Bootstrap — 冷启动的多阶段编排
面对一个全新项目,如何从零建立完整的知识库。
问题场景
用户在新项目中运行 asd setup 后说“帮我冷启动”。此时知识库为空,AST 缓存为空,向量索引为空。Agent 需要从零开始理解整个项目——扫描数百个文件、解析代码结构(见 ch05 代码理解)、推断调用关系、检测设计模式、提取编码规范,最后产出可用的 Recipe 候选(每条候选的建模见 ch06 KnowledgeEntry)。
但这里有一个根本性的设计抉择:谁来做知识提取?
如果系统自带 AI Provider(OpenAI、Gemini 等 API Key),完全可以在后台自动完成全部分析——文件收集、AST 解析、依赖图构建、Guard 审计,然后启动 Agent 逐维度提取知识。用户只需等待进度条走完。
但现实更复杂。许多用户通过 IDE Agent(Cursor、GitHub Copilot)接入 Alembic,此时系统没有独立的 AI Provider——分析能力由 IDE 的 Agent 提供。系统能做的只是把项目结构和上下文准备好,然后以 Mission Briefing 的形式交给 IDE Agent 去执行。
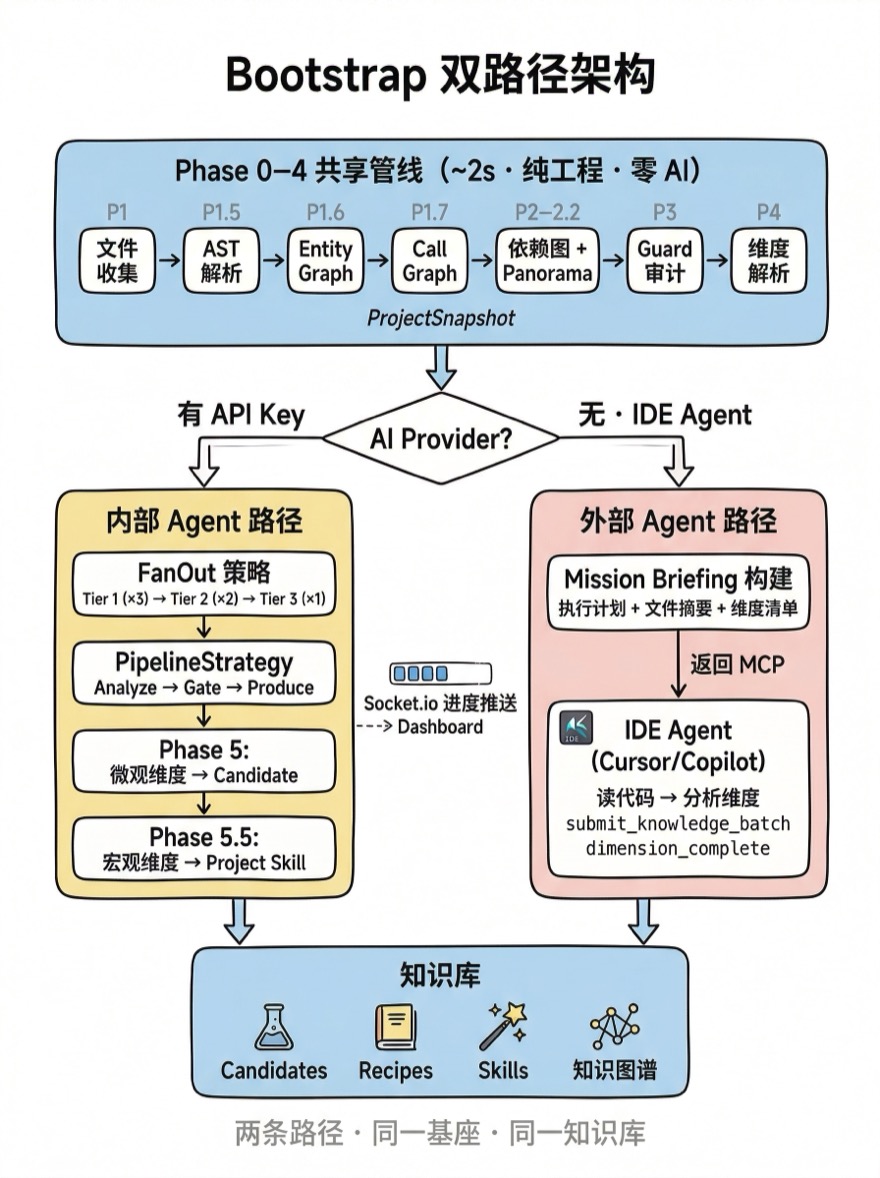
这就产生了 Bootstrap 的双路径架构:
- 内部 Agent 路径:系统有 AI Provider,同步完成结构分析 + 异步后台填充知识
- 外部 Agent 路径:系统无 AI Provider,同步完成结构分析 + 返回 Mission Briefing 让 IDE Agent 接手
不论哪条路径,Phase 1–4 的结构分析完全一样——都是纯工程逻辑、无 AI 参与、确定性执行。区别仅在于 Phase 5 的知识填充谁来做。这正是 SOUL 原则"AI 编译期 + 工程运行期"的又一次体现。
设计决策
为什么需要如此深入的工程化解析
初看之下,13 个阶段的管线似乎过度设计——为什么不直接把源码文件丢给 LLM,让它自己分析?
答案藏在 LLM 的工作模型中。当前 Agent 架构的核心模式是 Tool-Augmented Pull:LLM 本身不主动"看"代码,而是通过调用工具(Tool)来获取信息。系统提供一组工具,LLM 在推理循环中决定"用哪个工具、传什么参数",然后根据工具返回的结果继续推理。
这意味着一个根本性的约束:LLM 的推理质量,直接受限于工具返回结果的质量。
如果 query_call_graph 工具返回的调用关系是错的,LLM 会基于错误的依赖关系做出错误的架构判断。如果 get_class_hierarchy 工具返回的继承链缺失了中间层,LLM 会遗漏关键的设计模式。LLM 的推理能力再强,也无法弥补输入数据的缺陷——这就是计算机科学中经典的 Garbage In, Garbage Out 原则在 Agent 时代的重现。
所以 Bootstrap 的 13 个阶段,本质上是在打造每一个 Tool 的数据基础:
| 工程阶段 | 对应工具 | 如果跳过会怎样 |
|---|---|---|
| Phase 1.5 AST 解析 | get_class_info、get_method_info | LLM 只能看到原始文本,无法精确查询类和方法的结构 |
| Phase 1.6 实体图 | query_code_entities | LLM 无法查询跨文件的类型引用关系 |
| Phase 1.7 调用图 | query_call_graph | LLM 无法回答"谁调用了这个方法"这类问题 |
| Phase 2 依赖图 | query_dependency_graph | LLM 无法理解模块间的依赖方向和层次 |
| Phase 2.2 全景图 | panorama | LLM 无法回答"项目的整体架构是什么"这类宏观问题 |
| Phase 3 Guard 审计 | guard_check | LLM 无法判断代码是否符合项目规范 |
每多做一步工程化分析,LLM 就多获得一个高质量的工具。每个工具返回的结果越结构化、越准确,LLM 的推理链就越可靠。这不是过度设计——这是为 AI Agent 构建可靠工作环境的必要投资。
换一个角度理解:Phase 1–4 做的事情,相当于在 LLM "上班"之前,把它的"办公桌"整理好——文件分类归档、组织架构图绘制完毕、规章制度整理就位。一个拿到整理好的材料的 LLM,和一个面对杂乱文件堆的 LLM,工作效率和产出质量是天壤之别。
这个认知并非 Alembic 独创。Anthropic 在 Building effective agents(2024.12)一文中明确提出了同样的观点:
"Agents can handle sophisticated tasks, but their implementation is often straightforward. They are typically just LLMs using tools based on environmental feedback in a loop. It is therefore crucial to design toolsets and their documentation clearly and thoughtfully."
文章进一步提出了 ACI(Agent-Computer Interface) 的概念——类比人机交互领域的 HCI(Human-Computer Interface),强调为 Agent 设计工具接口需要投入与设计用户界面同等的精力:
"One rule of thumb is to think about how much effort goes into human-computer interfaces (HCI), and plan to invest just as much effort in creating good agent-computer interfaces (ACI)."
更值得注意的是 Anthropic 在 SWE-bench 实践中的经验:他们花在优化工具上的时间,比花在优化整体提示词上的时间还多。例如他们发现模型在使用相对路径时会频繁出错,于是将工具改为强制使用绝对路径——模型随即表现完美。这个细节印证了一个核心洞察:Agent 的表现瓶颈往往不在 LLM 的推理能力,而在工具的设计质量。
Alembic 的 Bootstrap 管线正是这一理念的工程实践——13 个阶段的深度解析,本质上是在精心打造每一个 ACI,让 LLM 在后续的知识提取阶段能够高效、准确地工作。
管线阶段总览
Bootstrap 管线分为同步阶段(~1–3 秒,纯工程计算)和异步阶段(后台 AI 填充),共 13 个逻辑阶段:
| Phase | 名称 | 职责 | 耗时 |
|---|---|---|---|
| 0 | 全量清理 | 重置数据库表、清除衍生缓存 | < 100ms |
| 1 | 文件收集 | SPM/Gradle/Cargo Target 扫描、去重、黑名单过滤 | ~ 200ms |
| 1.5 | AST 代码结构分析 | Tree-sitter 批量解析、SFC 预处理、类/协议/分类提取 | ~ 500ms |
| 1.5a | 语法包按需安装 | 自动下载缺失的 Tree-sitter 语法包 | 0–2s |
| 1.6 | Code Entity Graph | AST → 代码实体关系图谱(entities + edges) | ~ 300ms |
| 1.7 | Call Graph | 跨文件调用关系推断、数据流边分析 | ~ 500ms |
| 2 | 依赖图 | 包管理系统依赖关系 → knowledge_edges | ~ 200ms |
| 2.1 | Module 实体写入 | 依赖图节点 → Code Entity Graph 实体 | ~ 100ms |
| 2.2 | Panorama 全景 | 模块角色推断、分层、耦合分析、空白区检测 | ~ 300ms |
| 3 | Guard 规则审计 | 代码风格 + 架构 + 安全规则扫描 | ~ 200ms |
| 4 | 维度条件解析 | 按主语言/框架激活维度 + Enhancement Pack 追加 | ~ 50ms |
| 5 | 微观维度填充 | 7 个知识维度 × 子主题代码分析 → Candidate | 异步 |
| 5.5 | 宏观维度 Skill 生成 | architecture/code-standard/project-profile 聚合为 Skill | 异步 |
Phase 0–4 在 runAllPhases() 中顺序执行,是两条路径的共享逻辑。Phase 5/5.5 只在内部 Agent 路径自动启动,外部 Agent 路径则由 IDE Agent 在 Mission Briefing 引导下手动执行。
这个阶段编号并不连续(1 → 1.5 → 1.5a → 1.6 → 1.7 → 2 → 2.1 → 2.2),看起来有些"随意"。实际上这反映了管线的增量演化——每当需要在两个已有阶段之间插入新步骤时,使用小数编号可以避免重新编号导致的配置迁移和日志断裂。这种务实的版本策略与 SemVer 的子版本号异曲同工。
两条路径的本质差异
理解双路径的关键在于看清它们的共性和差异:
┌─────────────────────────────────────────┐
│ Phase 0–4 共享管线 │
│ File → AST → Entity → CallGraph → │
│ Dependency → Panorama → Guard → Dims │
└───────────────┬─────────────────────────┘
│
┌───────────────┴───────────────┐
▼ ▼
┌─────────────────────┐ ┌─────────────────────┐
│ 内部 Agent 路径 │ │ 外部 Agent 路径 │
│ │ │ │
│ dispatchPipelineFill│ │ buildMissionBriefing│
│ Phase 5: FanOut │ │ → 返回给 IDE Agent │
│ Phase 5.5: Skill │ │ │
│ │ │ IDE Agent 逐维度: │
│ Socket.io 进度推送 │ │ 读代码→提交候选→ │
│ Dashboard 实时更新 │ │ 标记维度完成 │
└─────────────────────┘ └─────────────────────┘| 维度 | 内部 Agent | 外部 Agent |
|---|---|---|
| AI 来源 | 系统配置的 API Provider | IDE 内置 Agent(Cursor/Copilot) |
| Phase 5 执行者 | 系统自动 dispatchPipelineFill | IDE Agent 手动 |
| 增量支持 | 有(快照 Diff 判定) | 无(总是全量扫描) |
| 返回内容 | 骨架 + 任务清单 + bootstrapSession | Mission Briefing(执行计划 + 文件摘要) |
| Candidate 创建 | 异步后台自动创建 | IDE Agent 调用 submit_knowledge_batch |
| Skill 生成 | Phase 5.5 自动聚合 | IDE Agent 通过 dimension_complete 提交 |
| 进度可视 | Socket.io → Dashboard 实时更新 | 无(IDE 内部进度) |
外部 Agent 路径的返回消息直截了当:
⚠️ Bootstrap 仅完成第一步(项目扫描),你必须继续完成全部 N 个维度的分析。
请立即按 executionPlan.tiers 的顺序,对每个维度执行:
(1) 用你的代码阅读能力分析该维度相关文件 →
(2) 调用 asd_submit_knowledge_batch 提交候选知识 →
(3) 调用 asd_dimension_complete 标记维度完成。这段提示不是给人看的——是给 IDE Agent 看的。Agent 收到后会像收到一份任务清单,逐条执行。这是 MCP 协议下工具与 Agent 之间的协作接口设计。
同步管线详解
Phase 1:文件收集
文件收集是整条管线的起点。它的核心任务是:用最少的扫描开销,收集到项目中值得分析的源码文件。
// lib/external/mcp/handlers/bootstrap/shared/bootstrap-phases.ts
export async function runPhase1_FileCollection(
projectRoot: string,
logger: PhaseLogger,
options: Phase1Options = {}
) {
const maxFiles = options.maxFiles || 500;
const registry = getDiscovererRegistry();
const discoverer = await registry.detect(projectRoot);
await discoverer.load(projectRoot);
const allTargets = await discoverer.listTargets();
const seenPaths = new Set<string>();
const allFiles: BootstrapFileEntry[] = [];
for (const t of allTargets) {
const fileList = await discoverer.getTargetFiles(t);
for (const f of fileList) {
const fp = typeof f === 'string' ? f : f.path;
if (seenPaths.has(fp)) { continue; }
if (isAlembicGenerated(fp)) { continue; }
seenPaths.add(fp);
const content = fs.readFileSync(fp, 'utf8');
allFiles.push({ name: path.basename(fp), path: fp, /* ... */ });
if (allFiles.length >= maxFiles) { break; }
}
}
return { allFiles, allTargets, discoverer, langStats, truncated };
}这里有几个关键设计点:
DiscovererRegistry 自动检测。系统不要求用户声明项目类型——registry.detect(projectRoot) 会检查标记文件(Package.swift → SPM, package.json → Node.js, build.gradle → Gradle, Cargo.toml → Rust, go.mod → Go)自动选择最优 Discoverer。每个 Discoverer 知道如何枚举该生态系统下的 Target(编译模块)和源文件。
R13 黑名单。isAlembicGenerated() 排除系统自身生成的文件——AGENTS.md、CLAUDE.md、copilot-instructions.md、.cursor/ 目录、.mdc 生成物。这是一条自我保护规则:如果把这些文件纳入分析,系统会从自己生成的指令中"提取知识",形成自引用循环。
500 文件截断。maxFiles 默认 500,超出后发出 truncated 警告。这不是一个保守的限制——对于 AST 分析和 AI 提取来说,500 个文件已经足够建立项目骨架。更多文件可以在后续增量扫描中补充。截断阈值可通过 CLI 参数 --max-files 调整。
Phase 1.5:AST 批量分析
文件收集完成后,下一步是把源码文本转化为结构化的语法树。
export async function runPhase1_5_AstAnalysis(
allFiles: BootstrapFileEntry[],
langStats: Record<string, number>,
logger: PhaseLogger,
options: AstAnalysisOptions = {}
) {
// 1.5a:按需安装语法包
const neededLangs = inferLanguagesFromStats(langStats);
if (neededLangs.length > 0) {
const result = await ensureGrammars(neededLangs, { logger });
}
// 1.5b:SFC 预处理(Vue/Svelte 单文件组件)
const enhReg = await initEnhancementRegistry();
const sfcPreprocessor = enhReg.all()
.find(p => typeof p.preprocessFile === 'function');
// 1.5c:项目级 AST 分析
const astProjectSummary = analyzeProject(
allFiles.map(f => ({
name: f.name, relativePath: f.relativePath, content: f.content
})),
primaryLangEarly,
{ preprocessFile: sfcPreprocessor }
);
}按需安装是一个精妙的设计。inferLanguagesFromStats(langStats) 从文件扩展名统计中推断出需要哪些 Tree-sitter 语法包,然后 ensureGrammars() 只下载缺失的。一个纯 Swift 项目不会被迫安装 Python 语法包。这避免了"全量预装"的启动膨胀。
SFC 预处理解决了 Vue 和 Svelte 单文件组件的问题——这些文件包含 <template>、<script>、<style> 三个区块,需要先拆分再分别解析。Enhancement Pack 提供的 preprocessFile() 在 AST 解析前介入,把 .vue 文件拆成独立的 TypeScript 和 HTML 片段。
Phase 1.5 输出的 astProjectSummary 是后续所有分析的基础数据源——它包含项目中所有的类、协议、方法、属性、调用点信息。
Phase 1.6–1.7:图谱构建
在 AST 提取了"原子事实"之后,Phase 1.6 和 1.7 负责构建跨文件的关系图谱。
Phase 1.6 — Code Entity Graph:
const ceg = new CodeEntityGraph(entityRepo, edgeRepo, { projectRoot });
await ceg.clearProject();
const codeEntityResult = await ceg.populateFromAst(astProjectSummary);
// → { entitiesUpserted: 342, edgesCreated: 1205 }CodeEntityGraph 把 AST 中散落在各文件的类、方法、属性统一写入 code_entities 和 knowledge_edges 表。一个在 UserService.swift 中定义的方法和在 UserController.swift 中被调用的同一个方法,在这一步被关联为一条 calls 边。
Phase 1.7 — Call Graph Analysis:
const analyzer = new CallGraphAnalyzer(projectRoot);
const result = await analyzer.analyze(astProjectSummary, {
timeout: 15_000, // 15 秒超时保护
maxCallSitesPerFile: 500, // 每文件最多 500 个调用点
minConfidence: 0.5, // 低于 0.5 的推断丢弃
});调用图分析有三个关键阈值:
- 15 秒超时:某些超大项目(上万个调用点)的分析可能耗时过长。超时后返回部分结果——已分析的调用边保留,未分析的跳过。管线的鲁棒性要求:宁可少分析,不可阻塞。
- 500 调用点/文件:防止单个巨型文件(如自动生成的代码)独占分析时间。
- 0.5 置信度门槛:静态分析推断的调用关系不总是准确的(尤其是动态分派、协议方法),低于 0.5 的推断直接丢弃。
调用图支持增量分析:如果 changedFiles 不超过 10 个,只重新分析这些文件的调用关系,其余复用缓存。
Phase 2–2.2:依赖图与全景
Phase 2 从包管理器获取模块级依赖关系:
const depGraphData = await discoverer.getDependencyGraph();
for (const edge of depGraphData.edges || []) {
await knowledgeGraphService.addEdge(
edge.from, 'module',
edge.to, 'module',
'depends_on',
{ weight: 1.0, source: `${discoverer.id}-bootstrap` }
);
}SPM Discoverer 解析 Package.resolved,Gradle Discoverer 解析 build.gradle 的 dependencies 块,Cargo Discoverer 解析 Cargo.lock。输出统一写入知识图谱的 depends_on 边。
Phase 2.2 的 Panorama 全景计算是整个同步管线的"汇总层"——它把前面所有阶段的数据聚合成一份项目全景报告:
- 模块角色推断:
presentation/business/data/utility - 分层分析:基于调用图的方向性推断模块在架构中的层次
- 耦合热点:高 fan-in/fan-out 的模块
- 环形依赖检测:Tarjan SCC 算法发现的强连通分量
- 知识空白区:哪些维度尚无 Recipe 覆盖
Phase 3:Guard 审计
Guard 审计在冷启动时扮演"初始体检"的角色——在知识提取之前先检查项目现状:
guardAudit = guardEngine.auditFiles(
allFiles.map(f => ({ path: f.path, content: f.content })),
{ scope: 'file' }
);审计结果不会阻塞 Bootstrap 流程。它的价值是为后续维度分析提供上下文——如果 Guard 发现大量代码风格违规,coding-standards 维度的 Agent 在分析时就能知道"这个项目的规范执行不太严格,需要更多规范类 Recipe"。
--skip-guard 标志允许跳过审计,适用于纯粹想快速建库的场景。
Phase 4:维度解析
Phase 4 根据项目特征激活对应的分析维度:
const activeDimensions = resolveActiveDimensions({
primaryLang, // 'swift'
langStats, // { swift: 320, objc: 45 }
targetCount: 12,
fileCount: 365,
astAvailable: true,
hasAstPatterns: true,
});这一步决定了 Phase 5 要分析哪些维度。一个 Swift 项目可能激活 13 个通用维度 + swift-objc-idiom 语言维度 + swiftui-pattern 框架维度;一个 Python Django 项目则可能额外激活 python-structure + django-convention。Enhancement Pack 可以动态追加维度——如果检测到项目使用了 RxSwift,concurrency-async 维度的提取指南会自动补充 RxSwift 相关模式。
至此,Phase 0–4 完成。同步管线的输出是一个完整的 ProjectSnapshot——项目的"CT 扫描报告",包含文件清单、AST 摘要、代码实体图、调用图、依赖图、全景分析、Guard 审计结果、激活维度列表。
异步填充:FanOut 策略
Phase 5 是知识提取的核心——把 ProjectSnapshot 转化为具体的 Recipe 候选。在内部 Agent 路径中,这一步由 FanOutStrategy 驱动并行执行。
Tier 分组与并发控制
new FanOutStrategy({
itemStrategy: new PipelineStrategy({
stages: [
{ name: 'analyze', capabilities: ['code_analysis'],
budget: { maxIterations: 24 } },
{ name: 'gate',
gate: { minEvidenceLength: 500, minFileRefs: 3 } },
{ name: 'produce', capabilities: ['knowledge_production'],
budget: { maxIterations: 24 } },
]
}),
tiers: {
1: { concurrency: 3 },
2: { concurrency: 2 },
3: { concurrency: 1 },
}
})维度被分成三个 Tier,按优先级逐批执行:
| Tier | 并发数 | 包含维度 | 理由 |
|---|---|---|---|
| 1 | 3 | code-pattern, coding-standards, best-practice | 最基础的知识,其他维度可能引用 |
| 2 | 2 | architecture, project-profile, error-resilience | 需要更深入的上下文理解 |
| 3 | 1 | agent-guidelines, 语言/框架特定维度 | 依赖前两批的输出 |
并发控制使用 p-limit——每个 Tier 内部的并发数严格限制,防止 LLM API 过载。Tier 之间顺序执行,确保上游维度的 Recipe 已经入库,下游维度的 Agent 在分析时可以引用。
PipelineStrategy:三阶段管道
每个维度的分析不是一次性的 LLM 调用,而是一条三阶段管道:
Analyze 阶段:Agent 带着维度特定的 extractionGuide 阅读项目源码,识别该维度下的知识模式。预算限 24 轮迭代——Agent 可以调用 24 次工具(读文件、搜索代码、查 AST)来收集证据。
Gate 阶段:质量门控。检查 Analyze 阶段的输出是否达到最低标准:
gate: {
minEvidenceLength: 500, // 分析文本至少 500 字符
minFileRefs: 3, // 至少引用 3 个源文件
}Gate 的评估结果是三态的:
pass:质量合格,进入 Produce 阶段retry:质量不足但可挽救——回退到 Analyze 阶段重新收集,重试最多 1 次degrade:无法挽救——标记该维度为降级,跳过 Produce
这个三态设计与 Guard 的 pass / violation / uncertain 三态是同一思路——在"通过"和"失败"之间留出灰色地带,让系统有机会自我修正。
Produce 阶段:基于 Analyze 的输出生成结构化的 Candidate 知识条目,调用 asd_submit_knowledge_batch 写入知识库。
Analyze (24 轮) → Gate → Produce (24 轮)
↑ |
└──── retry ─────────┘PipelineStrategy 支持更精细的控制。每个阶段可以有独立的 promptBuilder(动态构建提示词)、systemPrompt(阶段专属系统提示)、onToolCall(工具调用拦截器)、budget.timeoutMs(硬超时保护)。阶段间通过 phaseResults 传递上下文,但 ContextWindow 在阶段切换时重置——这确保每个阶段都从"干净"的上下文开始,避免前一阶段的长输出污染后一阶段的注意力。
微观与宏观维度的分流
Phase 5 和 Phase 5.5 的区别在于知识的粒度:
微观维度(Phase 5):code-pattern、best-practice、concurrency-async、data-event-flow 等。每个维度产出多条细粒度 Candidate——一个项目可能在 code-pattern 维度下提取出 8–15 条模式知识。
宏观维度(Phase 5.5):architecture、coding-standards、project-profile。这些维度的知识更适合以整体视角呈现,而不是拆成零散条目。Phase 5.5 把它们聚合为 Project Skill——一个完整的 Markdown 文件写入 Alembic/skills/ 目录。
这个分流避免了两个问题:
- 宏观知识如果拆成 Candidate,每条都不完整——"项目分层架构"切成 5 条互相引用的 Recipe,不如一份 Skill 文档清晰
- 微观知识如果合成 Skill,粒度太粗——"使用
actor替代NSLock"这种具体模式,作为独立 Recipe 更方便 Guard 引用
BootstrapTaskManager:异步编排
Phase 5 的异步执行需要精确的状态管理和进度追踪。BootstrapTaskManager 是这条异步管线的调度中枢。
Session 生命周期
class BootstrapTaskManager {
startSession(taskDefs: TaskDef[]) {
if (this.isRunning) {
this.abortSession('Superseded by new bootstrap request');
}
const sessionId = `bs_${Date.now()}_${randomId()}`;
this.#currentSession = new BootstrapSession(sessionId);
for (const { id, meta } of taskDefs) {
this.#currentSession.addTask(id, meta);
}
this.#emit('bootstrap:started', { sessionId, tasks: taskDefs, total: taskDefs.length });
return this.#currentSession;
}
}每次 Bootstrap 只允许一个活跃 Session。如果用户在上一次冷启动尚未完成时再次触发,新 Session 会自动中止前一个——所有未完成的任务标记为 failed,原因记录为 "Superseded by new bootstrap request"。这是一个重要的安全设计:防止两次冷启动的异步填充交叉写入,产出数据冲突。
四态任务状态机
每个维度任务经历四个状态:
skeleton → filling → completed
→ failed- skeleton:任务已创建,等待填充。Phase 0–4 同步完成后,所有维度任务都处于此状态。
- filling:内容填充进行中。FanOut 调度一个维度时,标记为此状态。
- completed:填充成功,携带结果摘要(toolCallCount、tokenUsage)。
- failed:填充失败,携带错误信息。
session.progress 实时计算完成百分比:(completed + failed) / total * 100。注意 failed 也计入进度——失败不会让进度条卡住。当 session.isAllDone 为 true 时(所有任务都进入 completed 或 failed),自动触发 #finishSession()。
双通道进度推送
#emit(eventName: string, data: unknown) {
// 通道 1:EventBus — 后端监听
this.#eventBus?.emit(eventName, data);
// 通道 2:Socket.io — 前端推送
const realtime = this.#getRealtimeService?.();
realtime?.broadcastEvent(eventName, data);
}每个状态变迁都通过两个通道同时推送:
- EventBus(后端):其他服务可以监听 Bootstrap 事件,比如日志服务记录审计日志
- Socket.io(前端):Dashboard 实时更新进度条和任务卡片
五种事件类型:
| 事件 | 触发时机 | 携带数据 |
|---|---|---|
bootstrap:started | Session 创建,骨架就绪 | 任务清单、总数、启动时间 |
bootstrap:task-started | 单维度开始填充 | taskId、meta、当前进度 |
bootstrap:task-completed | 单维度填充完成 | result、toolCallCount、elapsedMs |
bootstrap:task-failed | 单维度填充失败 | error、当前进度 |
bootstrap:all-completed | 全部维度完成 | 摘要(duration、completed、failed) |
Dashboard 监听这些事件,逐项更新维度卡片的状态:灰色(skeleton)→ 蓝色脉冲(filling)→ 绿色(completed)或红色(failed)。用户无需刷新页面就能看到每个维度的实时进度。
Session 有效性检测
异步维度填充是 fire-and-forget 的——dispatchPipelineFill() 不等待完成。如果在填充过程中用户触发了新的 Bootstrap,老 Session 被中止,但异步任务可能还在执行。
isSessionValid(sessionId: string) {
return (
this.#currentSession?.id === sessionId &&
(this.#currentSession.status === 'running' ||
this.#currentSession.status === 'completed' ||
this.#currentSession.status === 'completed_with_errors')
);
}每个异步任务在写入 Candidate 前会调用 isSessionValid() 检查自己的 Session 是否还活着。如果 Session 已被新请求取代,任务静默退出,不写入任何数据。
增量 Bootstrap:快照与 Diff
冷启动不一定每次都全量执行。项目代码持续变化,每次改几个文件就重新扫描整个项目是浪费。IncrementalBootstrap 通过快照对比实现增量分析。
BootstrapSnapshot:全量记忆
每次 Bootstrap 完成后,系统保存一份快照:
interface SnapshotData {
id: string; // snap_<uuid>
fileHashes: Record<string, string>; // path → sha256
dimensionMeta: Record<string, {
candidateCount: number;
analysisChars: number;
referencedFiles: number; // 该维度引用了哪些文件
durationMs: number;
}>;
episodicData: Record<string, unknown> | null; // SessionStore 快照
isIncremental: boolean;
parentId: string | null; // 增量链父节点
}关键的两个字段:
- fileHashes:每个文件的 SHA-256 哈希。下次 Bootstrap 时逐一比对,就能精确知道哪些文件变了。
- dimensionMeta.referencedFiles:每个维度在分析时引用了哪些源文件。这建立了"维度↔文件"的映射,是增量判定的核心。
快照最多保留 5 份(MAX_SNAPSHOTS = 5),循环覆盖。
增量评估三步骤
// IncrementalBootstrap.evaluate()
// 1. 加载上次快照
const previousSnapshot = snapshot.getLatest(projectRoot);
// 2. 计算文件 Diff
const diff = snapshot.computeDiff(previousSnapshot, currentFiles, projectRoot);
// → { added: ['NewFile.swift'], modified: ['UserService.swift'],
// deleted: ['OldHelper.swift'], unchanged: [...], changeRatio: 0.03 }
// 3. 推断受影响维度
const inference = snapshot.inferAffectedDimensions(
previousSnapshot, diff, allDimIds
);
// → { mode: 'incremental', dimensions: ['code-pattern', 'architecture'],
// skippedDimensions: ['security-auth', 'testing-quality', ...] }Step 1:加载快照。如果没有历史快照,退回全量模式。
Step 2:文件 Diff。逐文件比对 SHA-256 哈希,分为 added / modified / deleted / unchanged 四类。计算 changeRatio = changes / total。
Step 3:维度推断。这是最精妙的部分。系统通过"维度→文件"映射反向查找:
UserService.swift 被修改
→ 上次 bootstrap 中,哪些维度引用了 UserService.swift?
→ code-pattern (是), architecture (是), testing-quality (否)
→ 只需重新分析 code-pattern 和 architecture三个特殊规则:
- 50% 全量重建阈值:如果
changeRatio > 0.5,变更太多,增量不再有意义——退回全量 - 新文件维度推断:
added文件不在旧快照的映射中,系统根据文件类型推断可能关联的维度(.test.swift→testing-quality) - project-profile 总是重新分析:只要有任何文件变更,
project-profile维度就需要刷新
增量模式下,未受影响维度的 EpisodicMemory 从快照中恢复:
if (previousSnapshot.episodicData) {
restoredEpisodic = SessionStore.fromJSON(previousSnapshot.episodicData);
}SessionStore(Agent 记忆)保存了每个维度分析时的工作记忆。恢复后,跳过的维度仍然"记得"上次的分析结论,响应搜索和 Guard 引用时不会丢失上下文。
运行时行为
一次完整冷启动的时间线,以一个 365 个 Swift 文件的 iOS 项目为例:
T+0ms Phase 0 ── fullReset() 清理 8 张表 + 衍生文件
T+80ms Phase 1 ── 文件收集 365 files, 12 targets (SPM)
T+280ms Phase 1.5 ── AST 分析 142 classes, 28 protocols
T+580ms Phase 1.6 ── Entity Graph 342 entities, 1205 edges
T+1100ms Phase 1.7 ── Call Graph 836 call edges, resolution 72%
T+1300ms Phase 2 ── 依赖图 18 module edges
T+1400ms Phase 2.1 ── Module 实体 18 modules upserted
T+1700ms Phase 2.2 ── Panorama 4 layers, 2 coupling hotspots
T+1900ms Phase 3 ── Guard 审计 12 violations, 0 errors
T+1950ms Phase 4 ── 维度解析 15 active dimensions
─────────────────── 同步返回(~2s)────────────────────
T+2000ms Phase 5 ── FanOut 开始
T+2000ms ├── Tier 1 (×3): code-pattern, coding-standards, best-practice
T+35s ├── Tier 1 完成: 28 candidates
T+35s ├── Tier 2 (×2): architecture, project-profile
T+65s ├── Tier 2 完成: project skill generated
T+65s ├── Tier 3 (×1): swift-objc-idiom, swiftui-pattern, ...
T+120s └── Phase 5 全部完成: 42 candidates, 3 skills
T+120s Phase 5.5 ── Skill 聚合写入
T+125s bootstrap:all-completed同步阶段约 2 秒返回骨架——用户立即看到项目结构分析报告。异步阶段约 2 分钟完成全部维度分析和知识填充——Dashboard 实时展示每个维度的进度。
外部 Agent 路径没有 Phase 5 的自动执行,但 Mission Briefing 提供了完整的执行计划——IDE Agent 会自行逐维度分析,总耗时取决于 IDE Agent 的速度和上下文窗口大小。
权衡与替代方案
为什么不用纯 AI 分析
一个看似更简单的方案:把所有源码喂给 LLM,让它直接输出项目知识。不需要 AST、不需要调用图、不需要 14 个阶段。
不这样做的原因是 SOUL 的"确定性标记 + 概率性消解"原则:
- 成本:一个 365 文件的项目,如果全部喂给 LLM 分析,Token 成本可能是数十美元。AST 做的工作(类提取、调用关系、依赖图)零 Token 成本。
- 准确性:AST 提取的是确定性事实——类 A 继承自类 B、方法 X 调用方法 Y。LLM 的"发现"是概率性的,可能遗漏也可能幻觉。
- 速度:Phase 1–4 在 2 秒内完成。如果等 LLM 分析同样的信息,需要数分钟。
- 离线可用:Phase 1–4 不需要网络。用户可以在飞机上做项目扫描,回到网络后再补充 AI 分析。
AI 的价值在于理解——识别设计模式的意图、判断代码风格的合理性、生成结构化的知识描述。这些是 AST 做不到的。所以 AI 在 Phase 5 登场,站在 Phase 1–4 已经准备好的确定性上下文之上。
为什么阶段如此细粒度
把 14 个阶段合并成"扫描→分析→生成"三步也能工作。细粒度的好处是:
- 恢复精度:中断后只需从断点续跑,不用重新开始整个阶段
- 进度可视:用户能看到"正在构建调用图"而不只是"正在分析..."
- 独立调试:某个阶段有 bug 时可以单独重跑,不用重新收集文件
- 增量基础:增量判定需要知道"这个维度上次引用了哪些文件"——粒度越细,增量就越精确
代价是编排复杂度更高。BootstrapTaskManager、BootstrapSnapshot、IncrementalBootstrap 三个组件的存在,纯粹是为了管理这种复杂度。如果管线只有 3 步,这些管理组件都不需要。
这是一个在实用层面经过验证的权衡:冷启动是用户的第一次体验,进度可视和快速恢复对首次印象至关重要。
为什么允许无 AI 的 Bootstrap
外部 Agent 路径证明了一个架构约束:Phase 1–4 的输出本身就是有价值的。即使没有 Phase 5 的 AI 填充,用户也得到了:
- 项目结构全景图(Panorama)
- 代码实体图和调用图
- Guard 基线审计报告
- 模块依赖拓扑
这些确定性产出可以独立使用——Panorama 可以帮助理解项目架构,Guard 审计可以作为代码质量基线。知识提取是增值,不是前提。
小结
Bootstrap 是 Alembic 系统中编排复杂度最高的流程。它的核心设计思路可以归结为三点:
- 工程先行,AI 增值:Phase 0–4 纯确定性计算,2 秒内完成项目"CT 扫描"。Phase 5 的 AI 分析建立在结构化上下文之上,而非从零推理。
- 双路径统一基座:内部 Agent 和外部 Agent 共享 Phase 0–4 的分析逻辑(
runAllPhases),仅在知识填充阶段分流。这避免了两套独立管线的维护负担。 - 精确增量:BootstrapSnapshot 记录"维度↔文件"映射,下次变更时只重新分析受影响的维度。50% 变更率阈值确保增量判定不会弄巧成拙。
下一章我们将看到知识库建立之后的另一个核心服务——Guard 如何用四层检测架构确保生成代码的合规性。