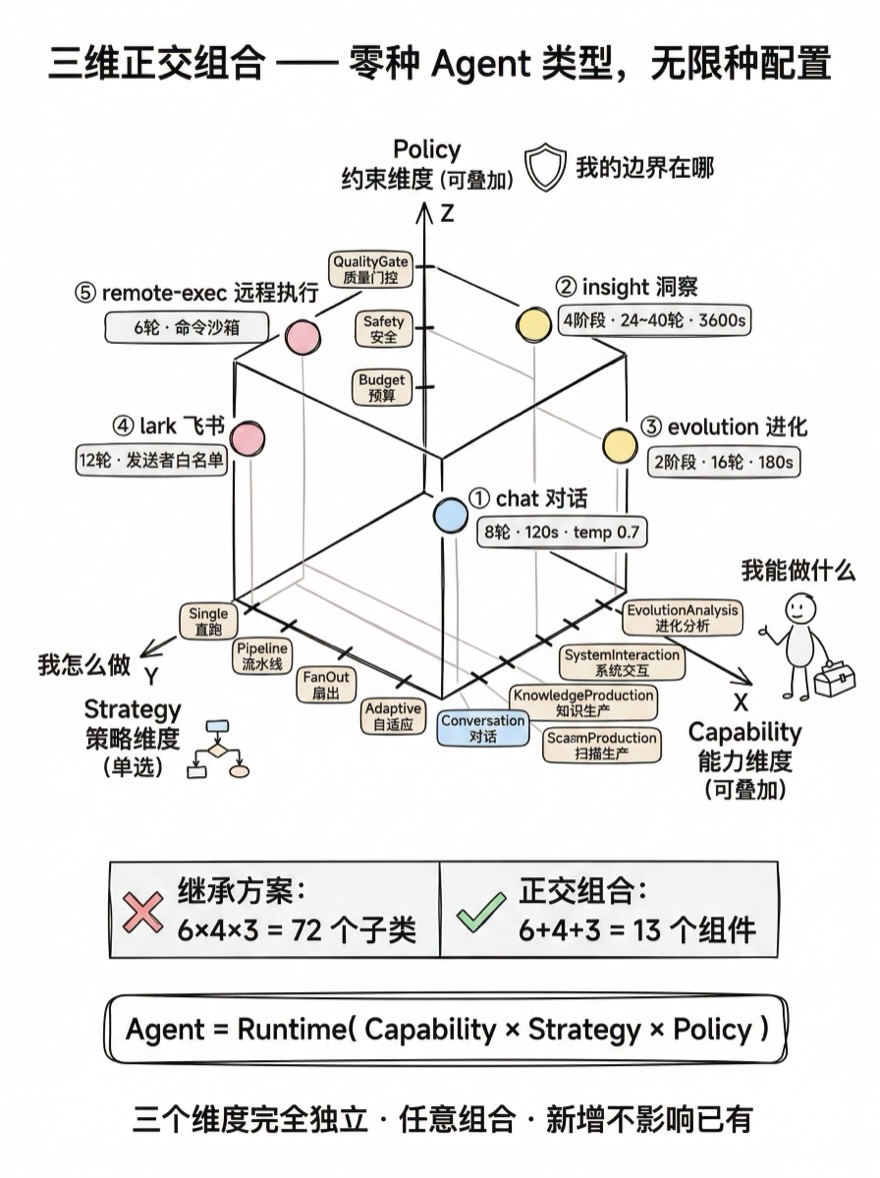
正交组合 — Capability × Strategy × Policy
零种 Agent 类型,无限种配置 — 三维正交的 Agent 设计模式。
问题场景
一个知识引擎需要 Agent 做很多不同的事情:聊天问答、代码分析、知识提取、冷启动批量扫描、进化评审、飞书消息处理。
直觉做法是创建 ChatAgent、AnalysisAgent、BootstrapAgent、EvolutionAgent、LarkAgent 五个子类。但当你需要一个 "能分析代码又能聊天" 的 Agent 时怎么办?再建一个 ChatAnalysisAgent?当 5 种能力的任意组合需求出现时,你面对的是
这是经典的 组合爆炸 问题。
更微妙的是,同样的能力组合可能有完全不同的执行方式——聊天是单轮交互,知识提取是多阶段流水线,冷启动是并行扇出。如果把执行策略也编码进子类,组合数还要翻倍。再加上每种场景的安全策略不同(飞书要限制发送者、远程执行要限制命令),你面对的已经不是
没有人能维护 384 个 Agent 子类。
设计决策
三维正交公式
Alembic 的解法是把 Agent 的构成分解到三个完全独立的维度:
- Capability(我能做什么):技能模块,可叠加。一个 Agent 可以同时拥有 Conversation + CodeAnalysis 两种能力。
- Strategy(我怎么做):工作组织方式,单选。同一个 Agent 要么直接跑 ReAct 循环,要么走流水线,不能两种并存。
- Policy(我的边界在哪):约束规则,可叠加。BudgetPolicy 限制资源消耗,SafetyPolicy 限制命令执行,可以同时生效。
三个维度完全独立,任意组合。新增一种能力只需加一个 Capability,不影响已有 Strategy 和 Policy。新增一种执行策略只需加一个 Strategy,所有现有 Capability 自动可用。这就是"正交"的含义——每个维度的变化不传播到其他维度。
关键洞察:同一个 AgentRuntime 和同一个 reactLoop() 驱动所有 Agent 行为。差异完全通过配置表达,而非通过继承或分支表达。这与上一章的结论一脉相承——"统一引擎 + 配置分化"。
与继承方案的对比
用一个具体的例子量化正交组合的优势。假设系统有 6 种 Capability、4 种 Strategy、3 种 Policy:
| 方案 | 代码实体数 | 添加第 7 个 Capability 的成本 |
|---|---|---|
| 继承树 | 最多 | + |
| 正交组合 | +1 个 Capability 类 |
边际成本的差距是 12 倍。更重要的是,继承方案的 72 个子类大部分只在组合上不同(比如 ChatSingleBudgetAgent 和 ChatSingleSafetyAgent 的唯一区别是 Policy)——这种重复不仅浪费代码量,还违反了 DRY 原则。
Alembic 的实际数字:6 个 Capability + 4 个 Strategy + 3 个 Policy = 13 个组件类,配合 5 个 Preset 覆盖所有生产场景。三个文件(capabilities.ts、strategies.ts、policies.ts)加上一个配置文件(presets.ts),总计约 2000 行代码。
架构与数据流
Capability 系统
Capability 是"我能做什么"的维度——每个 Capability 向 Agent 注入一组工具和一段上下文提示词。所有 Capability 继承自同一个基类:
// lib/agent/capabilities.ts
export class Capability {
get name(): string { ... } // 标识符
get promptFragment(): string { ... } // 注入系统提示词
get tools(): string[] { ... } // 工具白名单(默认 [])
buildContext(_context: unknown): string | null { ... } // 动态上下文
onBeforeStep(_stepState: unknown) {} // 步前钩子
onAfterStep(_stepResult: unknown) {} // 步后钩子
}四个核心方法定义了 Capability 与 Runtime 的交互协议:tools 声明能用哪些工具(白名单),promptFragment 注入角色或领域提示词,buildContext 在每一轮循环前动态注入上下文,onBeforeStep / onAfterStep 提供生命周期钩子。
Alembic 内置 6 个 Capability,通过 CapabilityRegistry 工厂统一管理:
// lib/agent/capabilities.ts
export const CapabilityRegistry = {
_registry: new Map<string, typeof Capability>([
['conversation', Conversation],
['code_analysis', CodeAnalysis],
['knowledge_production', KnowledgeProduction],
['scan_production', ScanProduction],
['system_interaction', SystemInteraction],
['evolution_analysis', EvolutionAnalysis],
]),
create(name: string, opts: Record<string, unknown> = {}) {
const Cls = this._registry.get(name);
if (!Cls) { throw new Error(`Unknown capability: ${name}`); }
return new Cls(opts);
}
};六种内置 Capability
Conversation — 对话与知识检索
注入 SOUL.md 人格提示词(约 40–150 token),启用记忆上下文缓存。适用于所有需要与用户多轮交互的场景。
| 分类 | 工具 |
|---|---|
| 知识检索 | search_knowledge · search_recipes · get_recipe_detail · get_related_recipes |
| 代码语义 | semantic_search_code |
| 知识写入 | submit_knowledge |
| 全局视图 | knowledge_overview · get_project_stats |
CodeAnalysis — 代码结构理解
注入批量搜索策略提示词,自动收集证据链(文件路径 + 代码片段)。适用于所有需要"读懂代码"的场景——从类层次分析到设计模式检测。
| 分类 | 工具 |
|---|---|
| 结构探索 | get_project_overview · get_class_hierarchy · get_class_info · get_protocol_info |
| 关系分析 | get_method_overrides · get_category_map · query_code_graph |
| 代码搜索 | search_project_code · semantic_search_code · read_project_file |
| 项目导航 | list_project_structure · get_file_summary |
| 证据管理 | get_previous_analysis · get_previous_evidence · note_finding |
KnowledgeProduction — 知识候选生产
适用于 insight 分析流水线的"产出"阶段。submit_knowledge 内部集成了 UnifiedValidator 完整校验——字段约束、去重检查、质量评分一步到位。
| 分类 | 工具 |
|---|---|
| 知识提交 | submit_knowledge · submit_with_check |
| 源码参考 | read_project_file |
ScanProduction — 扫描模式的轻量产出
与 KnowledgeProduction 共享相同的 schema,但使用 collect_scan_recipe 工具——收集到运行时而非持久化到数据库。适用于 Bootstrap 冷启动的批量扫描阶段,避免在分析过程中直接写入数据库。
| 分类 | 工具 |
|---|---|
| 批量收集 | collect_scan_recipe |
SystemInteraction — 终端执行与文件操作
三层安全防护:工具级黑名单(危险命令正则匹配)、SafetyPolicy 验证(白名单路径和发送者)、运行时检查(PathGuard 文件系统沙箱)。这是唯一一个强制绑定 SafetyPolicy 的 Capability。
| 分类 | 工具 |
|---|---|
| 副作用操作 | run_safe_command · write_project_file |
| 环境信息 | get_environment_info |
| 只读探索 | read_project_file · search_project_code · list_project_structure · get_project_overview · get_file_summary |
EvolutionAnalysis — 知识进化决策
驱动 Recipe 的进化流程——分析源代码变化、提出进化提案、确认废弃或跳过。
| 分类 | 工具 |
|---|---|
| 源码分析 | read_project_file · search_project_code |
| 进化决策 | propose_evolution · confirm_deprecation · skip_evolution |
Capability 的正交性
关键设计:每个 Capability 只声明工具白名单,不实现工具逻辑。工具实现在 ToolRegistry 中,Capability 只是"选择"哪些工具可用。这意味着:
- Conversation 和 CodeAnalysis 可以自由叠加——它们的工具集没有冲突。
- 同一个工具(比如
read_project_file)可以被多个 Capability 引用。 - 添加新 Capability 只需声明一组工具名和一段提示词,不需要修改 Runtime 的任何代码。
当多个 Capability 叠加时,Runtime 合并它们的工具集(取并集)和提示词(按序拼接)。这是 Composition over Inheritance 的典型应用。
Strategy 系统
Strategy 是"我怎么做"的维度——决定 ReAct 循环如何被编排。所有 Strategy 继承自同一个基类:
// lib/agent/strategies.ts
export class Strategy {
get name(): string {
throw new Error('Subclass must implement name');
}
async execute(
_runtime: StrategyRuntime,
_message: AgentMessage,
_opts?: Record<string, unknown>
): Promise<StrategyResult> {
throw new Error('Subclass must implement execute()');
}
}接口极简——一个 execute() 方法。Strategy 接收 Runtime(提供 reactLoop() 能力)和消息,返回执行结果。如何编排循环是 Strategy 内部的事情。
SingleStrategy — 直跑
最简单的策略:直接把消息交给 reactLoop(),跑到终止条件为止。
SingleStrategy.execute(runtime, message):
return runtime.reactLoop(message, budget)适用于聊天问答、简单查询——任何一轮 ReAct 循环就能完成的任务。Chat 和 Lark Preset 使用这个策略。
PipelineStrategy — 多阶段流水线
最复杂的策略,也是 Alembic 知识生产的核心编排引擎。Pipeline 把一次任务分解为多个阶段(Stage),每个阶段有独立的 Capability、预算、系统提示词、以及质量门控(Gate)。
// lib/agent/PipelineStrategy.ts
interface PipelineStage {
name: string; // 阶段名
capabilities?: (string | { name: string })[]; // 本阶段使用的 Capability
systemPrompt?: string; // 阶段专用系统提示词
budget?: { maxIterations?, timeoutMs?, temperature? }; // 阶段预算
promptBuilder?: (ctx) => string; // 动态构建提示词
gate?: {
evaluator?: (source, phaseResults, ctx) =>
{ action: 'pass' | 'retry' | 'degrade'; artifact?: unknown };
maxRetries?: number;
};
skipOnDegrade?: boolean; // 降级时跳过本阶段
}门控的三态设计是 Pipeline 最精巧的部分——它不是简单的 pass/fail 二元判断:
pass— 质量达标,继续下一阶段。retry— 质量不够,退回上一阶段重跑,但换一个retryPromptBuilder生成的修复提示词。degrade— 多次重试仍不达标,放弃后续阶段,用已有结果构造降级输出。
为什么三态而非二态? 因为 LLM 的输出质量是概率性的——同一个提示词跑两次可能出不同质量的结果。retry 给了一次"用更具体的提示词重试"的机会;degrade 保证即使多次重试失败,系统也不会卡死——部分结果好过无结果。
以 insight Preset 的四阶段流水线为例:
Stage 1: analyze
Capability: code_analysis
Budget: 24 轮, temperature 0.4
→ Agent 搜索代码、分析结构、收集证据
Stage 2: quality_gate
Gate: insightGateEvaluator
→ 检查证据量是否足够、文件引用是否充分
→ pass / retry(指出不足) / degrade(跳过生产)
Stage 3: produce
Capability: knowledge_production
Budget: 16 轮, temperature 0.3
→ Agent 把分析结果转化为知识候选并提交
Stage 4: rejection_gate
Gate: producerRejectionGateEvaluator
→ 检查是否有被 UnifiedValidator 拒绝的提交
→ pass / retry(附修复指南) / degrade(接受部分结果)每个阶段是一次独立的 ReAct 循环——不同的 Capability、不同的系统提示词、不同的预算。阶段之间通过 phaseResults 传递中间结果。这种设计让分析和生产用不同的 temperature(分析用 0.4 偏创造,生产用 0.3 偏精确),用不同的 Capability(分析不需要 submit 工具,生产不需要 graph 工具),用不同的预算(分析给 24 轮充分探索,生产同样 24 轮但用于集中输出)。
FanOutStrategy — 并行扇出
FanOut 把一个大任务分解为 N 个子任务,并行执行后合并结果。典型场景是 Bootstrap 冷启动——25 个维度的知识分析可以并行进行。
FanOutStrategy.execute(runtime, items):
// 分层并发控制
tier1Items = items.filter(highPriority) → 并发 3
tier2Items = items.filter(medPriority) → 并发 2
tier3Items = items.filter(lowPriority) → 并发 1
results = []
for tier in [tier1, tier2, tier3]:
batchResults = await Promise.allSettled(
tier.map(item => itemStrategy.execute(runtime, item))
)
results.push(...batchResults)
return merge(results)分层并发控制是 FanOut 的关键——不是所有维度都值得同样的并发度。高优先级维度(如 architecture、conventions)先跑且并发更高,低优先级维度(如 performance、observability)后跑且并发更低。这避免了 LLM API 的并发限流,也确保了重要维度优先完成。
每个子任务的执行策略由 itemStrategy 决定——通常是一个 Pipeline。所以 FanOut 实际上是 FanOut + Pipeline 的嵌套:扇出 25 个维度,每个维度内部走 analyze → gate → produce 的流水线。
AdaptiveStrategy — 运行时智能路由
Adaptive 根据任务的复杂度在运行时自动选择策略:简单任务走 Single,复杂任务走 Pipeline 或 FanOut。复杂度的判定基于输入文件数量、请求类型、是否需要多阶段处理。
// lib/agent/presets.ts
// resolveStrategy 递归解析策略配置
export function resolveStrategy(config: StrategyConfig): Strategy {
switch (config.type) {
case 'single': return new SingleStrategy();
case 'pipeline': return new PipelineStrategy({ stages: config.stages });
case 'fan_out': return new FanOutStrategy({
itemStrategy: resolveStrategy(config.itemStrategy),
tiers: config.tiers
});
case 'adaptive': return new AdaptiveStrategy({ ... });
}
}resolveStrategy 是递归的——FanOut 的 itemStrategy 本身可以是 Pipeline,Pipeline 的阶段可以嵌套 FanOut。这种递归组合能力是声明式配置的威力:你只需描述"我要什么样的执行结构",工厂帮你组装。
Policy 系统
Policy 是"我的边界在哪"的维度——跨切面的约束引擎。所有 Policy 继承自同一个基类,通过三个校验点与 Runtime 交互:
// lib/agent/policies.ts
export class Policy {
// 执行前校验:检查前置条件(如发送者是否合法)
validateBefore(_context: PolicyContext): { ok: boolean; reason?: string } {
return { ok: true };
}
// 执行中校验:每一轮迭代检查(如是否超预算)
validateDuring(_stepState: StepState): { ok: boolean; action?: string; reason?: string } {
return { ok: true, action: 'continue' };
}
// 执行后校验:检查最终输出质量
validateAfter(_result: PolicyResult): { ok: boolean; reason?: string } {
return { ok: true };
}
// 配置注入:修改 Runtime 的配置(如设置 temperature)
applyToConfig(config: Record<string, unknown>): Record<string, unknown> {
return config;
}
}三个校验点形成一个完整的执行围栏——Before 卡入口,During 卡过程,After 卡出口。这比"只在开始检查一次"要健壮得多——Budget 超限是在执行过程中发生的,只有 validateDuring 能捕获。
BudgetPolicy — 资源围栏
控制 Agent 的资源消耗上限:
new BudgetPolicy({
maxIterations: 8, // 最多 8 轮 ReAct 循环
maxTokens: 4096, // LLM 输出 token 总预算
timeoutMs: 120_000, // 2 分钟超时
temperature: 0.7 // LLM 温度参数
})validateDuring 在每轮循环开始时检查:当前迭代次数是否超过 maxIterations、累计 token 是否超过 maxTokens、已用时间是否超过 timeoutMs。任何一项超限,返回 { ok: false, action: 'stop' },Runtime 终止循环并用已有结果构造回复。
不同 Preset 的预算差异巨大:Chat 用 8 轮 / 120 秒(用户等不了太久),Insight 用 24 轮 / 3600 秒(后台深度分析),Remote-exec 用 6 轮 / 60 秒(快速命令执行)。这些差异全部通过 BudgetPolicy 的参数表达,不需要任何 if-else。
SafetyPolicy — 安全沙箱
控制 Agent 能执行什么命令、能访问什么文件、能响应谁的请求:
new SafetyPolicy({
allowedSenders: ['user_id_1', 'user_id_2'], // 发送者白名单
fileScope: '/path/to/project', // 文件操作沙箱
commandBlacklist: [...], // 命令黑名单
requireApprovalFor: [...] // 需要审批的操作
})SafetyPolicy 内置了一组硬编码的危险命令正则——无论 Preset 如何配置,这些命令永远被拦截:
// lib/agent/policies.ts
static DANGEROUS_COMMANDS = Object.freeze([
/\brm\s+-rf\s+[/~]/, // rm -rf / 或 ~
/\bsudo\b/, // 任何 sudo
/\bmkfs\b/, // 格式化磁盘
/\bdd\s+if=/, // 覆写磁盘
/\b(shutdown|reboot|halt)\b/, // 关机重启
/>\s*\/dev\//, // 写入设备文件
/\bcurl\b.*\|\s*(bash|sh)/, // 管道执行远程脚本
/\bchmod\s+777/, // 开放所有权限
/\bpasswd\b/, // 修改密码
/\bkillall\b/, // 杀所有进程
]);同时维护一个安全命令白名单(ls、cat、grep、git log 等)。不在白名单中的命令会触发更严格的检查。这是 Ch04 纵深防御的 Agent 层实现——Constitution 管 RBAC 权限,Gateway 管请求路由,SafetyPolicy 管命令执行,PathGuard 管文件系统。四层防护各司其职。
QualityGatePolicy — 质量门控
控制 Agent 输出的最低质量标准:
new QualityGatePolicy({
minEvidenceLength: 500, // 最少 500 字符的证据
minFileRefs: 3, // 最少引用 3 个源文件
minToolCalls: 2, // 类默认值 2,insight preset 覆盖为 3
customValidator: fn // 自定义校验函数
})QualityGatePolicy 的 validateAfter 在 Runtime 完成执行后检查结果质量。如果证据不足(Agent 只搜索了一个文件就下结论)、源引用太少(结论缺乏代码依据)、或工具调用太少(Agent 几乎没做实际分析),就判定质量不达标。
这个 Policy 只在 insight 和 evolution Preset 中使用——Chat 场景不需要质量门控(用户可以自己判断回答质量),但知识生产场景必须有,因为产出的候选会进入知识库长期存在。
PolicyEngine — 组合执行
多个 Policy 通过 PolicyEngine 组合执行,遵循 All-must-pass 语义:
// lib/agent/policies.ts
export class PolicyEngine {
validateBefore(context: PolicyContext) {
for (const policy of this.#policies) {
const result = policy.validateBefore(context);
if (!result.ok) { return result; } // 任何一个拒绝就拒绝
}
return { ok: true };
}
validateToolCall(toolName: string, args: Record<string, unknown>) {
const safety = this.get(SafetyPolicy);
if (!safety) { return { ok: true }; }
if (toolName === 'run_safe_command' && args?.command) {
const check = safety.checkCommand(args.command as string);
return check.safe ? { ok: true } : { ok: false, reason: check.reason };
}
// ... 文件路径检查
}
}PolicyEngine 还提供了一个特殊的 validateToolCall 方法——不走标准的 Before/During/After 流程,而是在每次工具调用前单独检查。这确保了即使 LLM 幻觉出一个危险命令,也会在执行前被拦截。
核心实现
AgentFactory — 装配车间
AgentFactory 是正交组合的实际装配点——接收一个 Preset 名称,产出一个配置好的 AgentRuntime:
// lib/agent/AgentFactory.ts
createRuntime(presetName: string, overrides: RuntimeOverrides = {}) {
// 1. 获取 Preset 配置(支持运行时覆盖)
const preset = getPreset(presetName, overrides);
// 2. 实例化 Capabilities
const capabilities = (preset.capabilities as string[]).map((name: string) => {
const opts = this.#getCapabilityOpts(name);
return CapabilityRegistry.create(name, opts);
});
// 3. 实例化 Policies(支持延迟工厂函数)
const resolvedPolicies = (preset.policies || []).map(
(policyOrFactory) =>
typeof policyOrFactory === 'function'
? policyOrFactory(overrides)
: policyOrFactory
);
const policyEngine = new PolicyEngine(resolvedPolicies);
// 4. 组装 AgentRuntime
return new AgentRuntime({
presetName,
aiProvider: this.#aiProvider,
toolRegistry: this.#toolRegistry,
capabilities, // ← 维度 1
strategy: preset.strategyInstance, // ← 维度 2
policies: policyEngine, // ← 维度 3
persona: preset.persona,
memory: preset.memory,
// ...
});
}三个维度在这里汇合——capabilities 是名字数组到 Capability 实例数组的转换,strategy 是声明式配置到 Strategy 实例的转换(由 resolveStrategy 递归解析),policies 是 Policy 实例数组到 PolicyEngine 的包装。AgentRuntime 接收这三样东西,加上 AI Provider 和 ToolRegistry,就是一个完整的 Agent。
注意第 3 步中 Policy 支持延迟工厂函数——typeof policyOrFactory === 'function' 的检查。这允许 Policy 的参数依赖运行时信息(比如 SafetyPolicy 的 fileScope 取决于当前项目路径),而非 Preset 定义时静态确定。
五个 Preset
Preset 是"经过验证的推荐组合"——防止用户或系统随意拼出不合理的配置(比如给 Chat 挂 QualityGatePolicy,或者给 Remote-exec 用 FanOut 策略)。
| Preset | Capabilities | Strategy | Policies | 设计动机 |
|---|---|---|---|---|
| chat | Conversation + CodeAnalysis | Single | Budget(8轮, 120s, 0.7) | 快速交互,用户在等 |
| insight | CodeAnalysis + KnowledgeProduction | Pipeline(4阶段) | Budget(24轮, 3600s, 0.3) + QualityGate | 深度分析,质量优先 |
| evolution | EvolutionAnalysis | Pipeline(2阶段) | Budget(16轮, 180s) | Recipe 生命周期决策 |
| lark | Conversation + CodeAnalysis | Single | Budget(12轮, 180s, 0.7) + Safety(发送者白名单) | 飞书消息入口,需认证 |
| remote-exec | Conversation + CodeAnalysis + SystemInteraction | Single | Budget(6轮, 60s, 0.5) + Safety(命令沙箱+路径限制) | 远程终端,最严格安全 |
逐个 Preset 拆解设计动机:
chat — 最常用的 Preset。Conversation 负责知识检索和对话,CodeAnalysis 负责代码搜索和结构分析。Single 策略因为对话本质上是单轮推理。Budget 设 8 轮和 120 秒——实验数据表明 Chat 场景 8 轮后几乎没有新信息(详见 Ch13 "为什么最大迭代不超过 24 轮")。Temperature 0.7 偏高,鼓励更自然的对话风格。
// lib/agent/presets.ts — chat
{
name: '对话',
capabilities: ['conversation', 'code_analysis'],
strategy: { type: 'single' },
policies: [
new BudgetPolicy({
maxIterations: 8,
maxTokens: 4096,
temperature: 0.7,
timeoutMs: 120_000
})
],
persona: { role: 'assistant', description: 'Alembic 知识管理助手' },
memory: { enabled: true, mode: 'user', tiers: ['working', 'episodic', 'semantic'] }
}insight — 最复杂的 Preset。四阶段 Pipeline(analyze → quality_gate → produce → rejection_gate),双重门控确保分析质量和生产质量。QualityGatePolicy 要求至少 400 字符证据、3 个文件引用、3 次工具调用(insight 覆盖默认值 2)。Analysis 阶段 temperature 0.4(需要创造性思考但不能太发散),Production 阶段 temperature 0.3(需要精确的知识格式化)。Memory 关闭——insight 是系统级任务,不需要记住上次对话。
evolution — 两阶段 Pipeline:evolve(分析源码变化并做出进化决策)+ evolution_gate(校验决策合理性)。Budget 16 轮 / 180 秒——进化决策需要足够分析深度但不必像 insight 那样彻底。
lark — 飞书入口。与 chat 几乎相同的 Capability 组合,但多了 SafetyPolicy 的发送者白名单——只有环境变量 ASD_LARK_ALLOWED_USERS 中的用户 ID 才能使用。Budget 从 8 轮放宽到 12 轮,因为飞书场景的消息可能更复杂(包含讨论上下文)。
remote-exec — 安全等级最高的 Preset。三个 Capability 中 SystemInteraction 赋予了终端执行能力,但 SafetyPolicy 同时限制了命令范围和文件路径。Budget 只有 6 轮 / 60 秒——远程执行应该是快速精准的,不是漫无目的的探索。Temperature 0.5 在创造性和精确性之间取折中。
运行时覆盖
Preset 不是铁板钉钉——getPreset 函数支持运行时覆盖:
// lib/agent/presets.ts
export function getPreset(presetName: string, overrides: Record<string, unknown> = {}) {
const preset = PRESETS[presetName];
if (!preset) {
throw new Error(`Unknown preset: "${presetName}". Available: ${Object.keys(PRESETS).join(', ')}`);
}
const merged = {
...preset,
...overrides,
capabilities: overrides.capabilities || preset.capabilities,
policies: overrides.policies || preset.policies,
persona: { ...preset.persona, ...overrides.persona },
memory: { ...preset.memory, ...overrides.memory }
};
merged.strategyInstance = resolveStrategy(
(overrides.strategy || preset.strategy) as StrategyConfig
);
return merged;
}scanKnowledge() 方法就是运行时覆盖的典型使用者——它基于 insight Preset,但替换了 Strategy(自定义的扫描流水线阶段)、Capability(code_analysis 而非 knowledge_production)、和 Policy(更大的预算):
// lib/agent/AgentFactory.ts
async scanKnowledge({ task, files, lang }) {
const stages = buildScanPipelineStages({ task, files, ... });
// 基于 insight,覆盖三个维度
const runtime = this.createRuntime('insight', {
strategy: { type: 'pipeline', stages }, // 覆盖 Strategy
capabilities: ['code_analysis'], // 覆盖 Capability
policies: [new BudgetPolicy({ // 覆盖 Policy
maxIterations: 30, maxTokens: 8192,
temperature: 0.3, timeoutMs: 3_600_000
})],
memory: { enabled: false }
});
return runtime.execute(message, { strategyContext: systemCtx });
}这展示了正交组合的实际威力:不需要创建一个 ScanAgent 子类,只需基于现有的 insight Preset 做三处覆盖,就得到了一个行为完全不同的 Agent 配置。
组合的约束
正交不意味着"任意组合都合理"。有些组合在逻辑上不应该存在:
- SystemInteraction 不带 SafetyPolicy — 终端执行没有安全约束是危险的。
- FanOut 策略用于 Chat — 对话没有可并行的子任务。
- QualityGatePolicy 用于 Chat — 对话不需要证据最低门槛。
Preset 的存在意义就在于此——它是经过验证的合理组合的命名快照。开发者可以通过 createRuntime('chat') 快速获得一个合理的配置,不需要自己判断哪些 Capability 和 Policy 应该搭配。当需要微调时用 overrides 覆盖个别参数,而非从零组装。
权衡与替代方案
为什么不用 Mixin
JavaScript/TypeScript 的 Mixin 模式看起来也能实现"能力叠加"——ConversationMixin、CodeAnalysisMixin 混入同一个 Agent 类:
// Mixin 方案(Alembic 没有采用)
class MyAgent extends mix(BaseAgent)
.with(ConversationMixin)
.with(CodeAnalysisMixin) { }问题:
- 类型安全。TypeScript 的 Mixin 类型推导在多层叠加时不可靠——当 ConversationMixin 和 CodeAnalysisMixin 都定义了
buildContext()方法时,最终类型是哪个?编译器可能推导错误,运行时可能执行了错误的版本。 - 工具冲突。Mixin 的方法合并是隐式的。如果两个 Mixin 都注册了同名工具但语义不同,冲突只在运行时暴露。Capability 的工具白名单是显式的——注册表管理,冲突在组装时就能发现。
- 配置化困难。Mixin 组合在编译时确定——
mix(A).with(B).with(C)写死在代码里。Capability 组合是运行时的字符串数组——['conversation', 'code_analysis'],可以存储在配置文件中、从环境变量读取、或通过 API 参数传入。
为什么不用插件系统
插件系统(类似 Webpack Plugin 或 Rollup Plugin)用钩子(hook)机制让外部代码注入行为:
// 插件方案(Alembic 没有采用)
runtime.use({
name: 'conversation',
onInit(ctx) { ctx.registerTools([...]); },
onBeforeStep(ctx) { ctx.injectPrompt('...'); },
onAfterStep(ctx) { ... }
});插件比 Mixin 好——它是运行时组合且类型安全。但 Capability 比插件更结构化:
- Capability 有明确的接口约束(
tools、promptFragment、buildContext),而插件的钩子是开放的——你可以在onInit里做任何事,没有什么约束能保证"这个插件确实注册了工具"。 - Capability 的
tools属性是一个白名单——Runtime 只暴露 Capability 声明的工具。插件没有这个约束,任何插件都能注册任何工具,安全边界不清晰。 - Capability 与 Strategy、Policy 是三个平等的维度。如果用插件实现,Strategy 和 Policy 也变成了插件——三种本质不同的东西(能力 / 编排 / 约束)被塞进了同一个抽象中。
正交组合的代价
正交组合不是没有代价:
- 间接性。要理解一个 Agent 的完整行为,需要查看 Preset 配置 → Capability 工具列表 → Strategy 执行流程 → Policy 约束条件。继承方案虽然子类多,但每个子类是自包含的——打开文件就看到所有行为。
- 调试困难。当 Agent 行为异常时,可能是 Capability 的工具白名单遗漏、Strategy 的阶段配置错误、或 Policy 的阈值不合理——三个维度都要排查。继承方案的调试范围更小。
- 概念学习成本。新加入的开发者需要理解 Capability/Strategy/Policy 三个抽象以及它们如何正交组合,才能读懂一个 Preset 的含义。这比"打开 ChatAgent.ts 看代码"的门槛更高。
Alembic 接受了这些代价,因为收益更大——13 个组件覆盖了 5 个 Preset 和无限种运行时覆盖组合。当 Agent 的行为种类从 5 种增长到 10 种、15 种时,正交组合的优势会越来越明显。
小结
正交组合的设计可以归结为一个核心洞察:Agent 不是类型,是配置。
三个维度各自回答一个独立的问题:Capability 回答"能做什么",Strategy 回答"怎么做",Policy 回答"边界在哪"。三个维度的变化互不影响——新增一种 Capability 不需要修改任何 Strategy 或 Policy,新增一种 Policy 不需要修改任何 Capability 或 Strategy。正交的代价是间接性和调试复杂度,收益是
Preset 扮演了"模板"的角色——不是限制组合自由度,而是提供经过验证的推荐配置。开发者通过 Preset 获得合理的默认值,通过 overrides 做精细调整,通过 CapabilityRegistry.register() 扩展新能力。这三层机制形成了 "约定 > 配置 > 编码" 的渐进调整能力。
下一章展开 Agent 的"手"和"脑"——61+ 工具体系和多层记忆系统。
下一章