Panorama · Signal · 知识代谢
系统的自我感知能力 — 从项目全景到信号驱动的知识新陈代谢。
问题场景
知识库不是独立存在的,它需要感知两件事:
- 项目长什么样——哪些模块是核心的、哪些是边缘的、模块之间的耦合度如何。没有这个全景,知识覆盖就像盲人摸象——可能为一个工具模块写了 20 条 Recipe,核心业务层却一片空白。
- 知识被怎么用——哪些 Recipe 被频繁搜索、哪些 Guard 规则经常命中、哪些知识从没被引用过。没有这些信号,系统不知道哪些知识在增值、哪些在腐烂。
更深一层的问题是:感知到之后怎么办?知道"Payment 模块零覆盖"之后呢?知道"某条 Recipe 90 天没人用"之后呢?
这就引出了第三个需求:知识代谢——基于全景和信号,自动产生衰退检测、冗余分析、进化提案。不是被动等待人工审查,而是系统主动发现问题并给出治理方案。
三个子系统、一条数据链路:
Panorama(感知项目)→ Signal(捕获行为)→ Metabolism(驱动进化)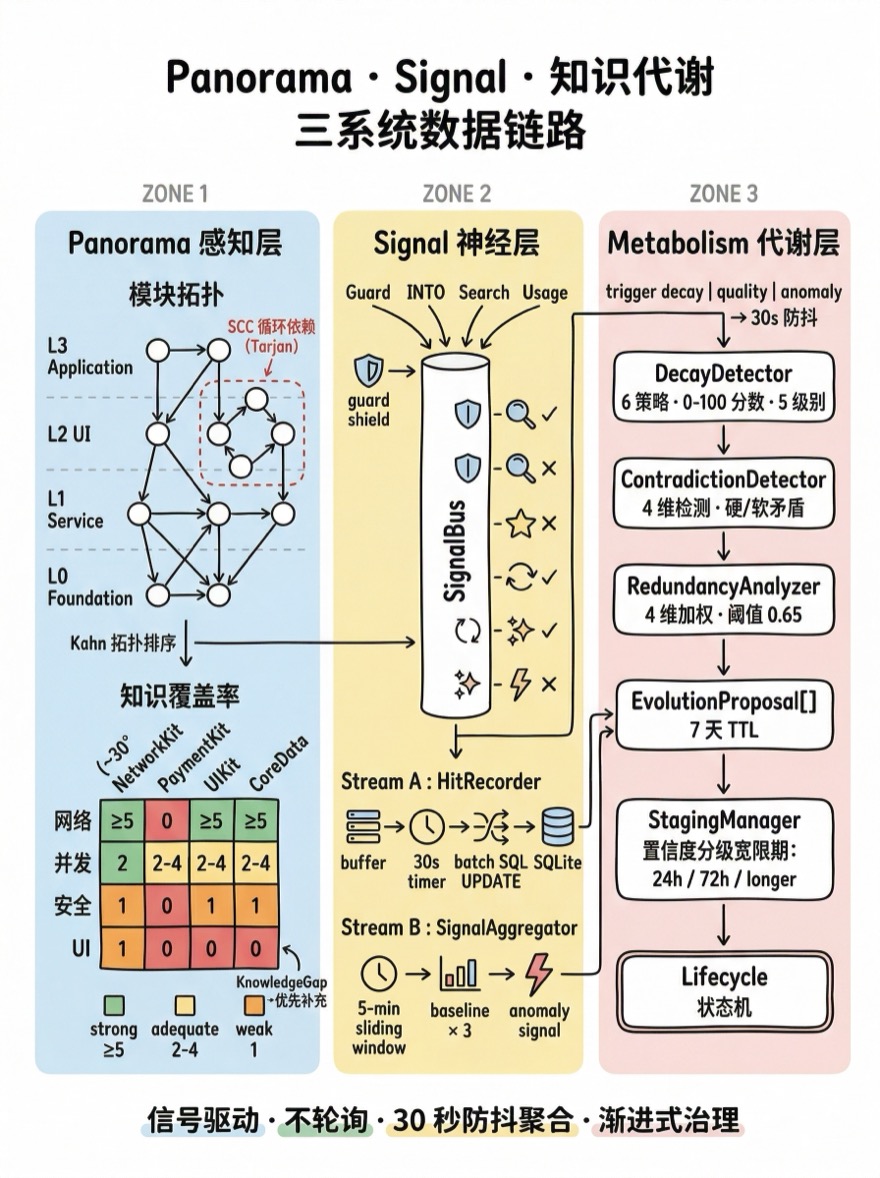
Panorama:项目全景
模块发现与拓扑
Panorama 的第一步是发现模块。ModuleDiscoverer 用两种策略识别项目的模块结构:
策略 1(主路径):从 AST 实体图中加载 entity_type='module' 的节点,配合 is_part_of 边推导模块层级。这依赖 Ch05 中的结构分析链——如果 Bootstrap 已经扫描过项目,模块信息直接在数据库中。
策略 2(降级):如果模块存在但文件列表为空,从文件系统和数据库路径中补全。对于 SPM(Swift Package Manager)项目,从 Package.swift 的 target 声明中提取模块定义。
CustomConfigDiscoverer — 构建系统指纹识别
标准的包管理器(npm、SPM、Gradle)有统一的项目描述文件,解析它们就能发现模块。但很多真实项目使用非标准构建系统——百度的 EasyBox、快手的 KSComponent、美团的 MTComponent、Tuist、Bazel、Buck2 等。这些系统有各自的项目描述 DSL,ModuleDiscoverer 无法直接识别。
CustomConfigDiscoverer 通过两级指纹匹配解决这个问题:
Tier 1 — 已知系统指纹(置信度 0.70–0.85)
系统内置了 16 种构建系统的指纹特征——标记文件(marker files)、反标记文件(排斥条件)和模块规格文件模式:
| 类别 | 构建系统 | 标记文件 | 置信度 |
|---|---|---|---|
| Starlark | Bazel, Buck2 | MODULE.bazel / BUCK | 0.85 |
| iOS 生态 | EasyBox, Tuist, KSComponent, MTComponent, XcodeGen | Boxfile / Tuist/Config.swift / 各自配置文件 | 0.75–0.80 |
| Monorepo | Melos (Flutter), Nx | melos.yaml / nx.json | 0.80–0.82 |
| Hybrid | Flutter Add-to-App, React Native Hybrid, KMP | 各自配置组合 | 0.78 |
| 原生构建 | CMake, Gradle Convention Plugins | CMakeLists.txt / buildSrc/ | 0.75–0.80 |
每种系统有 markerStrategy('all' / 'any' / 'ordered')控制标记文件的匹配逻辑。antiMarkers 排除误匹配——例如 CMake 的检测会排除 Bazel 和 Pants 项目(它们可能包含 CMakeLists.txt 但不以 CMake 为主构建系统)。
Tier 2 — 启发式目录模式(置信度 0.50–0.65)
没有命中已知系统时,检查项目目录的结构特征:
| 信号 | 置信度加成 |
|---|---|
存在 Local?Modules?/ 或 Packages/ 目录 | +0.10 ~ +0.15 |
存在自定义 DSL 文件([A-Z]\w+file) | +0.20 |
存在 Spec 文件(.\w+spec) | +0.20 |
存在 .xcodeproj | +0.05 |
7 种多语言 DSL 解析器
识别构建系统后,需要从其配置文件中提取模块信息。7 种解析器覆盖了主流的 DSL 格式:
| 解析器 | 目标格式 | 适用系统 |
|---|---|---|
RubyDslParser | Ruby DSL(Boxfile, podspec) | EasyBox, KSComponent, MTComponent |
YamlConfigParser | YAML 配置 | Melos, XcodeGen |
SwiftDslParser | Swift DSL(Project.swift) | Tuist |
StarlarkParser | Starlark(BUILD.bazel, BUCK) | Bazel, Buck2 |
GradleDslParser | Gradle Kotlin DSL | Gradle Convention Plugins |
JsonConfigParser | JSON 配置 | Nx, Flutter, React Native |
CMakeParser | CMakeLists.txt | CMake |
解析器提取的是 ParsedModuleSpec——模块名、源文件路径、依赖列表——供 ModuleDiscoverer 后续消费。
用户自定义系统:如果项目使用了自研构建系统,可以在 boxspec.json 的 customDiscoverer 字段声明系统配置文件、模块 Spec 模式和解析器类型——CustomConfigDiscoverer 会优先使用用户配置。
发现模块后,CouplingAnalyzer 构建模块间的依赖图。图的边来自三种关系,权重不同:
| 关系类型 | 权重 | 含义 |
|---|---|---|
depends_on | 0.5 | import/include 语句 |
calls | 1.0 | 函数/方法调用 |
data_flow | 0.8 | 数据传递 |
calls 权重最高——两个模块之间的函数调用比 import 表达了更强的耦合关系。一个模块 import 了另一个但从不调用,耦合度远低于频繁调用。
Tarjan 强连通分量
有了加权依赖图,下一个问题:哪些模块之间存在循环依赖?
CouplingAnalyzer 用 Tarjan 算法找到图中所有强连通分量(SCC,Strongly Connected Components)。强连通分量中的所有节点可以互相到达——这就是循环依赖。
Tarjan 算法步骤:
对每个未访问节点:
strongConnect(node):
分配 index, lowlink ← index++
入栈
对每个邻居:
若未访问:递归 → 更新 lowlink
若在栈中:更新 lowlink 为 min
若 lowlink[node] = index[node]:
弹出直到 node → 形成一个 SCC大小 ≥ 2 的 SCC 就是循环依赖。算法同时计算每个模块的 fanIn(被多少模块依赖)和 fanOut(依赖多少模块)——高 fanIn 的模块是基础设施层,高 fanOut 的模块是胶水层或上帝模块。
CouplingAnalyzer 还做外部依赖分析——识别不在本项目中但被引用的模块(如 Alamofire、RxSwift),按 fanIn 降序排列。fanIn 最高的外部依赖是项目的技术栈核心。
Kahn 拓扑排序与层次推断
模块不是扁平的——它们有层次。底层是 Foundation/Core,中层是 Service/Networking,上层是 UI/Application。LayerInferrer 用两种模式推断层次:
模式 1:配置驱动(覆盖率 ≥ 50% 时)
如果项目有 boxspec.json 或 Bootstrap 配置声明了层次结构(如 BiliDili 项目的 foundation → services → networking → ui → application),直接使用配置。对于没有被配置覆盖的模块,通过依赖关系推导其层级。
模式 2:纯拓扑推断
没有配置时,用图算法推断层次:
- 移除循环(DFS 检测并断开回边)
- Kahn 拓扑排序(确保 DAG 有效)
- 最长路径计算(DFS + 记忆化)——从每个节点到汇点(无出边节点)的最长路径决定了它的层级
最长路径算法:
memo[node] = 从 node 到汇点的最长路径
dfs(node):
if memo[node] ≠ ⊥: return memo[node]
max ← 0
for neighbor ∈ edges[node]:
max ← max(max, 1 + dfs(neighbor))
return memo[node] ← max
layer[node] = maxPath - dfs(node)
// 汇点 layer = 0(底层),源点 layer = 最大值(顶层)层级名称通过模式匹配提供提示:
// lib/service/panorama/LayerInferrer.ts
LAYER_NAME_HINTS = [
{ pattern: /^(foundation|core|base|shared|common)$/i,
name: 'Foundation', bias: -2 }, // 底层
{ pattern: /network|api|http/i,
name: 'Networking', bias: 0 }, // 中间
{ pattern: /(?:^ui$|view|screen|component)/i,
name: 'UI', bias: 1 }, // 上层
{ pattern: /^(app|main|launch|entry)$/i,
name: 'Application', bias: 2 }, // 顶层
]推断还会检测层次违规——低层模块依赖高层模块的边。例如 Foundation 层 import 了 UI 层,这是架构分层的严重违反。
知识覆盖率与健康雷达
有了层次结构,Panorama 进入最关键的环节:评估每个维度的知识覆盖状况。
DimensionAnalyzer 从 DimensionRegistry 获取当前语言的所有知识维度(如 Swift 项目有"网络与 API"、"界面与交互"、"并发与异步"等),然后统计每个维度有多少 Recipe 覆盖:
| 状态 | 条件 | 含义 |
|---|---|---|
| strong | ≥ 5 条 Recipe | 覆盖充分 |
| adequate | 2–4 条 | 基本覆盖 |
| weak | 1 条 | 薄弱 |
| missing | 0 条 | 空白 |
每个维度的健康度还有四个级别(借鉴 ThoughtWorks Technology Radar):
- adopt:团队应该采纳的成熟知识
- trial:值得试用的新知识
- assess:需要评估的待定知识
- hold:应该暂停使用的过时知识
最终输出 HealthRadar——一个多维雷达图数据:
interface HealthRadar {
dimensions: HealthDimension[];
overallScore: number; // 0–100,维度评分的加权平均
totalRecipes: number;
coveredDimensions: number;
totalDimensions: number;
dimensionCoverage: number; // coveredDimensions / totalDimensions
}overallScore 是知识库健康的"体温计"——100 分意味着所有维度都达到 strong,50 分意味着一半维度缺乏覆盖。Dashboard 可以用这个分数显示一个直观的健康仪表盘。
知识空白检测
getGaps() 从 HealthRadar 中提取 missing 和 weak 状态的维度,生成 KnowledgeGap 列表:
interface KnowledgeGap {
dimension: string; // "并发与异步"
suggestedTopic: string; // "GCD/async-await 使用模式"
affectedModules: string[];// ["NetworkKit", "DataSync"]
priority: 'high' | 'medium' | 'low';
}高优先级的 gap 会出现在 Panorama 报告的显著位置——告诉用户"你的项目在这些方面没有知识覆盖,建议优先补充"。这把 Panorama 从被动的全景展示变成了主动的知识规划工具。
Signal:信号驱动架构
12 种信号类型
Alembic 中的每一个有意义的事件都产生一个信号。12 种信号类型覆盖了系统的全部行为:
| 信号类型 | 产生场景 | 消费者 |
|---|---|---|
guard | Guard 规则命中 | HitRecorder, DecayDetector |
guard_blind_spot | Guard 低覆盖区域 | Panorama |
search | 搜索命中 | HitRecorder, DecayDetector |
usage | 用户查看/采纳/应用 Recipe | HitRecorder, Lifecycle |
lifecycle | Recipe 状态转换(pending→active) | Dashboard, Metabolism |
exploration | Bootstrap 扫描发现 | PanoramaService |
quality | 质量评分变化 | Metabolism |
panorama | 全景覆盖率变化(≥5%) | Dashboard |
decay | 衰退检测事件 | Metabolism |
forge | 知识锻造事件 | HitRecorder |
intent | 用户意图分类 | AgentRouter |
anomaly | 阈值突破 | Dashboard, Alert |
每个信号携带统一的结构:
interface Signal {
type: SignalType;
source: string; // 产生者模块 ID
target: string | null; // 目标 Recipe/Module ID
value: number; // [0, 1] 归一化强度
metadata: Record<string, unknown>; // 任意上下文
timestamp: number; // 毫秒时间戳
}SignalBus:同步分发
SignalBus 是所有信号的中央管道。设计上有三个关键约束:
同步分发(< 0.1ms per emit):信号发送不经过队列——emit 调用时立即同步执行所有订阅者的 handler。这保证了信号的因果序——A 事件产生的信号一定在 B 事件之前被处理,如果 A 先发生。
异常隔离:消费者的异常不阻断分发。如果 DecayDetector 的 handler 抛出错误,HitRecorder 的 handler 仍然会执行。每个 handler 的异常被 catch 后记录日志但不传播。
订阅模式:支持精确订阅、多类型订阅和通配符:
// lib/infrastructure/signal/SignalBus.ts
subscribe('guard', handler); // 只接收 guard 信号
subscribe('guard|search|usage', handler); // 接收三种类型
subscribe('*', handler); // 接收所有信号便捷发送方法自动填充时间戳并将 value 钳制到 [0, 1]:
send(type: SignalType, source: string, value: number, opts?: {
target?: string;
metadata?: Record<string, unknown>;
})SignalBridge 把 SignalBus 连接到 EventBus——HTTP 层和 Dashboard 只监听 EventBus,不直接订阅 SignalBus,保持外层与核心信号层的解耦。
HitRecorder:批量采集
如果每次 Guard 命中或搜索命中都直接写数据库,SQLite 的并发写入限制会成为瓶颈。HitRecorder 在中间加了一层缓冲:
信号产生
│
├── 立即:emit 到 SignalBus(供实时消费者使用)
│
└── 缓冲:记录到内存 buffer
│
├── buffer 满 100 条 → 立即 flush
└── 30 秒定时器 → 批量 flush
│
└── 批量 SQL UPDATE →
json_set(stats, '$.guardHits', old + delta)五种命中事件映射到不同的统计字段:
| 事件类型 | 统计字段 | 信号类型 |
|---|---|---|
guardHit | stats.guardHits | guard |
searchHit | stats.searchHits | search |
view | stats.views | usage |
adoption | stats.adoptions | usage |
application | stats.applications | usage |
批量写入用一条 SQL 更新多行,利用 SQLite 的 json_set 原子操作:
UPDATE knowledge_entries
SET stats = json_set(
COALESCE(stats, '{}'),
'$.' || ?, -- 字段路径
COALESCE(json_extract(stats, '$.' || ?), 0) + ? -- 旧值 + 增量
),
updatedAt = ?
WHERE id = ?30 秒缓冲的权衡:最坏情况下丢失 30 秒的数据——如果进程在 flush 前崩溃,这 30 秒内的命中记录会丢失。但对于统计场景来说,guardHits 从 142 变成 145 还是 143,差异可以忽略。30 秒的缓冲把随机写入聚合为批量写入,写入性能提升一个数量级。
stop() 方法在进程关闭前执行最后一次 flush,尽可能减少数据丢失。
SignalAggregator:滑动窗口异常检测
SignalAggregator 在更高层面监控信号流——不关心单个信号,关心信号流的统计特征。
// lib/infrastructure/signal/SignalAggregator.ts
{
intervalMs: 60_000, // 每 60 秒 flush 一次统计
windowMs: 300_000, // 5 分钟滑动窗口
}每种信号类型维护一个 5 分钟的滑动窗口。每 60 秒计算一次窗口内的统计值(count、avg、max、min),写入 ReportStore。关键逻辑是异常检测:
if count > baseline × 3:
emit('anomaly', ...) // 信号量突增 3 倍以上
baseline = 0.8 × baseline + 0.2 × count // 指数移动平均baseline 是指数移动平均(EMA),权重 0.8:0.2——新的数据点只占 20% 的权重,防止偶发波动干扰基线。当某种信号在 5 分钟内的数量突然超过基线 3 倍时,发出 anomaly 信号。
这能捕获什么?比如:Guard 命中信号通常每分钟 5-10 条(有人在正常写代码),突然一分钟内 50 条——可能有人在大规模重构代码,或者引入了一个与多条 Recipe 冲突的大改动。这个 anomaly 信号会触发 Metabolism 的分析流程。
KnowledgeMetabolism:知识代谢
治理编排
KnowledgeMetabolism 是代谢系统的调度中心。它订阅 decay|quality|anomaly 信号,收到信号后防抖 30 秒再执行完整的代谢循环:
// lib/service/evolution/KnowledgeMetabolism.ts
#scheduleMetabolism(): void {
if (this.#running) { return; } // 防止并发执行
if (this.#debounceTimer) { return; } // 已有调度
this.#debounceTimer = setTimeout(() => {
if (this.#pendingTriggers.length > 0) {
void this.runFullCycle();
}
}, 30_000); // 30 秒防抖
}防抖的意义:代码重构可能在几秒内触发大量 guard 和 quality 信号——每个信号都跑一次完整代谢循环太浪费。30 秒的缓冲让这些信号聚合后一次性处理。
完整的代谢循环包含三个检测器和一个提案生成器:
runFullCycle():
├── ① DecayDetector.evaluate() → 衰退评分
├── ② ContradictionDetector.scan() → 矛盾检测
├── ③ RedundancyAnalyzer.analyze() → 冗余分析
└── ④ 汇总 → EvolutionProposal[] → 持久化
输出: MetabolismReport {
contradictions: ContradictionResult[]
redundancies: RedundancyResult[]
decayResults: DecayScoreResult[]
proposals: EvolutionProposal[]
summary: { totalScanned, contradictionCount, redundancyCount,
decayingCount, proposalCount }
}DecayDetector:六策略衰退检测
衰退是知识的自然老化——随着项目演进,一些 Recipe 描述的代码模式被淘汰,一些规则不再适用。DecayDetector 用六种策略检测衰退:
| 策略 | 触发条件 | 宽限期 |
|---|---|---|
| 无使用 | 90 天无 guardHit/searchHit | 标准 30 天 |
| 高误报 | 误报率 > 40% 且触发 ≥ 10 次 | 缩短 15 天 |
| 符号漂移 | ReverseGuard 检测到 API 移除 | 自定义 |
| 源引用过期 | sourceRefs 状态为 stale | 按数量 |
| 被替代 | 存在 deprecated_by 关系 | 立即 |
| 矛盾 | ContradictionDetector 发现硬冲突 | 经 Metabolism |
衰退不是二元的——DecayDetector 为每条 Recipe 计算一个 0–100 的衰退分数,基于四个维度:
| 维度 | 权重 | 计算方式 |
|---|---|---|
| freshness | 0.3 | |
| usage | 0.3 | |
| quality | 0.2 | QualityScorer 的评分 |
| authority | 0.2 | reasoning.confidence |
分数映射到五个级别:
| 分数 | 级别 | 动作 | 宽限期 |
|---|---|---|---|
| 80–100 | healthy | 无操作 | — |
| 60–79 | watch | Dashboard 警告 | — |
| 40–59 | decaying | active → decaying | 30 天 |
| 20–39 | severe | active → decaying | 15 天 |
| 0–19 | dead | 直接 → deprecated | 立即 |
watch 级别不触发状态变更——它只是一个预警信号,让用户在 Dashboard 上看到"这条 Recipe 正在老化"。只有 decaying 及以下才会触发 Ch07 中讲述的生命周期状态转换。
ContradictionDetector:四维矛盾检测
随着知识库增长,不同 Recipe 之间可能产生矛盾。典型场景:早期的 Recipe 说"使用 NSLock 做同步",后来的 Recipe 说"禁止使用 NSLock,改用 actor"。两条 Recipe 都是 active 的,但建议相反。
ContradictionDetector 从四个维度检测矛盾:
| 维度 | 检测方式 | 示例 |
|---|---|---|
| 否定模式 | 正则匹配中英文否定词 | "不再使用"、"deprecated" |
| 主题重叠 | Jaccard ≥ 0.3 且 ≥ 2 个共同非停用词 | 两条都关于"同步"+"并发" |
| 条款交叉 | doClause 与另一条的 dontClause 文本匹配 | A.do = B.dont |
| Guard 正则冲突 | guard pattern 完全相同但 severity 不同 | 同一模式,一条 error 一条 warning |
否定模式用两组正则覆盖中英文:
// lib/service/evolution/ContradictionDetector.ts
const NEGATION_ZH = /不(再)?使用|禁止|废弃|移除|取消|停止|不要|不采用|弃用|淘汰/;
const NEGATION_EN = /\b(don'?t|do\s+not|never|no\s+longer|removed?|deprecated?|stop|avoid|disable|abandon|drop)\b/i;矛盾分为两个置信度级别:
- 硬矛盾(≥ 0.8):立即升级,需要人工介入
- 软矛盾(0.4–0.8):警告级别,需要审查
发现矛盾后,系统向 SignalBus 发送 lifecycle 信号,触发生命周期流程——通常导致较旧的一条 Recipe 进入 decaying 状态。
RedundancyAnalyzer:四维冗余分析
知识库中可能出现两条 Recipe 说的是同一件事——只是措辞不同、代码示例不同。RedundancyAnalyzer 用四个维度的加权融合检测冗余:
| 维度 | 权重 | 阈值 | 度量方式 |
|---|---|---|---|
| Title 相似度 | 0.2 | Jaccard ≥ 0.7 | 标题 token 集合的 Jaccard 相似度 |
| Clause 相似度 | 0.3 | ≥ 0.6 | doClause + dontClause 文本匹配 |
| Code 相似度 | 0.3 | ≥ 0.8 | |
| Guard 匹配 | 0.2 | 精确相等 | guard pattern 是否完全相同 |
综合分数超过 0.65 就标记为冗余对:
Code 相似度用归一化 Levenshtein 距离——编辑距离除以较长字符串的长度。这比 Jaccard 更适合代码比较,因为代码中变量名的微小差异不应该导致低相似度。
冗余检测的输出是 merge 提案——建议把两条高度相似的 Recipe 合并为一条,保留质量更高的那条作为基础。
进化提案
三个检测器的输出汇总为进化提案(EvolutionProposal):
interface EvolutionProposal {
type: 'merge' | 'enhance' | 'deprecate' | 'contradiction' | 'correction';
targetRecipeId: string;
relatedRecipeIds: string[];
confidence: number; // [0, 1]
source: 'contradiction' | 'redundancy' | 'decay' | 'enhancement';
description: string;
evidence: string[];
proposedAt: number;
expiresAt: number; // 7 天 TTL
}提案有 7 天有效期——超时未处理的提案自动过期。这避免了提案无限堆积的问题——如果一个提案 7 天内没有被用户或 Agent 处理,它可能已经不再相关了。
EnhancementSuggester 补充了另一类提案——不是"删除坏知识"而是"改进好知识":
| 策略 | 触发条件 | 优先级 |
|---|---|---|
| 缺代码示例 | kind='rule' + guardHits ≥ 5 + coreCode 为空 | 中/高 |
| 低采纳率 | searchHits ≥ 10 + adoptions = 0 | 中/高 |
| 低权威性 | authority 低于同 category 第 25 百分位 | 中 |
| 被替代引用 | 存在 deprecated_by 关系 | 低 |
"缺代码示例"的逻辑很巧妙:一条规则被 Guard 命中 5 次以上,说明它是有用的;但没有 coreCode,Agent 在修复违规时缺少参考代码。系统建议为这条规则添加代码示例。
StagingManager:置信度分级宽限
代谢系统产出的提案不会直接生效——它需要经过 StagingManager 的宽限期:
| 置信度 | 宽限期 | 逻辑 |
|---|---|---|
| ≥ 0.90 | 24 小时 | 高置信度,快速确认 |
| 0.85–0.89 | 72 小时 | 中等置信度,需要更多观察 |
| < 0.85 | 更长 | 低置信度,等待更多证据 |
宽限期内 Recipe 处于 staging 状态——还没有正式变更。如果在宽限期内 Guard 检测到这条 Recipe 被使用了(反面证据),rollback() 把它退回 pending 状态。只有宽限期到期且无反面证据时,checkAndPromote() 才把 Recipe 正式提升为 active。
这个机制防止代谢系统"误杀"——一条 Recipe 可能 90 天没被搜索到,但它可能是一条关于年度部署流程的规则,本来就不会被频繁使用。24–72 小时的宽限期给了系统一个"后悔窗口"。
Panorama 与 Metabolism 的互动
三个子系统不是孤立的——它们形成一条完整的数据链路:
Bootstrap 生成初始 Panorama
↓
Panorama 发现知识空白
→ KnowledgeGap[] → 指导 Agent 优先分析高价值模块
↓
日常使用产生信号
→ guard / search / usage → HitRecorder 缓冲 → flush
↓
信号聚合检测异常
→ SignalAggregator → anomaly 信号
↓
代谢周期启动(防抖 30 秒)
→ DecayDetector + ContradictionDetector + RedundancyAnalyzer
→ EvolutionProposal[] → StagingManager
↓
Panorama 重新计算
→ 覆盖率变化 ≥ 5% → panorama 信号 → Dashboard 更新增量扫描(rescan)更新 Panorama 时,RecipeRelevanceAuditor 对所有 Recipe 做相关性审计——检查四个维度:
| 维度 | 默认权重 | 检测内容 |
|---|---|---|
| 触发器仍匹配 | 0.20 | Recipe 的文件匹配模式是否还能匹配到文件 |
| 符号存活 | 0.30 | coreCode 中的 API 符号是否还存在 |
| 依赖完整 | 0.15 | 模块依赖关系是否还存在 |
| 代码文件存在 | 0.35 | sourceRefs 引用的文件是否还存在 |
架构类 Recipe 的权重分配不同——triggerStillMatches 和 codeFilesExist 各占 0.45,因为架构规则更多依赖文件结构而非具体 API 符号。
审计结果映射到与 DecayDetector 类似的判定级别,但宽限期更短(decay: 7 天,severe: 3 天,dead: 立即)。这是因为审计是在 rescan 时执行的——用户主动触发了扫描,对结果的期望更迫切。
运行时行为
以四个场景展示三系统的协同工作:
场景 1:搜索命中 → 热度累积
用户搜索 "网络层架构"
→ searchHit 信号 → SignalBus 同步分发
→ HitRecorder 缓冲(guardHit 计数 +1)
→ 30 秒后 flush → SQL batch UPDATE
→ @network-layer-pattern 的 stats.searchHits +1
→ Popularity 信号增加微量场景 2:90 天无命中 → 衰退流程
DecayDetector 评估 @legacy-callback-pattern:
freshness: (100 - 200) / 100 = 0 (clip to 0)
usage: 0 / 5 = 0 (90天 0 次命中)
quality: 0.65
authority: 0.7
decayScore = (0×0.3 + 0×0.3 + 0.65×0.2 + 0.7×0.2) × 100 = 27
级别: severe (20–39)
→ active → decaying,宽限期 15 天
→ 15 天后无反面证据 → deprecated场景 3:代码重构 → 矛盾检测
项目从 NSLock 迁移到 actor:
新 Recipe: "使用 actor 进行状态隔离"
旧 Recipe: "使用 NSLock 保护共享状态"
ContradictionDetector:
主题重叠: ["同步", "状态", "并发"] → Jaccard 0.6
否定模式: 新 Recipe 的 dontClause 包含 "不要使用 NSLock"
→ 硬矛盾 (confidence 0.85)
→ lifecycle 信号 → 旧 Recipe 进入 decaying
→ EvolutionProposal: type='deprecate'
→ StagingManager: 置信度 0.85 → 宽限期 72 小时场景 4:Panorama 发现知识空白
PanoramaService.getGaps():
DimensionAnalyzer 扫描:
"网络与 API": 8 条 Recipe → strong ✓
"并发与异步": 3 条 → adequate ✓
"支付模块": 0 条 → missing ✗
KnowledgeGap: {
dimension: "支付模块",
suggestedTopic: "支付流程与安全验证模式",
affectedModules: ["PaymentKit"],
priority: "high"
}
→ 报告给用户:
"PaymentKit 模块有 12 个文件但零 Recipe 覆盖"权衡与替代方案
为什么不用 Cron 定时任务
传统做法:每天凌晨跑一次全量扫描,生成衰退报告。Alembic 不这样做:
- 浪费。如果今天没人使用知识库,凌晨的扫描完全白跑——消耗 CPU 和数据库 I/O 但不产出任何有用信息。
- 延迟高。如果上午发现了一个严重矛盾,要等到第二天凌晨才能检测到。信号驱动的代谢在矛盾发生后 30 秒内就开始分析。
- 颗粒度粗。Cron 只能决定"什么时候跑",不能决定"因为什么跑"。信号驱动精确知道是哪种事件触发了代谢——衰退信号触发 DecayDetector,质量信号触发 ContradictionDetector。
30 秒缓冲的取舍
HitRecorder 的 30 秒缓冲意味着最坏情况下丢失 30 秒的统计数据。为什么不实时写入?
SQLite 的 WAL 模式支持单写者并发读——但频繁的小写入仍然会产生 I/O 压力。知识库可能在 CI 流程中高频执行 Guard 检查(30 秒内 200+ violation),每个 violation 都写一次数据库会拖慢整个流程。
30 秒是一个实验后的甜蜜点:
- 短于 1 分钟:人类感知不到统计数据的延迟
- 长于 5 秒:足够聚合一批操作
- buffer 满 100 条立即 flush:防止爆发性场景下的内存膨胀
Panorama 的计算成本
Panorama 的 Tarjan + 拓扑排序 + 覆盖率分析在大项目(10,000+ 文件)上可能需要数秒。Alembic 的优化策略:
- 24 小时缓存:
STALE_THRESHOLD_MS = 24h。Panorama 计算结果缓存一天,重复请求直接返回。 - 信号驱动失效:当
guard|lifecycle|usage信号到达时,缓存标记为 stale——下次请求时重新计算。 - 增量扫描:
PanoramaScanner有#hasScanned幂等保护,同一次进程生命周期内不会重复扫描。
小结
Panorama、Signal、Metabolism 三系统的设计可以归结为三个核心原则:
- 感知先于行动。Panorama 用图算法(Tarjan + Kahn)把项目从一堆文件变成有层次的模块拓扑、有覆盖率的热力图。没有这个全景,后续的一切分析都缺少坐标系。
- 信号驱动替代轮询。12 种信号类型 + SignalBus 同步分发 + HitRecorder 批量缓冲,构成了一个事件驱动的神经网络。代谢循环只在有信号时才启动——不浪费一次 CPU 周期。
- 渐进式治理。衰退不是 0/1 判定而是 0–100 连续分数;矛盾分为硬/软两级;冗余有加权融合阈值;提案有 7 天 TTL 和置信度分级的宽限期。这些渐进机制防止了激进的自动化决策损害知识库的稳定性。
下一章我们将进入 Part V — Agent 智能层,看看 AI 如何通过 ReAct 推理循环参与知识生产。