SOUL 原则 — 知识引擎的身份约束
SOUL.md 不是文档,是代码中随处可见的工程决策。
问题场景
Alembic 不是通用 AI 平台,它有明确的边界。但边界在哪?谁来守?
一个做知识管理的系统,天然面临这样的张力:AI 想要尽可能多地产出——因为 Agent 的"成就感"来自每次交互都留下点什么;而开发者需要的是高质量的、可信赖的知识积累——一条错误的 Recipe 进入知识库,会让所有团队成员的 AI 助手都学到错误的写法。
如果系统的每个模块各自为政地定义"什么该做、什么不该做",最终会出现不一致的行为——某个模块允许的操作在另一个模块被拒绝,或者更危险的,某个角落悄悄突破了安全约束,让 AI 绕过审核直接发布了一条未经验证的知识。
SOUL 是 Alembic 的身份宪章,对应仓库根目录的 SOUL.md 文件。它回答一个根本问题:这个系统是什么,不是什么。
I am a knowledge base curator — I help developers distill valuable
code patterns from their projects into reusable Recipes.
I am not a general-purpose AI assistant.这段自我定义不是给人看的文档——它被注入到 Agent 的 System Prompt 中,成为每次 AI 推理的边界约束。在此基础上,SOUL 以三条不可违反的硬约束和五项设计哲学构成了整个系统的工程决策地基。
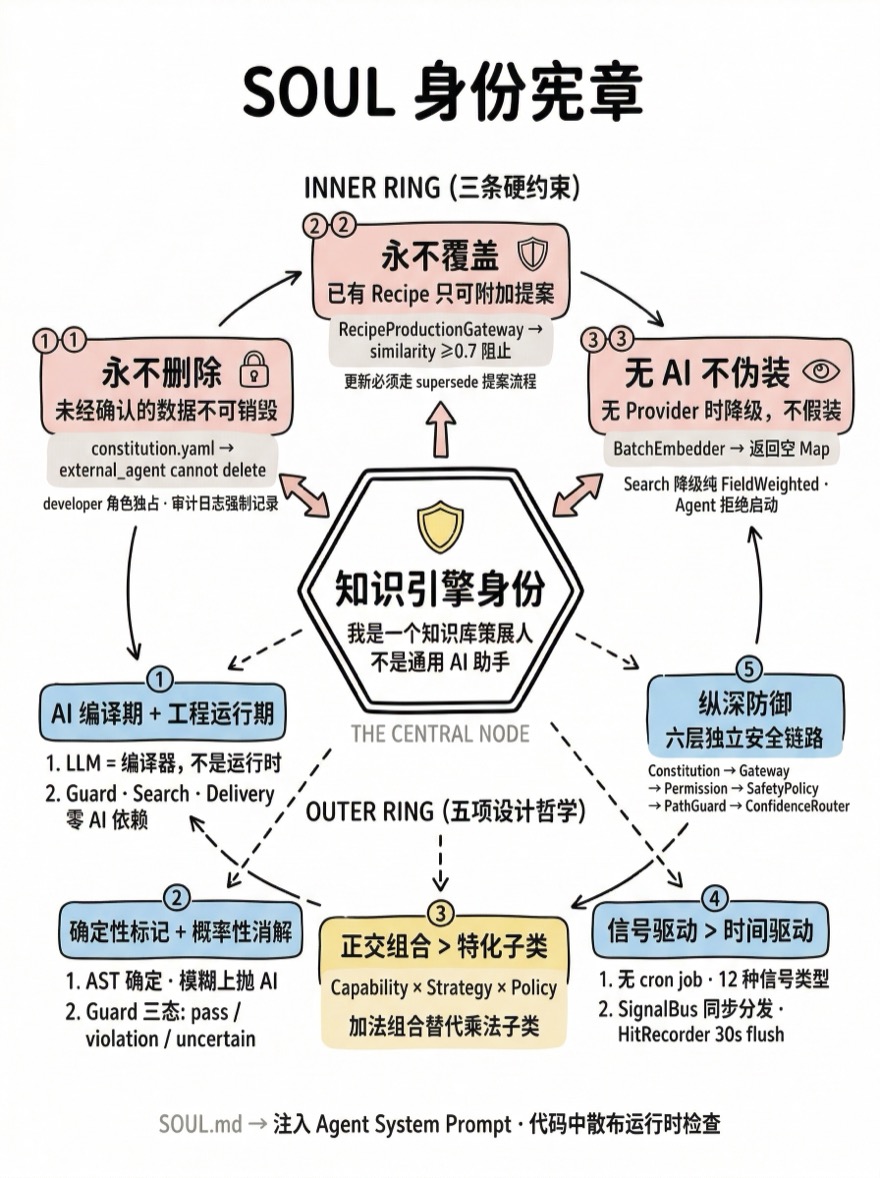
三条硬约束
SOUL 定义了三条 non-negotiable 的硬约束。它们不是代码注释里的善意提醒,而是散布在多个模块中的运行时检查——违反任何一条,操作会被立即拦截。
约束一:永不删除用户未确认的数据
这条约束的核心不是"禁止删除",而是"删除必须追溯"。KnowledgeService.delete() 的实现揭示了这一点:
// lib/service/knowledge/KnowledgeService.ts
async delete(id: string, context: ServiceContext) {
const entry = await this._findOrThrow(id);
this._removeFile(entry); // 删除 .md 文件
this._removeAllEdges(id); // 清除知识图谱边
this._removeRelatedProposals(id); // 清除进化提案
await this.repository.delete(id);
// 关键:审计日志强制记录
await this._audit('delete_knowledge', id, context.userId, {
title: entry.title,
});
}删除操作首先通过 _findOrThrow() 验证条目存在(不能凭空删除),然后清理所有关联数据(edges、proposals),最后通过 _audit() 在审计日志中留下不可回避的记录。更重要的是,这个方法只有 developer 角色能调用——constitution.yaml 中明确定义了 external_agent 的约束:
# config/constitution.yaml
roles:
- id: "external_agent"
constraints:
- "cannot delete any data"AI Agent 无权执行删除操作。只有项目 owner(developer 角色,permissions: ["*"])才有权销毁知识。
约束二:永不覆盖现有 Recipe 内容
已有的 Recipe 是团队审核通过的知识资产。即使 AI 发现了"更好的写法",也不能直接修改已有的 Recipe——它必须通过 Evolution Proposal 机制附加提案,由人工决策是否接受。
RecipeProductionGateway 在创建新 Recipe 时执行相似度检查:
// lib/service/knowledge/RecipeProductionGateway.ts
// Step 2: Similarity Check — 去重防止覆盖
const similar = this.#findSimilarRecipes(this.#projectRoot, cand, {
threshold: 0.5,
topK: 5,
});
const hasDuplicate = similar.some((s) => s.similarity >= threshold);
if (hasDuplicate) {
result.duplicates.push({
index,
title: item.title || '(untitled)',
similarTo: similar,
});
// 重复项被阻止创建,而非覆盖
}当新提交的知识与已有 Recipe 相似度 ≥ 0.7 时,系统不会覆盖旧 Recipe,而是将其标记为重复并阻止创建。如果确实需要更新,必须走 supersede 提案流程——旧 Recipe 保持 active,新提案进入 pending,等待人工审核。
这个设计的哲学是:知识的更新应该是显式的、可追溯的、经过人工确认的。即使 AI 的判断是正确的,覆盖操作本身也不应是静默的。
约束三:无 AI 不伪装
系统在没有配置 AI Provider 的情况下,必须坦诚自己的能力边界,而不是假装拥有 AI 能力然后返回低质量结果。
// lib/infrastructure/vector/BatchEmbedder.ts
async embedAll(items: Array<{ id: string; content: string }>) {
if (!this.#aiProvider || typeof this.#aiProvider.embed !== 'function') {
return new Map(); // 无 AI 时返回空 Map,不假装能嵌入
}
// ... 正常批量嵌入逻辑
}BatchEmbedder 在每次调用时检查 AI Provider 是否存在且有效。没有 AI 时,向量嵌入返回空结果,搜索引擎自动降级到纯 FieldWeighted 字段加权检索——功能受限但结果可靠,而不是用随机向量假装语义相关性。
这条约束贯穿整个系统:Search 引擎在无 AI 时跳过语义 rerank,Agent 在无 AI Provider 时拒绝启动推理循环。宁可少做,不可假做。
设计哲学一:AI 编译期 + 工程运行期
这是最反直觉但最重要的设计决策。
大多数 AI 工具把 LLM 放在关键路径上——每次操作都调用 AI,导致延迟不可预测、结果不可复现、离线不可用。Alembic 反其道而行:LLM 的角色是"编译器",不是"运行时"。
类比传统软件开发:
| 阶段 | 传统软件 | Alembic |
|---|---|---|
| 编译期 | 编译器将源码翻译为机器码 | LLM 将代码模式翻译为 Recipe / Guard 规则 / Evolution 提案 |
| 运行期 | CPU 执行机器码,不需要编译器 | 搜索、合规检查、交付执行 Recipe,不需要 LLM |
这意味着 AI 只在两个阶段被调用:冷启动(Bootstrap 扫描项目、提取模式)和进化(Evolution Proposal 的生成)。一旦知识被"编译"为 Recipe,之后的一切操作都是纯工程逻辑。
Guard 引擎:零 AI 依赖
Guard 是这一哲学最清晰的体现。它的合规检查完全由编译期定义的规则驱动:
// lib/service/guard/GuardCheckEngine.ts
const BUILT_IN_RULES = {
'main-thread-sync-swift': {
message: '禁止在主线程上使用 DispatchQueue.main.sync,易死锁',
severity: 'error',
pattern: 'DispatchQueue\\.main\\.sync', // 纯正则,不调 AI
languages: ['swift'],
},
'swift-force-cast': {
message: '强制类型转换 as! 在失败时崩溃,建议 as?',
severity: 'warning',
pattern: 'as\\s*!',
languages: ['swift'],
},
// 所有规则都是编译期写死的正则/AST 模式
};内置规则用正则和 AST 模式匹配做确定性检测,零 LLM 调用。自定义规则来自 Recipe 的 doClause / dontClause / coreCode 字段——这些是 AI 在"编译期"产出的结构化约束,运行时只需做模式匹配。
结果是:Guard 检测延迟可预测(O(n) 正则匹配),可用于 CI 管线秒级反馈,且完全离线可用。
Search 引擎:AI 可选增强
搜索引擎的核心路径同样不依赖 LLM:
// lib/service/search/SearchEngine.ts
async search(query: string, options: SearchOptions = {}) {
// 1. FieldWeighted recall — 纯工程,无 AI
const weightedResults = this.scorer.search(query);
// 2. Signal reinforcement — 纯工程(usage/guard/quality 信号)
const signalBoosted = this._multiSignalRanker.rank(weightedResults);
// 3. Semantic rerank — 可选 LLM,skipIfNoProvider
if (this.aiProvider && options.useSemanticRanking) {
return await this._semanticRerank(signalBoosted);
}
return signalBoosted; // 无 AI 也能返回有效结果
}步骤 1–2(FieldWeighted 召回 → 信号增强)是 O(n log k) 的确定性算法。语义 rerank 是第 3 步的可选增强——有 AI 时更精准,没有 AI 时仍然返回高质量结果。
为什么这很重要
这个设计决策带来三个关键收益:
- 可预测性 — 同样的 Recipe 和同样的代码输入,Guard 永远返回同样的结果。不会因为 LLM 温度参数不同而今天 pass 明天 violation。
- 可测试性 — Guard 规则和 Search 排序都可以写确定性单元测试,不需要 mock LLM 响应。
- 离线可用 — 断网时,知识库的搜索、合规检查、IDE 交付全部正常工作。AI 连接只影响"编译"新知识的能力。
设计哲学二:确定性标记 + 概率性消解
系统中有两类问题:一类有确定答案("这个类继承自哪个父类"),一类没有("这个模式是否值得提取为团队规范")。SOUL 的第二项哲学要求严格区分二者——用工程做确定的事,只把真正不确定的部分交给 AI。
AST:确定性标记
Tree-sitter 解析产出的结构信息是确定性的:
- 类
UserRepository继承自BaseRepository— 确定 - 方法
fetchUser()调用了apiClient.get()— 确定 - 代码匹配 Singleton 模式(静态
shared属性 + private init)— 确定
这些结构化数据构成"标记"——它们被写入 Panorama 数据库,任何模块都可以查询,结果不存在歧义。
AI:概率性消解
不确定的问题才上抛给 AI:
- 这个 Singleton 模式值得提取为 Recipe 吗?(取决于它是否是团队约定)
- 这两个相似的网络请求封装应该合并还是保留?(取决于业务场景)
- 置信度 0.6 的知识应该自动发布还是等人工审核?(取决于风险偏好)
Guard 的三态输出
Guard 引擎将这一哲学实现为三态输出——不是简单的"通过/不通过",而是诚实地承认自己的能力边界:
// lib/service/guard/UncertaintyCollector.ts
//
// 三态输出:
// - pass → 规则检查通过(确定)
// - violation → 检测到违反(确定)
// - uncertain → 检查跳过,能力边界(诚实)
export interface GuardCapabilityReport {
executedChecks: {
regex: { total: number; executed: number; skipped: number };
codeLevel: { total: number; executed: number; skipped: number };
ast: { total: number; executed: number; skipped: number };
crossFile: { total: number; executed: number; skipped: number };
};
uncertainResults: UncertainResult[];
checkCoverage: number; // 0-100 覆盖率
}当 Guard 的正则层或 AST 层无法判断时(比如规则需要跨文件的语义理解,但当前只有单文件上下文),它不会勉强给出 pass 或 violation,而是如实报告 uncertain,交由开发者或更高层的 AI 决策。
UncertaintyCollector 追踪每一层的跳过原因(SkipLayer + SkipReason),最终产出包含检查覆盖率的结构化报告。这个覆盖率数字本身就是一个信号——如果某个文件的 Guard 覆盖率只有 40%,说明现有规则对这类代码的约束能力不足,是知识库应该查漏补缺的方向。
衰退评分:确定性指标 → 概率性决策
DecayDetector 用 6 种确定性策略评估知识的健康状态:
// lib/service/evolution/DecayDetector.ts
//
// 衰退评分 (decayScore 0–100):
// freshness(0.3) + usage(0.3) + quality(0.2) + authority(0.2)
//
// 80–100: 健康
// 60–79: 关注 → Dashboard 警告
// 40–59: 衰退 → active → decaying
// 0–19: 死亡 → 跳过确认直接 deprecated
// 策略 1: 90 天无使用
if (daysSince > 90) {
signals.push({ strategy: 'no_recent_usage', ... });
}
// 策略 2: 高误报率(触发 >10 次且失误率 >40%)
if (fpRate > 0.4 && triggers > 10) {
signals.push({ strategy: 'high_false_positive', ... });
}每个策略的判断是确定的("90 天无使用"没有歧义),但最终的衰退决策是多信号加权的概率性结论。评分 53 和评分 62 只差一个区间,但前者触发衰退转换而后者只是警告——这个阈值是设计决策,不是绝对真理。
设计哲学三:正交组合 > 特化子类
Alembic 的 Agent 系统需要处理多种截然不同的任务:与用户聊天、深度分析代码、批量提取知识、远程执行命令。直觉上应该设计 ChatAgent、AnalysisAgent、BootstrapAgent 三个子类,对吧?
SOUL 的第三项哲学否决了这个方案。原因不是子类"不好",而是子类的维度会爆炸。
维度爆炸问题
如果用子类,三种任务需要三个 Agent。但每种任务还有不同的安全策略(标准预算 vs 深度预算 vs 短预算 + 安全沙箱)、不同的执行策略(单轮 vs 并行扇出 + 管道汇聚 vs 回溯)。3 任务 × 3 预算 × 3 策略 = 27 个子类。每新增一个维度,子类数量乘法增长。
正交组合方案
Alembic 用 Capability × Strategy × Policy 三维正交组合替代继承树:
// lib/agent/AgentFactory.ts
createRuntime(presetName: string, overrides: RuntimeOverrides = {}) {
const preset = getPreset(presetName, overrides);
// 正交维度 1: Capabilities(能力集)
const capabilities = (preset.capabilities as string[]).map((name) => {
return CapabilityRegistry.create(name, this.#getCapabilityOpts(name));
});
// 正交维度 2: Policies(横切约束)
const resolvedPolicies = (preset.policies || []).map((policyOrFactory) =>
typeof policyOrFactory === 'function' ? policyOrFactory(overrides) : policyOrFactory
);
const policyEngine = new PolicyEngine(resolvedPolicies);
return new AgentRuntime({
capabilities, // 组合多个能力
strategy: preset.strategyInstance, // 单一执行策略
policies: policyEngine, // 多个约束叠加
});
}AgentFactory 根据 Preset 名称(chat / insight / remote-exec)组装出完全不同的 Agent 实例,但底层都是同一个 AgentRuntime 引擎。差异仅在于三个正交维度的配置:
| Preset | Capabilities | Strategy | Policies |
|---|---|---|---|
chat | Conversation + CodeAnalysis | Single | StandardBudget |
insight | CodeAnalysis + KnowledgeProduction | FanOut + Pipe | DeepBudget + Quality |
remote-exec | Conversation + CodeAnalysis + SystemInteraction | Single | ShortBudget + Safety |
Capability:可复用的能力模块
每个 Capability 提供三样东西:系统提示词片段、工具白名单、生命周期钩子。
// lib/agent/capabilities.ts
//
// 组合示例:
// 用户聊天 = Conversation + CodeAnalysis
// 冷启动分析 = CodeAnalysis + KnowledgeProduction
// 飞书远程执行 = Conversation + SystemInteraction
// 智能全能 = Conversation + CodeAnalysis + KnowledgeProduction + SystemInteraction
export class Conversation extends Capability {
get name() { return 'conversation'; }
get promptFragment() {
return `## 对话能力\n你是 Alembic 知识管理助手...`;
}
get tools() {
return ['search_knowledge', 'search_recipes', 'get_recipe_detail', 'submit_knowledge'];
}
}"飞书聊天"和"前端 Dashboard 聊天"不是两个 Agent——它们是同一个 chat Preset,只是 Transport 层不同。安全约束由 SafetyPolicy 提供,不需要硬编码到某个 Agent 子类里。
收益
- 新增能力只需新建一个 Capability 类,所有 Preset 都可以组合使用
- 新增约束只需新建一个 Policy 类,叠加到任何 Preset
- 每个维度独立测试,Conversation 能力的测试不需要关心安全策略
- 组合数量 = 加法而非乘法:5 Capabilities + 3 Strategies + 4 Policies = 12 个组件,可配出数十种 Agent 变体
设计哲学四:信号驱动 > 时间驱动
很多系统用定时任务扫描状态变化——每天凌晨跑一遍衰退检测,每小时更新一次质量评分。Alembic 的第四项哲学是:没有 cron job,一切由使用信号触发。
SignalBus:同步分发、异常隔离
// lib/infrastructure/signal/SignalBus.ts
export type SignalType =
| 'guard' | 'guard_blind_spot' | 'search' | 'usage'
| 'lifecycle' | 'exploration' | 'quality' | 'panorama'
| 'decay' | 'forge' | 'intent' | 'anomaly';
export class SignalBus {
emit(signal: Signal): void {
const exact = this.#listeners.get(signal.type);
if (exact) {
for (const handler of exact) {
try {
handler(signal); // 同步调用
} catch {
// 消费者异常不阻断信号分发
}
}
}
}
}12 种信号类型覆盖系统的所有状态变化。SignalBus 的设计有两个关键特性:
- 同步分发(< 0.1ms per emit)——信号即发即消,不排队、不缓冲
- 异常隔离——消费者的
catch {}确保一个订阅者的崩溃不会阻断其他订阅者收到信号
HitRecorder:事件驱动的批量落盘
高频使用信号(Guard 命中、搜索命中、采纳)通过 HitRecorder 采集:
// lib/service/signal/HitRecorder.ts
record(recipeId: string, eventType: HitEventType, value = 1) {
// 1. 即时发射信号 — 不延迟
this.#bus.send(EVENT_TO_SIGNAL_TYPE[eventType], `HitRecorder.${eventType}`, value, {
target: recipeId,
});
// 2. 聚合进内存 buffer(减少 SQLite 写入)
const key = `${recipeId}:${eventType}`;
const existing = this.#buffer.get(key);
if (existing) {
existing.count++;
existing.lastAt = Date.now();
} else {
this.#buffer.set(key, { recipeId, eventType, count: 1, ... });
}
// 3. 缓冲满时事件驱动 flush
if (this.#buffer.size >= this.#maxBufferSize) {
void this.flush();
}
}设计很精妙:信号即时发射(订阅者实时反应),但持久化批量进行(30 秒 flush 到 SQLite)。信号的实时性和存储的效率兼顾。shutdown hook 保证进程退出前执行最后一次 flush,不丢数据。
信号驱动 vs 时间驱动的对比
| 场景 | 时间驱动 | 信号驱动(Alembic 的做法) |
|---|---|---|
| 知识衰退 | 每天凌晨扫描一次 | 90 天无 guardHit / searchHit 信号时触发 |
| 质量更新 | 每小时重算评分 | 采纳信号(adoption)触发增量更新 |
| 进化提案 | 定期批量跑分析 | 矛盾检测信号触发定向分析 |
信号驱动的优势是精确性——只有真正发生变化的知识才会被重新评估,而不是每次都全量扫描。一个 1000 条 Recipe 的知识库,如果今天只有 3 条被使用,那么只有这 3 条会产生信号、触发评分更新。
DecayDetector 的信号回路
衰退检测是信号驱动架构的一个完整回路:
// lib/service/evolution/DecayDetector.ts
async scanAll(): Promise<DecayScoreResult[]> {
const recipes = await this.#loadActiveRecipes();
const results: DecayScoreResult[] = [];
for (const recipe of recipes) {
const result = await this.evaluate(recipe);
results.push(result);
}
// 发射衰退信号 → 其他模块订阅并反应
if (this.#signalBus) {
for (const r of results) {
if (r.level !== 'healthy') {
this.#signalBus.send('decay', 'DecayDetector', 1 - r.decayScore / 100, {
target: r.recipeId,
metadata: { level: r.level, signals: r.signals.map((s) => s.strategy) },
});
}
}
}
return results;
}scanAll() 不是一个定时任务——它是一个业务事件,由 CLI 命令、API 调用或外部任务按需触发。触发后发射 decay 信号,Dashboard 订阅后显示衰退警告,Lifecycle 订阅后执行状态转换(active → decaying)。整个链条由一个信号驱动,而非多个定时任务各扫各的。
设计哲学五:纵深防御
Alembic 通过 MCP 协议暴露工具给外部 AI Agent(Cursor、Copilot、Claude Code)。这意味着每个 MCP 调用的发起者本质上是一个你无法完全信任的 AI 模型——它可能被 prompt injection 操纵,可能在多轮对话中逐步试探权限边界。
单层安全检查在这种场景下是不够的。如果权限检查只发生在 API 入口,那么绕过入口的操作(比如 Agent 直接调用内部方法)就没有防护。如果只检查文件路径但不检查操作权限,那么有路径访问权的 Agent 就能执行任意操作。
SOUL 的第五项哲学要求六层独立防御,每层解决一个特定维度的安全问题:
请求 → Constitution → Gateway → Permission → SafetyPolicy → PathGuard → ConfidenceRouter
↓ ↓ ↓ ↓ ↓ ↓
规则定义 4步管线 3-tuple权限 命令黑名单 文件沙箱 质量门控| 层级 | 组件 | 防御维度 | 一句话描述 |
|---|---|---|---|
| 1 | Constitution | 规则与角色 | YAML 定义 5 种角色的权限边界和硬规则 |
| 2 | Gateway | 请求管线 | validate → guard → route → audit,所有操作的唯一入口 |
| 3 | PermissionManager | 权限验证 | 3-tuple (actor, action, resource) 精确匹配 |
| 4 | SafetyPolicy | Agent 行为 | 命令黑名单拦截 rm -rf、sudo 等危险操作 |
| 5 | PathGuard | 文件系统 | 双层边界检查,只允许写入白名单目录 |
| 6 | ConfidenceRouter | 知识质量 | 低置信度知识不得自动发布 |
前三层守护"谁能做什么",第四层守护"Agent 能执行什么命令",第五层守护"能写到哪里",第六层守护"什么质量的知识能上线"。六个维度正交,每层独立记录审计日志,任何一层的失败都足以阻断请求。
六层安全链的详细实现将在 Ch04 安全管线 中深入展开。此处仅给出 PathGuard 的示例,因为它最直观地体现了纵深防御的设计动机:
// lib/shared/PathGuard.ts
assertProjectWriteSafe(filePath: string) {
// Layer 1: 边界检查 — 不能写到项目根目录之外
if (!filePath.startsWith(this.#projectRoot!)) {
throw new PathGuardError(filePath, this.#projectRoot!, 'Path escapes project root');
}
// Layer 2: 作用域检查 — 项目内也只能写到白名单目录
const relative = path.relative(this.#projectRoot!, filePath);
const isAllowed = PROJECT_WRITE_SCOPE_PREFIXES.some((prefix) =>
relative.startsWith(prefix)
);
if (!isAllowed) {
throw new PathGuardError(filePath, this.#projectRoot!,
`Path outside allowed write scopes: ${relative}`);
}
}即使 Agent 有 external_agent 角色的写入权限(通过了第 1-3 层),它仍然只能写入 .asd/、.cursor/、.vscode/、.github/ 等白名单目录。想要写入 src/ 或任何业务代码目录?PathGuard 会直接抛出异常。
SOUL 如何被执行
SOUL 原则不是写在文档里的美好愿景。它通过三条路径被代码强制执行:
路径一:Agent System Prompt 注入
每次 Agent 启动推理循环时,SOUL.md 的核心内容被注入到 System Prompt 中。这意味着 AI 从第一轮推理开始就受到身份约束——"我是知识库管理员,不是通用助手"。
路径二:Constitution 规则映射
SOUL 的三条硬约束被映射为 constitution.yaml 中的可执行规则:
rules:
- id: "destructive_confirm"
check: "destructive_needs_confirmation" # 约束一:删除需确认
- id: "ai_no_direct_recipe"
check: "ai_cannot_approve_recipe" # 约束二:AI 不能直接发布
- id: "content_required"
check: "creation_needs_content" # 约束三:不能提交空内容Gateway 在每次请求的 guard 阶段加载这些规则并执行检查。规则是数据(YAML),不是硬编码——修改约束只需改配置文件,不需要改代码。
路径三:Guard 合规检查
Guard 引擎本身就是 SOUL 哲学的产物——它的设计决策(四层检测、三态输出、零 AI 依赖)都直接体现了"确定性标记 + 概率性消解"和"AI 编译期 + 工程运行期"两项哲学。Guard 在检查用户代码的同时,也在践行 SOUL 对系统自身的要求。
小结
五项设计哲学不是独立的——它们相互支撑,形成一个自洽的工程体系:
- AI 编译期 + 工程运行期 决定了系统的可靠性基线:核心路径不依赖 AI
- 确定性标记 + 概率性消解 决定了 AI 的使用方式:只在不确定时才引入
- 正交组合 决定了系统的扩展方式:新增能力是加法,不是乘法
- 信号驱动 决定了系统的响应方式:按需反应,而非定时扫描
- 纵深防御 决定了系统的安全方式:六层独立检查,任何一层足以拦截
这五项哲学的共同主题是约束。与其让系统无所不能然后到处打补丁,不如从一开始就明确边界,在边界内做到极致。SOUL 不是限制——它是让系统在有限范围内做出最优决策的前提。
从下一章开始,我们将进入 Part II——工程基石。首先是架构全景:看看这些哲学如何落地为 7 层分层架构、9 个 DI 模块和严格的单向依赖规则。