符串,kind 值必须在 rule | pattern | fact 之内,trigger 应以 @ 开头。
Layer 2(内容质量) 来自原 CandidateGuardrail 的启发式规则:
content.markdown不足 200 字符 → errorcoreCode以}、)、]开头 → error(说明截取了代码片段的末尾)title是泛型名称(如 "Singleton Pattern") → errorreasoning.sources中的路径没有路径分隔符 → warning(建议使用完整路径)
Layer 3(唯一性) 通过两种方式检测重复:
- 标题去重:对 title 做
trim().toLowerCase()后与已有标题集合比对 - 代码指纹:对
coreCode去除注释和空白后取前 200 字符的小写形式作为指纹
function codeFingerprint(code: string) {
return (code || '')
.replace(/\/\/[^\n]*/g, '') // 移除单行注释
.replace(/\/\*[\s\S]*?\*\//g, '') // 移除多行注释
.replace(/[\s]+/g, '') // 移除所有空白
.toLowerCase()
.slice(0, 200);
}指纹算法刻意简单——它不是语义级的代码相似度检测,而是快速排除完全重复的提交。更精细的相似度比较由 CandidateAggregator 的 Jaccard 相似度算法处理。
验证结果的结构也值得注意:errors 和 warnings 是字符串数组,不是错误码。这是因为验证结果的消费方是 AI Agent——它需要读懂错误原因并修正提交,人类可读的中文消息比 ERR_FIELD_MISSING_TITLE 对 LLM 更友好。
核心实现
Recipe Markdown 双向映射
KnowledgeEntry 在内存中是 TypeScript 对象,但持久化形式是 Markdown 文件。这个选择不是偶然的:
- Human-readable:打开
.asd/recipes/目录,直接用文本编辑器就能阅读知识内容 - Git diff friendly:Markdown 的变更在
git diff中清晰可读,不像 JSON 那样整个对象重排 - 可编辑:开发者可以直接编辑 Recipe 文件,系统会在下次加载时解析变更
一个 Recipe 的 Markdown 文件长这样:
---
title: CookieProviding 请求封装规范
trigger: @cookie-providing-pattern
category: Network
language: swift
kind: rule
knowledgeType: best-practice
---
# CookieProviding 请求封装规范
所有涉及 Cookie 的网络请求必须通过 CookieProviding 统一封装...
## Code
```swift
let provider = CookieProviding(
storage: .keychain,
session: URLSession.shared
)
let cookies = try await provider.fetchCookies(for: url)
```
## Usage Guide
### 基础用法
...
### 错误处理
...
**序列化(KnowledgeEntry → Markdown)** 由 `KnowledgeFileWriter` 负责。YAML frontmatter 承载元数据字段(title、trigger、category、language、kind 等),Markdown body 承载 `content.markdown`,代码块承载 `coreCode`。
**反序列化(Markdown → KnowledgeEntry)** 由 `RecipeParser` 负责:
```typescript
// lib/service/recipe/RecipeParser.ts
class RecipeParser {
parse(text: string): ParsedRecipe | null {
// 1. 提取 YAML frontmatter(--- 之间的内容)
// 2. 解析 Markdown 结构(# 标题、## 子标题、代码块)
// 3. 识别 Usage Guide 段落
// 4. 返回结构化数据
}
isCompleteRecipe(text: string): boolean {
// YAML frontmatter + 代码块 + Usage Guide 三者俱全
}
}RecipeParser 的容错设计很重要。一个由开发者手工编辑的 Markdown 文件可能缺少 frontmatter 中的某些字段,或者代码块使用了非标准的语法。解析器不会在这些情况下抛出异常——它提取能提取的内容,缺失的字段回退到默认值,通过 UnifiedValidator 的 warning 告知上层哪些信息需要补充。
Candidate 与 Recipe:同一实体的不同阶段
在 V3 之前,系统有独立的 Candidate 和 Recipe 类型——候选提交用一个数据结构,审核通过后"转换"为另一个数据结构。这导致了大量的字段映射代码和状态转换逻辑。
V3 的核心简化是:Candidate 和 Recipe 不是两种实体,而是同一个 KnowledgeEntry 的不同生命周期状态。
// KnowledgeEntry.ts
isCandidate() {
return isLifecycleCandidate(this.lifecycle);
// lifecycle === 'pending' || lifecycle === 'staging'
}
isActive() {
return this.lifecycle === Lifecycle.ACTIVE;
}lifecycle === 'pending' 的条目是候选(Candidate),lifecycle === 'active' 的条目是正式知识(Recipe)。从候选到正式,不需要类型转换——只需要一次状态转换:
// KnowledgeEntry.ts
publish(publisher: string) {
if (!this.isValid()) {
return { success: false, error: '内容不完整,无法发布' };
}
const result = this._transition(Lifecycle.ACTIVE);
if (result.success) {
this.publishedAt = this._now();
this.publishedBy = publisher;
}
return result;
}目录结构反映了这种状态分离:
.asd/
├── candidates/ # lifecycle = pending | staging
│ ├── entry-a.md
│ └── entry-b.md
└── recipes/ # lifecycle = active | evolving | decaying
├── entry-c.md
└── entry-d.md当一个条目从 pending 发布为 active,KnowledgeFileWriter 将对应的 .md 文件从 candidates/ 移动到 recipes/。这个文件移动不是原子操作——如果中途失败,DB 中的 lifecycle 已经更新但文件还在旧目录。系统通过启动时的 reconciliation 检查来修复这类不一致:扫描文件系统和数据库,把不匹配的条目重新对齐。
审核流程的完整数据路径:
AI Agent 扫描代码 → 构建 KnowledgeEntry(pending)
↓
UnifiedValidator 三层校验
↓
FileWriter 写入 candidates/entry.md
↓
Repository.create() 插入数据库
↓
Dashboard 展示候选列表
↓
开发者点击"批准" → KnowledgeService.publish()
↓
entry.publish(userId) → lifecycle: pending → active
↓
FileWriter 移动文件 candidates/ → recipes/
↓
Repository.update() 更新 lifecycle + publishedAt
↓
EventBus.emit('lifecycle:transition')
↓
CursorDeliveryPipeline 异步刷新 .mdc 文件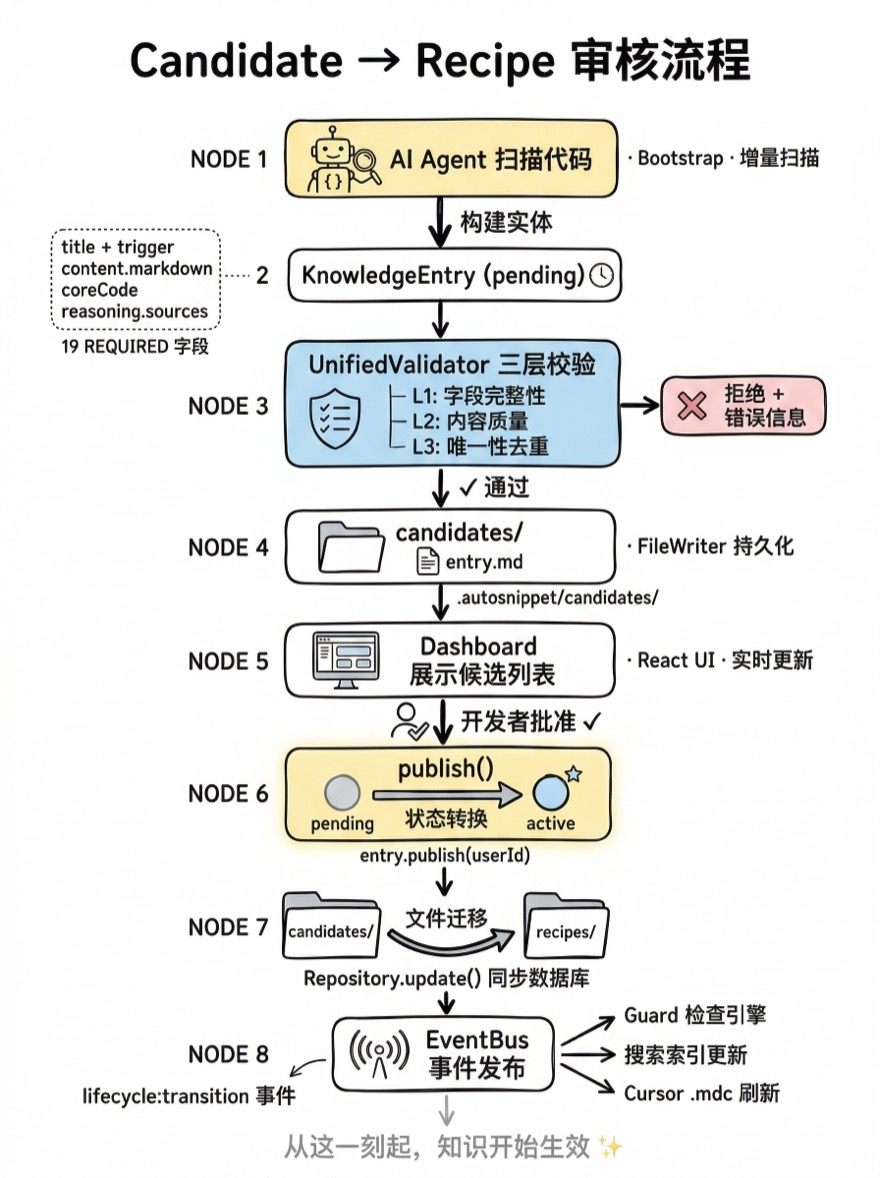
运行时行为
场景一:Agent 发现代码模式
AI Agent 在 Bootstrap 或增量扫描中发现一个代码模式——比如项目中所有 ViewController 都通过 AppCoordinator 管理导航。Agent 构建一个 KnowledgeEntry 提交:
KnowledgeService.create({
title: 'AppCoordinator 导航管理规范',
trigger: '@app-coordinator-navigation',
kind: 'rule',
knowledgeType: 'architecture',
category: 'View',
language: 'swift',
doClause: 'Use AppCoordinator for all navigation transitions',
dontClause: 'Do NOT call pushViewController directly from ViewControllers',
whenClause: 'When implementing screen navigation logic',
coreCode: `coordinator.navigate(to: .detail(item))`,
content: {
markdown: '本项目使用 AppCoordinator 模式集中管理页面导航...(≥200字)',
rationale: 'Coordinator 模式将导航逻辑从 VC 中解耦...'
},
reasoning: {
whyStandard: '项目中 12 个 VC 均通过 coordinator 跳转...',
sources: ['BiliDili/AppCoordinator.swift', 'BiliDili/Modules/Home/HomeVC.swift'],
confidence: 0.88
},
headers: ['import UIKit'],
usageGuide: '### 基础导航\n...'
}, context);KnowledgeService.create() 的处理链:
- 输入校验——title 和 content 不能为空
- 标题查重——通过
findByTitle()防止跨维度重复 - 实体构建——
KnowledgeEntry.fromJSON()构造领域对象 - Skill Hook——
onKnowledgeSubmit()插件钩子可以阻止提交 - 路由决策——
ConfidenceRouter根据置信度决定是否自动进入 staging - 文件持久化——写入
candidates/<id>.md - 数据库插入——带
sourceFile字段标记文件位置 - 关系同步——填充
knowledge_edges知识图谱 - 审计日志 + 事件发布
场景二:开发者批准候选
开发者在 Dashboard 中看到这条候选,确认内容准确,点击"批准":
KnowledgeService.publish(entryId, { userId: 'developer-1' });publish() 内部调用 entry.publish(userId),实体验证当前状态允许转换到 active,然后设置 publishedAt 和 publishedBy。文件从 candidates/ 移到 recipes/,数据库更新 lifecycle。最后 EventBus 发出 lifecycle:transition 事件,CursorDeliveryPipeline 异步刷新 .mdc 文件——从这一刻起,这条知识开始参与 Guard 检查和搜索。
场景三:Guard 规则消费
当 kind === 'rule' 的知识条目处于 active 状态时,GuardCheckEngine 可以从中提取检查规则:
// KnowledgeEntry.ts
getGuardRules() {
if (!this.isActive() || !this.isRule()) {
return [];
}
const regexRules = this.constraints.getRegexGuards().map((g) => ({
id: g.id || this.id,
type: 'regex',
name: g.message || this.title,
pattern: g.pattern,
languages: this.language ? [this.language] : [],
severity: g.severity || 'warning',
source: 'knowledge_entry',
}));
// ...AST rules 类似处理
return [...regexRules, ...astRules];
}Guard 规则有两种类型:正则表达式(快速但粗糙)和 AST 查询(精确但需要解析)。一条 Recipe 可以同时携带两种规则——正则做第一遍快筛,AST 做精确验证。但只有 active 状态的 rule 类型条目才会被 Guard 消费——pending(未审核)和 deprecated(已废弃)都被排除在外。
权衡与替代方案
为什么不用 JSON Schema 做验证
JSON Schema 是通用的结构验证标准,FieldSpec 看起来像是在重新发明轮子。但两者的设计意图不同:
- JSON Schema 验证数据"是否符合结构"——类型、格式、必需性
- FieldSpec 验证数据"是否适合成为知识"——内容质量、代码完整性、命名规范
coreCode 不能以 } 开头——这不是结构约束,而是业务逻辑。title 不能是泛型名称——这需要启发式检测,JSON Schema 的 pattern 表达力不够。更关键的是,FieldSpec 的 pipeline 字段将验证规则与下游消费方关联——这种"面向管线的字段规范"在 JSON Schema 中没有对应的概念。
为什么 Markdown 而非纯 JSON
知识库的 .asd/ 目录会被提交到 Git。如果 Recipe 是 JSON 文件:
{"title":"CookieProviding 请求封装规范","content":{"markdown":"本项目使用...","rationale":"Coordinator 模式..."},"trigger":"@cookie-providing-pattern"}在 git diff 中,一个字段的修改会显示为整行变更,你无法直观地看到"改了哪个字段的什么值"。而 Markdown + YAML frontmatter 的变更是逐行的、语义清晰的。
更重要的是,Markdown 是开发者的母语。一个新加入团队的成员可以直接打开 recipes/ 目录浏览项目的编码知识,不需要任何工具,不需要 Dashboard,不需要 MCP 服务器——这是一层零成本的"降级阅读体验"。
统一实体的代价
统一实体不是没有代价的。fact 类型的知识条目有一个 coreCode 字段永远为空;pattern 类型有一个 constraints.guards 永远是空数组。如果数据库中有 1000 条 Recipe,其中 300 条是 fact,那 300 个 coreCode 列都是空字符串——这是存储空间的浪费。
但在当前规模下(多数项目的 Recipe 数量在 50-200 之间),这个浪费完全可以忽略。换来的是:搜索只查一张表、API 只维护一套 CRUD、生命周期只实现一个状态机。在知识引擎的语境下,设计的简洁性远比存储效率重要——因为复杂性的成本是持续的维护负担,而空字符串的成本是可忽略的磁盘空间。
小结
KnowledgeEntry 的核心设计哲学可以概括为三句话:
- 一个实体承载所有知识——通过
kind+knowledgeType做语义分类,而非类型继承 - FieldSpec 是字段的唯一权威来源——一处定义,多处消费,消灭验证逻辑的碎片化
- Candidate 与 Recipe 是同一个实体的生命周期阶段——状态转换代替类型转换
这些决策共同指向一个目标:让知识的建模、验证、存储和消费走同一条路径。下一章我们将沿着这条路径继续深入,看一条知识从诞生到消亡的完整旅程。