工具体系与记忆系统
60 个工具是 Agent 的手,多层记忆是 Agent 的脑 — 动态锻造让工具自我演化。
问题场景
Agent 的推理循环需要与外部世界交互:查询知识库、分析 AST、检查代码合规性、读写文件。每一种交互就是一个工具(Tool)。Alembic 有 60 个内置工具,分布在 12 个子模块中。
管理 60 个工具带来三个工程问题:
- 注册与发现。LLM 不能一次接收 60 个工具的 schema——上下文窗口装不下,且太多选择会降低决策质量。需要按 Capability 过滤,只暴露当前任务需要的工具。
- 安全执行。
run_safe_command可以执行终端命令,write_project_file可以写入文件——LLM 可能幻觉出危险操作。每次工具调用前必须经过安全检查。 - 结果压缩。
search_project_code可能返回几千行搜索结果,直接塞进上下文会撑爆 token 预算。需要按工具类型做智能压缩。
同时,Agent 需要记住之前做过什么——不只是当前对话的上下文,还有跨会话的长期记忆。一个月前分析过的模块结构不应该每次都重新分析。但记忆不能无限增长——500 条记忆的存储上限意味着必须有遗忘和整合机制。
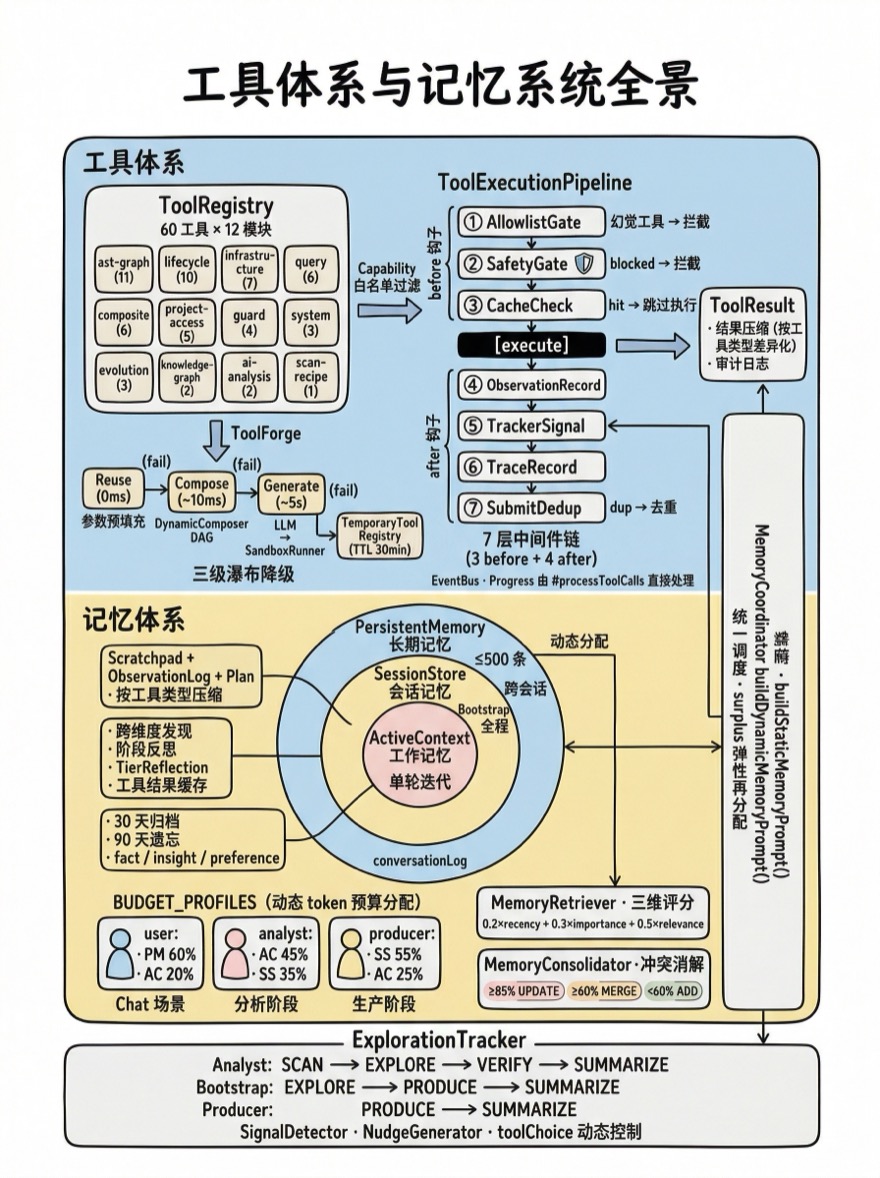
设计决策
ToolRegistry — 注册与发现
每个工具通过统一协议注册到 ToolRegistry——一个名字、一段描述、一份 JSON Schema 参数定义、一个异步处理函数:
// lib/agent/tools/ToolRegistry.ts
interface ToolDefinition {
name: string; // snake_case 唯一标识
description: string; // LLM 可读的功能描述
parameters?: Record<string, unknown>; // JSON Schema
handler: (params: Record<string, unknown>,
context: Record<string, unknown>) => Promise<unknown>;
}60 个工具按职责分布在 12 个子模块中:
| 子模块 | 工具数 | 职责 |
|---|---|---|
| ast-graph | 11 | 类层次、协议信息、方法覆写、调用图、代码图谱查询 |
| lifecycle | 10 | 候选提交、审核、发布、废弃、质量评分、候选校验、反馈统计 |
| infrastructure | 7 | Bootstrap、技能管理、影响分析、审计日志 |
| query | 6 | Recipe/Candidate 搜索、统计、知识检索 |
| composite | 6 | 多工具组合操作(analyze_code、submit_with_check 等) |
| project-access | 5 | 代码搜索、文件读取、项目结构、语义搜索 |
| guard | 4 | Guard 规则列表、合规检查、建议、违规查询 |
| system-interaction | 3 | 终端命令执行、文件写入、环境信息 |
| evolution-tools | 3 | 进化提案、废弃确认、跳过决策 |
| knowledge-graph | 2 | 去重检查、知识关系边添加 |
| ai-analysis | 2 | 候选富化、Bootstrap 候选精炼 |
| scan-recipe | 1 | 扫描模式的运行时候选收集 |
getToolSchemas(allowedTools?) 方法接受一个工具名白名单(来自 Capability 的 tools 属性),只返回白名单内工具的 schema——不含 handler 函数,只有 LLM 需要的信息。Chat Preset 通常暴露约 20 个工具,Insight Preset 暴露约 15 个。这个过滤机制是 Capability 系统(Ch14)的工程落脚点——Capability 声明"我能用什么工具",ToolRegistry 执行"只暴露这些工具"。
参数归一化
不同 AI 模型(Gemini / GPT / Claude / DeepSeek)在函数调用时对参数名的处理不一致——有的传 file,有的传 filePath,有的传 file_path。ToolRegistry 在执行工具前做三层参数归一化:
// lib/agent/tools/ToolRegistry.ts
const PARAM_ALIASES = {
file: 'filePath', filepath: 'filePath', file_path: 'filePath',
query: 'pattern', search: 'pattern', regex: 'pattern',
is_regex: 'isRegex', max_results: 'maxResults',
// ... 20+ 别名映射
};
// 归一化流程:
// 1. 精确匹配 schema 定义的参数名 → 保留
// 2. snake_case → camelCase 自动转换
// 3. PARAM_ALIASES 映射表匹配
// 4. 未匹配的参数透传(handler 自行处理)这个设计让工具 handler 只需处理一种参数格式,而不用为每个 AI 模型写适配逻辑。
ToolExecutionPipeline — 中间件链
ToolRegistry 负责注册和参数归一化,ToolExecutionPipeline 负责安全执行。灵感来自 Express.js 的中间件模式——工具调用经过一条中间件链,每个中间件可以拦截、记录或修改调用:
// lib/agent/core/ToolExecutionPipeline.ts
interface ToolMiddleware {
name: string;
before?: (call: ToolCall, ctx: ToolExecContext, metadata: ToolMetadata)
=> BeforeVerdict | void;
after?: (call: ToolCall, result: unknown, ctx: ToolExecContext, metadata: ToolMetadata)
=> void;
}7 个内置中间件按顺序执行——before 钩子在工具执行前运行,after 钩子在执行后运行(EventBusPublisher 和 ProgressEmitter 不在默认管道中,由 #processToolCalls 直接处理):
| 序号 | 中间件 | 阶段 | 职责 |
|---|---|---|---|
| 1 | AllowlistGate | before | 拒绝不在当前 Capability 允许列表中的工具(防御 LLM 幻觉工具) |
| 2 | SafetyGate | before | SafetyPolicy 拦截:检查命令黑名单和文件路径白名单 |
| 3 | CacheCheck | before | MemoryCoordinator 缓存命中检查——命中则跳过执行 |
| 4 | ObservationRecord | after | 向 ActiveContext 的 ObservationLog 记录调用结果 |
| 5 | TrackerSignal | after | 更新 ExplorationTracker 的探索指标(uniqueFiles、searchRounds 等) |
| 6 | TraceRecord | after | 向 ActiveContext 的推理链压入工具调用 + 结果 |
| 7 | SubmitDedup | after | 知识提交去重——检查 submittedTitles / submittedPatterns 集合 |
before 钩子可以返回 { blocked: true, reason } 来拦截执行。AllowlistGate 拦截未授权工具,SafetyGate 拦截危险命令(如 rm -rf /),CacheCheck 避免重复执行同一个查询。SubmitDedup 在执行后检查提交结果是否重复,并记录去重信息。
中间件的执行顺序很重要——SafetyGate 必须在 CacheCheck 之前(先确认安全再查缓存),TraceRecord 必须在 ObservationRecord 之后(先记录观察再压入推理链)。
// 执行上下文——中间件共享的状态
interface ToolExecContext {
runtime: AgentRuntime;
loopCtx: LoopContext;
iteration: number;
}
// 执行元数据——中间件可以读写的标记
interface ToolMetadata {
cacheHit: boolean; // CacheCheck 是否命中
blocked: boolean; // SafetyGate 是否拦截
isNew: boolean; // 是否是新信息(TrackerSignal 判定)
durationMs: number; // 执行耗时
dedupMessage?: string; // SubmitDedup 的去重原因
isSubmit?: boolean; // 是否是知识提交工具
}工具的安全边界
工具安全是纵深防御的 Agent 层实现,与 Ch04 的 Constitution/Gateway 形成互补——那里管 MCP 请求级的权限,这里管工具调用级的安全。
project-access 工具的文件操作经过 PathGuard 沙箱检查(Ch04)。read_project_file 只能读取项目目录内的文件,不能越界访问 /etc/passwd 或 ~/.ssh/。
system-interaction 工具的命令执行经过 SafetyPolicy 的双层过滤(Ch14):硬编码危险命令黑名单(rm -rf /、sudo、curl | bash 等)+ 可配置的安全命令白名单(ls、cat、grep、git log 等)。
知识提交工具(submit_knowledge、submit_with_check)经过 SubmitDedup 中间件的去重检查——同一轮 ReAct 循环中不能提交标题或代码模式完全相同的候选。
每次工具调用都通过 EventBusPublisher 中间件记录到审计日志——谁、在什么时候、用什么参数、调用了什么工具、结果是什么。这是 Ch04 六层安全链路中"操作审计"这一层的数据来源。
架构与数据流
ToolForge — 动态锻造
60 个内置工具覆盖了大部分场景,但总有 edge case——Agent 需要"搜索所有 Network 相关的 Recipe 并检查它们的 Guard 规则",没有现成的工具能一步完成。传统做法是让 Agent 分三步调用三个工具,但这消耗了三轮 ReAct 迭代。
ToolForge 解决这个问题:在运行时动态创建新工具。三种锻造模式按成本递增排列,形成瀑布式降级:
Reuse(0ms)→ 直接从注册表复用现有工具
↓ 找不到
Compose(~10ms)→ 组合多个原子工具为新工具
↓ 组合不出来
Generate(~5s)→ LLM 生成工具代码 → SandboxRunner 验证 → 注册Reuse — 参数预填充
最轻量的锻造模式:找到一个已有的工具,预填充部分参数。
需求:"搜索 Network 分类的 Recipe"
匹配:search_recipes(category="Network")
结果:直接复用 search_recipes,无需新建Compose — 多工具编排
DynamicComposer 把多个工具编排为一个组合工具,通过声明式的 CompositionSpec 定义执行图:
// lib/agent/forge/DynamicComposer.ts
interface CompositionSpec {
name: string;
description: string;
steps: CompositionStep[];
mergeStrategy: 'sequential' | 'parallel';
parameters?: Record<string, unknown>;
}
interface CompositionStep {
tool: string; // 原子工具名
args: Record<string, unknown> // 静态参数
| ((prevResult: unknown) => Record<string, unknown>); // 动态参数
extractKey?: string; // 从结果中提取字段传给下一步
}sequential 模式下,step 2 的输入可以引用 step 1 的输出——args 接受一个函数,参数是上一步的结果。parallel 模式下,所有 step 并行执行,结果合并。
例如,analyze_module 工具可以定义为:
Step 1: get_class_hierarchy(module="Payment")
→ extractKey: "classes"
Step 2: (prevResult) => detect_patterns(classes=prevResult.classes)
→ extractKey: "patterns"
Step 3: (prevResult) => query_call_graph(classes=prevResult.classes)
→ extractKey: "callGraph"
Merge: { classes, patterns, callGraph }三步操作浓缩为一次工具调用——Agent 只消耗一轮 ReAct 迭代。
Generate — LLM 生成
最重量级的模式:当 Reuse 和 Compose 都无法满足需求时,LLM 根据自然语言描述生成工具的 TypeScript 代码,SandboxRunner 在隔离环境中执行测试用例验证安全和正确性,通过后注册到 TemporaryToolRegistry。
// lib/agent/forge/ToolForge.ts
interface GeneratedTool {
name: string;
description: string;
parameters: Record<string, unknown>;
code: string; // 必须包含 toolHandler 函数
testCases: SandboxTestCase[]; // 至少一个测试用例
}安全约束:生成的代码只能调用已注册的工具和白名单 API,不能直接访问文件系统或网络。SandboxRunner 的隔离环境没有 fs、net、child_process 等危险模块。
TemporaryToolRegistry 给生成的工具设定 TTL(默认 30 分钟)——会话结束后自动清理,不会污染全局注册表。
// lib/agent/forge/ToolForge.ts
interface ForgeResult {
success: boolean;
mode: 'reuse' | 'compose' | 'generate';
toolName?: string;
error?: string;
}Tool 锻造的深层洞察:从开发者创造到用户创造
ToolForge 的设计不仅仅是一个工程优化——它背后有一个关于 Agent 助手未来形态的深层思考。
观察当前的 AI 工具生态,主流模式是开发者创造 Tool,用户消费 Tool。以 OpenClaw 为例:技能开发者编写 Skill 并发布到平台,普通用户下载大量 Skill 来扩展 Agent 的能力。这个模式的本质是传统的"开发者→用户"单向链路——与 App Store 的模式如出一辙,只是把"App"换成了"Skill"。
但这个模式有一个结构性局限:每个领域的专业知识都封锁在从业者的脑中,而不在开发者的工具里。一个建筑师知道什么样的结构布局最合理,一个医生知道什么样的检查流程最高效,一个量化交易员知道什么样的风控规则最有效——但他们不会写代码,也没有能力把自己的专业知识转化为 Agent 可以调用的 Tool。
Agent 助手的真正未来,不应该是"普通人使用开发者创造的 Tool",而应该是**"普通人自己创造 Tool 给自己使用"**。每个领域的专业人士,应该能用自然语言描述自己的工作流("先检查这三个指标,如果都在正常范围内就执行下一步,否则标记为异常"),Agent 助手将这段描述转化为可执行的 Tool,然后该专业人士在日常工作中反复使用和迭代这个 Tool。
这就是 ToolForge 三级瀑布设计中 Generate 模式的深层意义。表面上看,它是 Agent 在运行时动态生成工具来解决 edge case;但从产品愿景看,它是通往"用户创造 Tool"的技术基础。Generate 模式的核心链路——自然语言描述 → LLM 生成代码 → 沙箱验证 → 注册为可调用工具——恰好就是"专业人士用自然语言定义工作流,系统将其转化为可复用 Tool"的原型。
基于这个洞察,Alembic 在 ToolForge 之上增加了 Tool 锻造的显式设计:
- Forge 即创造:用户(通过 Agent 对话)描述一个重复性的工作流需求,系统将其锻造为持久化的 Tool,而不是一次性的临时工具。
- Skill 即沉淀:锻造出的 Tool 经过实际使用和验证后,可以提升为 Skill——具有文档、参数 schema 和使用示例的成熟工具定义。
- 从个人到团队:一个人锻造的 Tool 如果被验证有效,可以通过知识库分享给团队,成为团队的标准工作流。
这种"自下而上"的工具生态——用户根据自己的专业领域锻造 Tool,而非等待开发者为其编写——才是 Agent 助手从"通用助手"进化为"领域专家协作伙伴"的关键路径。
多层记忆体系
Alembic 的记忆系统借鉴了 CoALA 认知架构(Sumers & Yao et al., arXiv:2309.02427, TMLR 2024)和 Generative Agents 论文(Park et al., arXiv:2304.03442, UIST 2023)中的记忆模型,将记忆分为三个层级——工作记忆(秒级)、会话记忆(分钟级)、持久记忆(天级)。三层的读写速度、容量和生命周期各不相同:
| 层级 | 类 | 容量 | 生命周期 | 用途 |
|---|---|---|---|---|
| 工作记忆 | ActiveContext | 按 profile 动态分配 | 单轮迭代 | 当前搜索结果、文件内容、中间推理 |
| 会话记忆 | SessionStore | 按 profile 动态分配 | 一次 Bootstrap 会话 | 跨维度发现、阶段反思、工具结果缓存 |
| 持久记忆 | PersistentMemory | ≤500 条 | 跨会话(30 天归档,90 天遗忘) | 模块分析结果、用户偏好、项目洞察 |
MemoryCoordinator 横跨三层,负责 token 预算分配和统一读写调度。
ActiveContext — 工作记忆
ActiveContext 是单轮 ReAct 迭代的状态容器——Agent 在一轮中搜索了什么、读取了什么文件、发现了什么线索,都记录在这里。它由三个内部区域组成:
- Scratchpad(便签)——Agent 通过
note_finding工具主动标记的重要发现。不会被压缩淘汰,是 Agent 的"显式笔记"。 - ObservationLog(观察日志)——每轮 ReAct 循环的工具调用结果。自动记录,滑动窗口淘汰旧记录。
- Plan(计划)——来自 ExplorationTracker 的阶段计划信息。
// lib/agent/memory/ActiveContext.ts
class ActiveContext {
startRound(iteration: number) // 开始新一轮
note_finding(finding: string, evidence?: string) // 标记发现
getRecentSummary(count?: number) // 获取最近 N 轮摘要
buildContext(): string // 构建提示词注入
distill(): string // 蒸馏为精简摘要
}关键设计:按工具类型压缩。不同工具的结果有不同的信息密度——search_project_code 返回的几千行搜索结果需要压缩为"搜索了 N 个文件,命中 M 处",而 get_class_info 返回的类结构信息本身就很精炼:
| 工具 | 压缩策略 |
|---|---|
search_project_code | 保留文件列表 + 匹配行数概要 |
read_project_file | 保留文件名 + 行数统计 |
get_class_info | 保留类名、继承关系、协议列表 |
submit_knowledge | 保留提交状态(成功/失败/原因) |
这种按工具类型的差异化压缩比统一截断更高效——150 行搜索结果截断后可能丢失关键匹配行,而压缩为"在 NetworkKit.swift、APIClient.swift、RequestBuilder.swift 中找到 12 处匹配"则保留了最重要的信号。
SessionStore — 会话记忆
SessionStore 为 Bootstrap 冷启动场景设计——一次冷启动可能扫描 25 个维度,每个维度跑一个独立的 Pipeline。维度之间需要共享发现:如果 "architecture" 维度发现了一个 Singleton 模式,"conventions" 维度就不需要重复分析。
// lib/agent/memory/SessionStore.ts
interface Finding {
finding: string; // 发现内容
evidence?: string; // 证据(文件路径 + 代码片段)
importance: number; // 重要度 1–10
dimId?: string; // 来源维度
timestamp?: number;
}
class SessionStore {
addEvidence(filePath: string, evidence: Evidence): void
getDimensionReport(dimId: string): DimensionReport
getCompletedDimensions(): string[]
getDistilledForProducer(dimId: string): DistilledContext
buildContextForDimension(dimId: string): string
}SessionStore 维护两种状态:按维度的发现列表(每个维度独立)和跨维度的模式引用(共享的洞察)。getDistilledForProducer 方法为知识生产阶段提供蒸馏后的上下文——只包含当前维度的发现和其他维度中相关的交叉引用,避免把 25 个维度的全部发现塞进一个 Pipeline 阶段的上下文。
SessionStore 还有阶段反思机制:每完成一个 tier(高优维度 / 中优维度 / 低优维度),生成一个 TierReflection 摘要——已完成的维度、TOP 发现、跨维度模式。这个反思摘要注入到下一个 tier 的分析上下文中,让后续维度受益于前序分析。
非缓存工具列表:submit_knowledge、submit_with_check、note_finding 等副作用工具的结果不会被 SessionStore 缓存——它们的调用结果是一次性的("提交成功"),缓存毫无意义。
PersistentMemory — 持久记忆
PersistentMemory 是跨会话的长期记忆——模块分析结果、用户偏好、项目洞察都存在这里。底层由三个组件支撑:
- MemoryStore——SQLite 持久化层,
semantic_memories表存储所有记忆条目。 - MemoryRetriever——三维评分检索引擎。
- MemoryConsolidator——冲突检测和记忆整合。
每条记忆有类型、来源、重要度和过期时间:
// lib/agent/memory/PersistentMemory.ts
interface MemoryInput {
type?: 'fact' | 'insight' | 'preference'; // 事实 / 洞察 / 偏好
content: string; // 记忆内容
source?: 'bootstrap' | 'user' | 'system'; // 来源
importance?: number; // 重要度 1.0–10.0
ttlDays?: number | null; // 过期天数
sourceDimension?: string; // Bootstrap 来源维度
}容量治理:最多 500 条记忆(MAX_MEMORIES)。超过上限时 enforceCapacity() 按 access_count × importance 排序淘汰。30 天未访问的记忆自动归档(ARCHIVE_DAYS),90 天未访问的自动删除(FORGET_DAYS)。
MemoryRetriever — 三维评分
记忆检索不是简单的关键词匹配——一条记忆可能内容相关但已经过时,另一条内容稍远但很重要且最近被频繁访问。MemoryRetriever 借鉴 Generative Agents(Park et al., 2023)论文的三维评分公式:
| 维度 | 权重 | 计算方式 |
|---|---|---|
| 时效性(recency) | 0.2 | 指数衰减,7 天半衰期: |
| 重要度(importance) | 0.3 | 归一化到 [0, 1] |
| 相关性(relevance) | 0.5 | 词法重叠 + 向量余弦相似度(可用时) |
向量相似度是可选的——如果 AI 断路器打开或嵌入服务不可用,退化为纯词法匹配。与 Ch11 搜索引擎的降级策略一脉相承:核心功能不依赖 AI 可用性。
MemoryConsolidator — 冲突消解
当 Agent 生成新记忆时,需要与已有记忆进行冲突检测和整合。MemoryConsolidator 借鉴 Mem0(Chhikara et al., arXiv:2504.19413, ECAI 2025)的整合策略,分两阶段执行:
阶段 1:冲突预消解。检测新记忆与已有记忆的矛盾——通过否定模式匹配(英文 "don't"、"never";中文 "不"、"禁止")和主题重叠检测。如果新旧记忆在同一主题上矛盾,用新记忆替换旧记忆(假设最新信息更准确)。
阶段 2:标准整合。对非矛盾的记忆做相似度检测:
| 相似度 | 决策 | 说明 |
|---|---|---|
| ≥ 85% | UPDATE | 内容几乎相同,更新元数据(时间戳、访问次数) |
| ≥ 60% | MERGE | 内容有重叠,合并为一条更完整的记忆 |
| < 60% | ADD | 内容足够不同,作为新记忆添加 |
// lib/agent/memory/MemoryConsolidator.ts
interface ConsolidateStats {
added: number;
updated: number;
merged: number;
skipped: number;
replaced?: number; // 冲突预消解中被替换的
}MemoryCoordinator — 统一调度
MemoryCoordinator 是三层记忆的唯一入口——所有记忆操作(读、写、检索、整合)都通过它路由到正确的层级。
最关键的职责是 token 预算分配。上下文窗口的 token 有限——不可能把三层记忆全部注入。MemoryCoordinator 按角色 profile 动态分配预算(默认总预算 4000 token):
// lib/agent/memory/MemoryCoordinator.ts
// 三种 profile,按 Agent 角色选择
const BUDGET_PROFILES = {
user: { activeContext: 0.20, sessionStore: 0, persistentMemory: 0.60, conversationLog: 0.20 },
analyst: { activeContext: 0.45, sessionStore: 0.35, persistentMemory: 0.15, conversationLog: 0.05 },
producer: { activeContext: 0.25, sessionStore: 0.55, persistentMemory: 0.15, conversationLog: 0.05 },
};user profile(Chat 场景):PersistentMemory 占 60%——对话中长期记忆最重要,SessionStore 为 0(无维度扫描上下文)。analyst profile(分析阶段):ActiveContext 占 45%——当前搜索的工具结果最重要;SessionStore 占 35%——跨维度发现很有价值。producer profile(生产阶段):SessionStore 占 55%——需要大量前序分析摘要来生成高质量候选。
总预算默认 4000 token,但也可以从模型上下文窗口动态计算——configure({ totalContextBudget }) 按 12.5% 比例分配记忆预算(例如 1M 窗口 → 128000 token 记忆预算)。
记忆注入分为静态 + 动态两阶段:
buildStaticMemoryPrompt()——Pipelineexecute()入口调用一次。按顺序组装 PersistentMemory → SessionStore → ConversationLog,每层有独立 token 预算。未用完的预算累积为 surplus。buildDynamicMemoryPrompt()——每轮 ReAct 迭代调用。ActiveContext 的实际预算 = 自身分配 + 静态阶段的剩余 surplus。
这个弹性预算再分配机制很关键:如果 PersistentMemory 只有 3 条记忆、远没用完 60% 预算,多余 token 自动流向 ActiveContext,让工作记忆有更多空间装载当前搜索结果。
// 静态阶段: 每层实际使用 < 预算 → 剩余累积
surplus += Math.max(0, pmBudget - used);
// 动态阶段: ActiveContext 获得自身预算 + 全部 surplus
const acBudget = allocation.activeContext + surplus;MemoryCoordinator 还提供 getMessageBudget() 来计算对话消息的可用空间:
token 估算使用 CJK 感知的粗略算法——中文字符按 1/2 计,其余按 1/4 计——不依赖外部 tokenizer 库。
核心实现
ExplorationTracker — 探索状态机
ExplorationTracker 是 Agent 的"教练"——不执行具体任务,但控制 Agent 的注意力方向和节奏。它跟踪 Agent 已经探索了什么(搜索了哪些文件、调用了多少次工具、提交了多少候选),据此决定阶段转换和行为引导。
五个阶段
type ExplorationPhase = 'SCAN' | 'EXPLORE' | 'PRODUCE' | 'VERIFY' | 'SUMMARIZE';不是所有任务都经历全部五个阶段。三种策略预设对应不同的阶段组合:
| 策略 | 阶段链 | 适用场景 |
|---|---|---|
| Bootstrap | EXPLORE → PRODUCE → SUMMARIZE | 冷启动知识提取(有提交阶段) |
| Analyst | SCAN → EXPLORE → VERIFY → SUMMARIZE | 纯分析任务(无提交,有验证) |
| Producer | PRODUCE → SUMMARIZE | 格式化 + 提交(无搜索阶段) |
阶段转换条件
转换不是按迭代次数机械触发的——而是基于指标驱动的动态判定:
// lib/agent/context/ExplorationTracker.ts
interface ExplorationMetrics {
iteration: number; // 当前迭代
submitCount: number; // 已提交候选数
searchRoundsInPhase: number; // 当前阶段的搜索轮数
phaseRounds: number; // 当前阶段已执行轮数
roundsSinceSubmit: number; // 距上次提交的轮数
roundsSinceNewInfo: number; // 距上次新信息的轮数
consecutiveIdleRounds: number; // 连续空闲轮数
}以 Bootstrap 策略的 EXPLORE → PRODUCE 转换为例:
// 当以下任一条件满足时触发转换:
'EXPLORE→PRODUCE': {
onMetrics: (m, b) =>
m.submitCount > 0 || // 已经有提交了
m.searchRoundsInPhase >= b.searchBudget, // 搜索预算耗尽
onTextResponse: true // Agent 发了纯文本(认为搜索阶段结束)
}PRODUCE → SUMMARIZE 的转换更细腻:
'PRODUCE→SUMMARIZE': {
onMetrics: (m, b) =>
m.submitCount >= b.maxSubmits || // 提交数到达上限(10)
(m.submitCount > 0 &&
m.roundsSinceSubmit >= b.idleRoundsToExit) || // 提交后连续 3 轮无新提交
(m.consecutiveIdleRounds >= b.searchBudgetGrace
&& m.submitCount === 0) // 一直没提交且空闲太久
}这种指标驱动的转换比固定轮数更智能——如果 Agent 在第 3 轮就搜索完了所有相关代码,不需要等到第 18 轮(searchBudget)才进入 PRODUCE 阶段。
探索预算
// lib/agent/context/ExplorationTracker.ts
interface ExplorationBudget {
maxIterations: number; // 24(硬限制)
searchBudget: number; // 18(搜索阶段最大轮数)
searchBudgetGrace: number; // 10(空闲容忍度)
maxSubmits: number; // 10(最大提交数)
softSubmitLimit: number; // 8(软上限,超过后倾向收尾)
idleRoundsToExit: number; // 3(提交后空闲 3 轮则退出)
}softSubmitLimit(8)和 maxSubmits(10)的双重限制体现了一种"柔性约束"思想——超过 8 个提交后 ExplorationTracker 开始引导 Agent 收尾,但不强制终止;到 10 个才硬性切断。这给了 Agent 2 个"缓冲提交"的空间,避免在第 9 个高质量候选面前被迫放弃。
toolChoice 动态控制
ExplorationTracker 还控制 LLM 的 toolChoice 参数——即 LLM 是否必须调用工具:
| 阶段 | toolChoice | 含义 |
|---|---|---|
| SCAN / EXPLORE | auto | LLM 自行决定是否调用工具 |
| PRODUCE | auto 或 required | 鼓励或强制调用提交工具 |
| SUMMARIZE | none | 禁止工具调用,只输出文本总结 |
SUMMARIZE 阶段设为 none 是关键——防止 Agent 在总结阶段"手痒"又去搜索代码,浪费最后几轮宝贵的迭代预算。
NudgeGenerator — 行为引导
当 Agent 进入"死循环"(反复搜索同一个关键词)或"迷失方向"(不知道下一步该做什么)时,NudgeGenerator 生成一段引导提示词注入到下一轮的系统消息中。
五种 Nudge 类型按优先级队列排列——高优先级 Nudge 覆盖低优先级:
| 优先级 | 类型 | 触发条件 | 引导内容 |
|---|---|---|---|
| 1(最高) | force_exit | 迭代耗尽 | "请总结你的发现并结束" |
| 2 | convergence | 连续 3+ 轮无新信息且已探索 ≥ 10 轮 | "信息已饱和,考虑转入下一阶段" |
| 3 | budget_warning | 已消耗 75% 迭代预算 | "预算剩余 25%,优先完成核心任务" |
| 4 | reflection | 每 5 轮 或反思过时 | "回顾已有发现,检查是否遗漏维度" |
| 5 | planning | PlanTracker 触发 | "根据计划执行下一步" |
// lib/agent/context/exploration/NudgeGenerator.ts
interface Nudge {
type: 'force_exit' | 'convergence' | 'budget_warning' | 'reflection' | 'planning';
text: string; // 注入到系统消息的引导文本
}注意:
planning类型的 Nudge 由PlanTracker(而非 NudgeGenerator)负责触发和生成文本。NudgeGenerator 只是统一的输出接口。
convergence Nudge 的效果最显著。没有它时,Agent 经常在第 10-15 轮陷入"搜索 X → 没新结果 → 换个词搜 X → 还是没新结果"的死循环。有了 convergence Nudge,Agent 被告知"信息已饱和",从而转入 PRODUCE 或 SUMMARIZE 阶段——平均节省 3-5 轮无效迭代。
NudgeGenerator 还负责阶段转换提示——当 ExplorationTracker 决定从 EXPLORE 切换到 PRODUCE 时,NudgeGenerator 生成一段过渡提示词:"分析阶段结束。请基于以下发现生成知识候选:[蒸馏摘要]"。这确保 Agent 在阶段切换时有清晰的上下文传递。
SignalDetector — 探索进度追踪
ExplorationTracker 的指标不是凭空产生的——SignalDetector 分析每次工具调用的结果,提取出"是否有新信息"的信号。
// lib/agent/context/exploration/SignalDetector.ts
export const SEARCH_TOOLS = new Set([
'search_project_code', 'semantic_search_code',
'get_class_info', 'get_class_hierarchy',
'get_protocol_info', 'get_method_overrides',
'list_project_structure', 'get_project_overview',
'query_code_graph', 'query_call_graph',
// ... 12 个搜索类工具
]);每种工具有不同的信号提取策略:
search_project_code:检查返回的文件路径是否在uniqueFiles集合中。新文件 → 有新信息;全是已知文件 → 无新信息。同时检查搜索模式是否在uniquePatterns中——重复搜索同一个模式记为空闲轮。read_project_file:文件路径加入uniqueFiles。get_class_info/query_code_graph:查询加入uniqueQueries——但每种查询类型只算一次新信息(第二次查相同类型不算)。submit_knowledge:不产生"新信息"信号——提交数量由独立的submitCount计数器追踪,走不同的转换逻辑。
FullExplorationMetrics 维护了四个 Set 来判定"新":
interface FullExplorationMetrics extends ExplorationMetrics {
uniqueFiles: Set<string>; // 已见过的文件
uniquePatterns: Set<string>; // 已用过的搜索模式
uniqueQueries: Set<string>; // 已执行的查询
totalToolCalls: number; // 总工具调用次数
}ContextWindow — 三级上下文压缩
ContextWindow 管理 LLM 的消息历史——确保 token 使用量不超过预算。三级渐进压缩在 Ch13 已概述,这里补充工具相关的细节:
L1(60-80% 预算):截断旧轮次的工具结果,保留最近 4 轮完整
L2(80-95% 预算):蒸馏旧轮次为摘要,保留最近 2 轮完整
L3(> 95% 预算):只保留系统提示 + 最后 1 轮 + 提交记录设计不变量:messages[0] 永远是原始用户提示(不可变),assistant(toolCalls) + tool results 是原子单元(不可拆分)。这两条规则确保 LLM 在任何压缩级别下都能看到最初的任务描述和最近的完整工具调用结果。
模型感知的 token 预算:不同 AI 模型的上下文窗口不同——Claude Opus/Sonnet 4.6 1M、GPT-5.4 1M、Gemini 3.1 Pro 1M、Claude Haiku 200K、GPT-5.4-mini 400K。ContextWindow 通过模型名正则匹配自动设定预算上限,避免为每个模型手工配置。
运行时行为
场景 1:记忆驱动的智能跳过
Agent(Chat 模式):用户问"Payment 模块的设计模式"
1. MemoryCoordinator.injectStaticMemory():
→ PersistentMemory.retrieve("Payment 设计模式")
→ 命中:[fact] "Payment 模块使用 Coordinator + Repository 模式"
(importance: 8.5, 上周创建, recency: 0.91)
→ 注入系统消息:"已知:Payment 模块使用 Coordinator + Repository 模式"
2. reactLoop() Iter 1:
LLM 看到已有记忆 → 直接引用并扩展回答
→ 省去 get_class_hierarchy + detect_patterns 两次工具调用
→ 1 轮完成(vs 无记忆时 3-4 轮)场景 2:ToolForge 组合锻造
Agent(Insight 模式):分析 NetworkKit 模块的完整架构
1. ForgeRequest: { intent: "分析 NetworkKit 完整架构", action: "analyze", target: "NetworkKit" }
2. Reuse? → 没有现成的 analyze_full_architecture 工具 → 降级
3. Compose? → DynamicComposer 匹配到组合方案:
Step 1: get_class_hierarchy(module="NetworkKit") → classes
Step 2: query_call_graph(classes) → callGraph
Step 3: detect_patterns(classes) → patterns
mergeStrategy: 'sequential'
→ 注册为临时工具 analyze_networkkit(TTL: 30 min)
4. Agent 后续调用 analyze_networkkit → 一次工具调用 = 三步分析
→ 节省 2 轮 ReAct 迭代场景 3:ExplorationTracker 引导收敛
Agent(Bootstrap 模式):扫描 "networking" 维度
Iter 1-5: EXPLORE 阶段
search_project_code("URLSession") → 发现 3 个新文件 ✓
search_project_code("Alamofire") → 发现 2 个新文件 ✓
get_class_hierarchy("NetworkKit") → 新查询 ✓
read_project_file("APIClient.swift") → 新文件 ✓
search_project_code("HTTP") → 发现 1 个新文件 ✓
→ roundsSinceNewInfo: 0, consecutiveIdleRounds: 0
Iter 6-8: 信息开始饱和
search_project_code("request") → 全是已知文件 ✗
search_project_code("response") → 1 个新文件 ✓ (重置空闲计数)
search_project_code("network") → 全是已知文件 ✗
→ roundsSinceNewInfo: 1, consecutiveIdleRounds: 1
Iter 9: NudgeGenerator 触发 convergence
→ "搜索信息趋于饱和。建议开始整理发现并生成知识候选。"
→ ExplorationTracker: EXPLORE → PRODUCE
Iter 10-14: PRODUCE 阶段
submit_knowledge(...) → 成功 ✓ (submitCount: 1)
submit_knowledge(...) → 成功 ✓ (submitCount: 2)
submit_knowledge(...) → 被 SubmitDedup 拦截(重复标题)✗
submit_knowledge(...) → 成功 ✓ (submitCount: 3)
→ roundsSinceSubmit: 0
Iter 15: 连续 3 轮无新提交
→ ExplorationTracker: PRODUCE → SUMMARIZE
→ toolChoice: 'none'
→ Agent 输出文本总结权衡与替代方案
为什么自建工具注册表而非用 LangChain Tool
LangChain 有成熟的 Tool 抽象——StructuredTool、DynamicTool、ToolKit。Alembic 为什么重新实现?
- DI 深度集成。Alembic 的每个工具 handler 通过
context.container访问ServiceContainer依赖注入——KnowledgeService、GuardService、AstService 等服务按需获取。LangChain Tool 有自己的初始化模型(_call方法),与 ServiceContainer 的生命周期不兼容。 - 参数归一化。20+ 别名映射 + snake_case → camelCase 自动转换是 Alembic 特有的需求——不同 AI 模型的参数命名差异在 LangChain 层面不被处理。
- 中间件链。LangChain Tool 的执行是"调一下就完了",没有 before/after 中间件。Alembic 需要 AllowlistGate、SafetyGate、CacheCheck、SubmitDedup、TrackerSignal 等 7 层中间件——这些横切关注点用 LangChain 实现需要大量包装代码。
总成本:ToolRegistry 约 300 行 + ToolExecutionPipeline 约 400 行 = 700 行自建代码,换来与 DI 系统的无缝集成和 8 层安全/缓存/追踪中间件。
为什么记忆不用 Redis
PersistentMemory 使用 SQLite 本地存储(通过 MemoryStore),而非 Redis 或 Pinecone 等外部服务。原因是 Alembic 的"零外部依赖"原则——整个系统可以在开发者的笔记本上运行,不需要启动任何后台服务。
500 条记忆上限 × 平均 200 字 ≈ 100KB 数据。SQLite 处理这个量级的读写延迟在 1ms 以内。如果未来记忆量增长到数万条(多项目共享),SQLite 仍然够用——它在百万行级别的性能表现远超这个需求。
向量检索(MemoryRetriever 的 relevance 维度)也是本地化的——使用 Ch11 中相同的 JsonVectorAdapter 或内存中的余弦相似度计算。没有外部向量数据库依赖。
ToolForge 的安全风险
Generate 模式让 LLM 生成并执行代码——这是潜在的安全风险。Alembic 的缓解措施:
- SandboxRunner 隔离:生成的代码在沙箱环境中运行,没有
fs、net、child_process模块访问权限。 - 只能调用已注册工具:生成的工具 handler 只能通过 ToolRegistry 调用其他工具,不能直接访问底层 API。
- TemporaryToolRegistry TTL:生成的工具 30 分钟后自动清理,不会持久存在。
- 测试用例强制:每个生成的工具必须附带至少一个
SandboxTestCase,测试通过后才注册。
即使如此,Generate 模式在生产环境中默认关闭——只在 ASD_ENABLE_FORGE_GENERATE=true 环境变量设置时启用。Reuse 和 Compose 模式没有安全风险,是默认启用的。
前沿定位 — Agent 记忆系统的学术谱系
Alembic 的记忆系统并非凭空设计——它站在 2023–2025 年 Agent 记忆研究快速演进的肩膀上。本节将 Alembic 的具体实现映射到学术文献,帮助读者理解设计选择的理论根源和工程取舍。
认知科学分类法
认知科学早在 AI 之前就建立了成熟的记忆分类体系。CoALA(Cognitive Architectures for Language Agents,Sumers & Yao et al., TMLR 2024)将这套分类法引入 LLM Agent 领域,定义了三种记忆类型:
| 认知科学分类 | CoALA 定义 | Alembic 对应 | 实现 |
|---|---|---|---|
| 情景记忆(Episodic) | 具体事件的时序序列 | ActiveContext.ObservationLog | 每轮工具调用 + 结果的有序记录 |
| 语义记忆(Semantic) | 抽象事实和概念 | PersistentMemory(fact/insight) | SQLite 持久化,三维评分检索 |
| 程序记忆(Procedural) | 技能和行为模式 | ToolRegistry + ToolForge | 60 个工具 + 运行时动态锻造 |
这个映射揭示了一个有趣的设计决策:Alembic 把程序记忆外化为工具而非内化为提示词模板。大多数 Agent 框架将"如何分析代码"编码在系统提示词中(程序记忆 = 硬编码提示词),而 Alembic 将其拆解为可组合的工具(程序记忆 = 可发现、可组合、可演化的工具集合)。ToolForge 的 Generate 模式更进一步——Agent 可以在运行时创造新的程序记忆。
CoALA 还引入了 working memory(工作记忆)的概念——有限容量的暂存区,用于当前推理步骤。Alembic 的 ActiveContext 精确实现了这一概念,甚至更细致地将其分为 Scratchpad(显式笔记)、ObservationLog(自动记录)和 Plan(计划信息)三个子区域。
记忆系统演化谱系
从 2023 年至 2025 年,Agent 记忆系统经历了四个代际:
第一代:Generative Agents(2023)
Park et al. 的 Generative Agents(arXiv:2304.03442)首次在 LLM Agent 上实现了完整的记忆 → 检索 → 反思循环。其核心贡献是三维评分检索:
Alembic 的 MemoryRetriever 直接采用了这个公式(
- 时效性计算:Generative Agents 使用线性衰减,Alembic 改用指数衰减(7 天半衰期),使记忆淡出曲线更符合人类遗忘的 Ebbinghaus 特征。
- 缺少向量降级:Generative Agents 强依赖 embedding 计算 relevance,断网即瘫痪。Alembic 在 embedding 不可用时退化为词法重叠评分——核心功能不依赖 AI 服务可用性。
Generative Agents 的反思机制(每 100 次观察生成一次高级反思)启发了 SessionStore 的 TierReflection——Alembic 在每个 tier 完成后生成反思摘要,但使用规则聚合而非 LLM 生成,确保确定性和低成本。
第二代:MemGPT/Letta(2023–2024)
Packer et al. 的 MemGPT(arXiv:2310.08560)将操作系统的虚拟内存概念引入 Agent——LLM 的有限上下文窗口类比为"物理内存",外部存储类比为"磁盘",Agent 通过类似 page_fault 的中断机制自主管理数据在两层之间的换入换出。
Alembic 的 MemoryCoordinator 解决的是同一问题——有限上下文窗口下的多层记忆调度——但采用了不同的架构策略:
| 维度 | MemGPT | Alembic |
|---|---|---|
| 调度模型 | Agent 自主换页(LLM 决定读/写哪层) | 预算分配 + 弹性 surplus(系统自动调度) |
| 记忆层数 | 2 层(main context + external storage) | 4 层(ActiveContext / SessionStore / PersistentMemory / ConversationLog) |
| 预算控制 | 无显式 token 预算 | 三种 role profile × 百分比预算 |
| 上下文压缩 | 递归摘要(摘要的摘要) | 三级渐进压缩(截断 → 蒸馏 → 紧急裁剪) |
| 外部依赖 | 需要 PostgreSQL/pgvector | 纯 SQLite,零外部依赖 |
MemGPT 的"Agent 自主换页"设计很优雅,但有一个实际问题:LLM 决策本身消耗 token 和推理时间。每次 core_memory_append() 或 archival_memory_search() 都是一次工具调用,会额外消耗 1 轮 ReAct 迭代。Alembic 选择系统级自动调度——MemoryCoordinator 在每轮开始时自动注入最相关的记忆,Agent 不需要"手动管理记忆",可以专注于任务本身。代价是灵活性略低:Agent 不能在运行时主动选择"把这条信息存入长期记忆",必须通过 note_finding 工具间接实现。
第三代:Zep/Graphiti(2025)
Rasmussen et al. 的 Zep(arXiv:2501.13956)引入了时序知识图谱(Temporal Knowledge Graph)作为 Agent 记忆的核心存储——不再是扁平的向量数据库,而是包含实体节点、关系边和时间戳的结构化图。在 Deep Memory Retrieval(DMR)基准上以 94.8% 超过 MemGPT 的 93.4%,在更复杂的 LongMemEval 基准上准确率提升最高达 18.5%,同时延迟降低 90%。
Alembic 的 knowledge-graph 工具模块(dedup_check、add_knowledge_edge)是朝这个方向的初步实现——在知识候选间建立关系边,支持去重和关联查询。但与 Zep 相比,Alembic 的图结构是事后补充的(候选提交后再加边),而非 Zep 那样在实时对话中动态提取实体和关系。
第四代:Mem0(2025)
Chhikara et al. 的 Mem0(arXiv:2504.19413,ECAI 2025)提出了面向生产的两阶段记忆管线:
Extraction Phase → 从最新对话/滚动摘要/最近 m 条消息中提取候选记忆
Update Phase → 新记忆与 top-s 相似旧记忆对比 → ADD / UPDATE / DELETE / NOOP在 LOCOMO 基准上,Mem0 比 OpenAI 的内置 Memory 准确率高 26%(66.9% vs 52.9%),p95 延迟降低 91%(1.44s vs 17.12s),token 消耗减少 90%(~1.8K vs ~26K)。
Alembic 的 MemoryConsolidator 与 Mem0 的 Update Phase 高度相似——都执行相似度驱动的四选一决策。对比:
| 操作 | Mem0 | Alembic |
|---|---|---|
| 新增 | ADD | ADD(相似度 < 60%) |
| 更新 | UPDATE | UPDATE(相似度 ≥ 85%) |
| 合并 | — | MERGE(60% ≤ 相似度 < 85%) |
| 删除/替换 | DELETE | REPLACE(冲突预消解:否定模式检测) |
| 跳过 | NOOP | SKIP |
Alembic 比 Mem0 多了一个 MERGE 操作——两条相关但不完全重复的记忆合并为一条更完整的记忆。Mem0 的 DELETE 是简单的矛盾覆盖,Alembic 的 REPLACE 通过否定模式匹配("不"、"禁止"、"never")主动检测语义矛盾——更精细但也更脆弱(依赖模式匹配而非语义理解)。
Mem0ᵍ(图增强变体)用有向标记图存储记忆——Entity Extractor 提取实体节点,Relations Generator 推断关系边。这与 Zep/Graphiti 的方向一致。Alembic 的知识图谱模块还处于早期阶段,未来可以借鉴 Mem0ᵍ 的 Conflict Detector 和 Update Resolver 来增强图节点的自动维护。
上下文蒸馏 — 从学术概念到工程实践
"蒸馏"(Distillation)在 AI 领域有两个含义:
- 模型蒸馏(Knowledge Distillation)——大模型 → 小模型的知识迁移(Hinton et al., 2015)。如 DeepSeek-R1-Distill 从 R1 蒸馏推理能力到 Qwen/Llama 基座。
- 上下文蒸馏(Context Distillation)——长上下文 → 短摘要的信息压缩。这才是 Agent 记忆系统的核心操作。
Alembic 中有四处关键的上下文蒸馏点:
| 蒸馏点 | 输入 | 输出 | 压缩比 |
|---|---|---|---|
ActiveContext.distill() | 当前轮完整的工具调用 + 结果 | 精简的发现摘要 | ~10:1 |
SessionStore.getDistilledForProducer() | 多个维度的全部发现 | 当前维度 + 交叉引用摘要 | ~5:1 |
TierReflection | 一整个 tier 的维度分析结果 | 规则聚合的已完成维度 + TOP 发现 + 跨维度模式 | ~20:1 |
ContextWindow L2 蒸馏 | 旧轮次的完整消息 | 一句话摘要 | ~15:1 |
这些蒸馏点形成一条渐进压缩管线——信息从产生时的完整形态,经过多级蒸馏,最终以最精炼的形式注入下一个需要它的上下文。这与 Generative Agents 的"反思"(reflection)机制在目标上一致,但实现策略不同:
- Generative Agents 的反思:用 LLM 从 100 条观察中生成 5 条高级反思——输出是自然语言"洞察"。
- Alembic 的蒸馏:
distill()和TierReflection使用规则聚合(模板拼接 + 重要度排序),不调用 LLM。只有 ContextWindow L2 蒸馏才使用 LLM 生成摘要。
选择规则聚合而非 LLM 反思的原因是成本和确定性:Bootstrap 冷启动扫描 25 个维度 × 每个维度 24 轮 = 600 轮迭代,如果每次蒸馏都调 LLM,会增加数百次额外 API 调用。规则聚合的蒸馏结果不如 LLM 灵活,但零成本、零延迟、完全确定。
与前沿的差距与展望
| 前沿方向 | 对标系统 | Alembic 现状 | 可能的演进 |
|---|---|---|---|
| 图结构记忆 | Zep/Graphiti, Mem0ᵍ | knowledge-graph 仅 2 个工具(去重 + 加边) | 实时实体提取 + 关系推断,构建项目知识图谱 |
| 跨会话时序推理 | Zep(时序边) | PersistentMemory 只有 created_at / last_accessed | 为记忆添加时序边,支持"什么时候改了 X" |
| LLM 驱动的记忆整合 | Mem0 Update Phase(LLM 决策 ADD/UPDATE/DELETE) | MemoryConsolidator 使用规则 + 相似度阈值 | 引入 LLM 判断 MERGE 还是 ADD(高成本但更准确) |
| 自适应预算 | MemGPT(Agent 自主换页) | 三种固定 profile + surplus | 根据任务复杂度动态调整 profile 权重 |
| 多模态记忆 | 学术前沿 | 纯文本记忆 | 存储代码 AST 片段或架构图的结构化记忆 |
小结
工具体系和记忆系统是 Agent 的两个互补支柱:工具让 Agent 能与世界交互,记忆让 Agent 能从交互中学习。
工具层面,ToolRegistry 的注册协议 + Capability 白名单过滤解决了"60 个工具如何有序暴露"的问题。ToolExecutionPipeline 的 7 层中间件链解决了"安全、缓存、追踪如何横切执行"的问题。ToolForge 的三级瀑布(Reuse → Compose → Generate)解决了"预定义工具不够用怎么办"的问题。
记忆层面,三层架构(ActiveContext → SessionStore → PersistentMemory)覆盖了从秒级到月级的时间尺度。MemoryRetriever 的三维评分(recency × importance × relevance)确保最有价值的记忆被优先召回。MemoryConsolidator 的冲突消解和相似度整合确保记忆不会无限膨胀。MemoryCoordinator 的 token 预算分配确保三层记忆在有限的上下文窗口中合理共存。
ExplorationTracker 是连接工具和记忆的纽带——它用 SignalDetector 追踪每次工具调用产生的新信息,用 NudgeGenerator 在 Agent 迷失时提供方向引导,用阶段状态机控制 Agent 从"探索"到"生产"到"总结"的自然过渡。
下一章进入平台与交付层——知识从 Agent 的内部表示,到最终到达用户 IDE 的完整链路。
下一章