质量评分与维度框架
25 个维度量化知识质量,置信度路由决定发布路径。
问题场景
Agent 在一次冷启动中提交了 50 条候选知识。其中有一条关于 NetworkKit 的架构约束,内容完整、代码示例准确、引用了三个源文件;另一条只有标题和一行描述,没有 coreCode,reasoning.sources 为空;还有一条看起来不错,但置信度只有 0.15。
哪些该直接进入知识库?哪些需要人工审核?哪些应该直接丢弃?如果只靠人工逐条审阅,效率不可接受;如果全部自动通过,知识库质量无法保证。
但这不是唯一的问题。在提交这 50 条候选之前,Agent 是怎么知道要从项目中提取哪些方面的知识?一个 iOS 项目和一个 Spring Boot 项目,关注点显然不同——前者需要分析 SwiftUI 视图组合和 Combine 数据流,后者需要分析 Bean 管理和 AOP 切面。如果 Agent 靠通用提示词"找出项目中的最佳实践",你会得到一堆浮于表面的泛泛之谈。
这两个问题——分析什么和怎么评价——是知识质量保证的一体两面。
设计决策
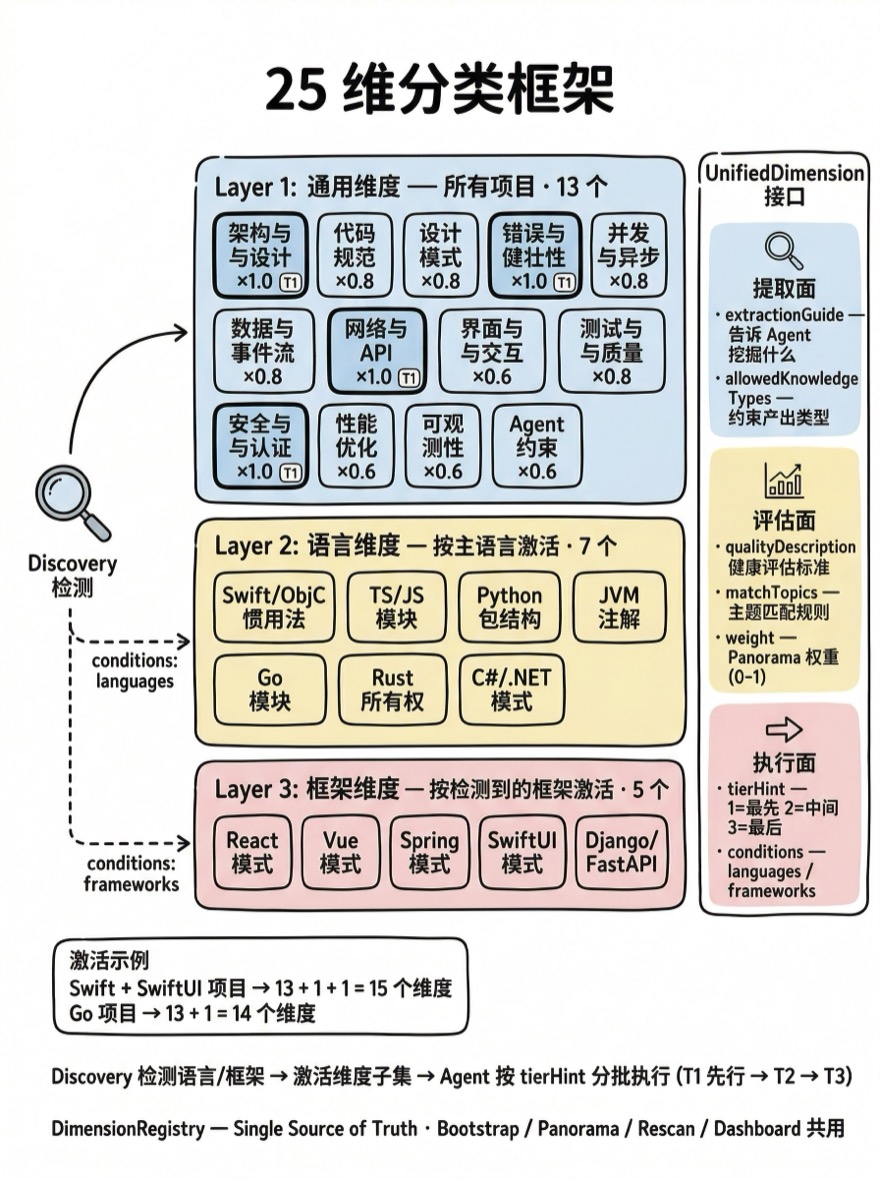
25 维分类框架
Alembic 的解法是:定义一套结构化的维度框架,用 25 个维度覆盖软件项目知识的所有方面。每个维度不是一个模糊的标签,而是一个完整的分析规格——包含提取指南、允许的知识类型、质量评估标准、主题匹配规则。
维度分为三个层级:
| 层级 | 数量 | 激活条件 | 含义 |
|---|---|---|---|
| Layer 1: Universal | 13 | 所有项目 | 任何软件项目都需要分析的通用维度 |
| Layer 2: Language | 7 | 按主语言激活 | 特定编程语言的惯用模式 |
| Layer 3: Framework | 5 | 按检测到的框架激活 | 特定框架的模式与约定 |
Layer 1 — 13 个通用维度
通用维度覆盖了软件工程的核心关注点。每个维度有明确的 extractionGuide 告诉 Agent 要提取什么:
| ID | 标签 | 提取指南 | 权重 |
|---|---|---|---|
architecture | 架构与设计 | 分层架构、模块职责与边界、依赖方向约束、路由表 | 1.0 |
coding-standards | 代码规范 | 命名约定、注释风格、文件组织、import 排序 | 0.8 |
design-patterns | 设计模式 | 单例/委托/工厂/Builder/观察者等模式、继承层级 | 0.8 |
error-resilience | 错误与健壮性 | 异常类型定义、错误传播、重试/回退/熔断、防御性编程 | 1.0 |
concurrency-async | 并发与异步 | 线程安全、async-await、RxSwift/Combine、锁模式 | 0.8 |
data-event-flow | 数据与事件流 | 持久化、缓存、序列化、状态管理、事件总线 | 0.8 |
networking-api | 网络与 API | API 模式、响应模型、重试策略、身份验证、拦截器 | 1.0 |
ui-interaction | 界面与交互 | 组件基类、布局约束、生命周期管理、导航 | 0.6 |
testing-quality | 测试与质量 | 单元测试、Mock 策略、集成测试、CI/CD | 0.8 |
security-auth | 安全与认证 | 认证流程、授权模型、加密方案、隐私 | 1.0 |
performance-optimization | 性能优化 | 内存管理、懒加载、缓存策略、渲染优化 | 0.6 |
observability-logging | 可观测性 | 日志框架、事件追踪、监控指标 | 0.6 |
agent-guidelines | Agent 约束 | AI Agent 行为约束、废弃 API 警告、自定义规则 | 0.6 |
weight 字段决定该维度在 Panorama 全景评估中的权重。architecture、error-resilience、networking-api、security-auth 权重为 1.0——这些维度的缺失对项目知识完整性的影响最大。
Layer 2 — 7 个语言维度
语言维度只在项目主语言匹配时激活。例如 swift-objc-idiom 只对 Swift/Objective-C 项目有效:
// lib/domain/dimension/DimensionRegistry.ts
const DL1_SWIFT_OBJC: UnifiedDimension = {
id: 'swift-objc-idiom',
label: 'Swift / ObjC 惯用法',
layer: 'language',
extractionGuide:
'常量定义方式、Sendable 合规、Method Swizzling、' +
'ObjC 桥接头文件约定、命名空间前缀...',
conditions: { languages: ['swift', 'objective-c'] },
tierHint: 2,
// ...
};七个语言维度覆盖了主流编程语言的特有关注点:
| ID | 覆盖语言 | 关注点 |
|---|---|---|
swift-objc-idiom | Swift / Objective-C | Sendable 合规、Method Swizzling、ObjC 桥接 |
ts-js-module | TypeScript / JavaScript | barrel exports、树摇动、路径别名、ESM 约定 |
python-structure | Python | __init__.py、type hints、装饰器、包结构 |
jvm-annotation | Java / Kotlin | DI 注解、ORM 映射、API 注解约定 |
go-module | Go | go.mod、internal 包、接口隐式实现 |
rust-ownership | Rust | 所有权转移、生命周期标注、unsafe 使用规范 |
csharp-dotnet | C# / .NET | DI 容器、LINQ、EF Core、Middleware 管道 |
Layer 3 — 5 个框架维度
框架维度通过 Discovery 机制自动检测。当项目中发现 package.json 含有 react 依赖,react-patterns 维度被激活:
| ID | 检测条件 | 关注点 |
|---|---|---|
react-patterns | React | 组件结构、状态管理、数据获取 |
vue-patterns | Vue | Composition API、Pinia、Nuxt 约定 |
spring-patterns | Spring | Bean 管理、AOP、配置管理 |
swiftui-patterns | SwiftUI | View 组合、状态属性包装器、导航 |
django-fastapi | Django / FastAPI | 路由、Model/Serializer、Middleware |
维度如何驱动分析
维度不只是标签——每个维度携带完整的分析元数据。DimensionRegistry 是整个系统的 Single Source of Truth,Bootstrap、Panorama、Rescan、Dashboard 均从这一个注册表消费维度定义:
// lib/domain/dimension/UnifiedDimension.ts
export interface UnifiedDimension {
readonly id: string; // 唯一 ID
readonly label: string; // 中文标签
readonly layer: 'universal' | 'language' | 'framework';
// 提取面
readonly extractionGuide: string; // Agent 从源码中挖掘什么
readonly allowedKnowledgeTypes: readonly string[]; // 允许的知识类型
// 评估面
readonly qualityDescription: string; // 健康评估标准
readonly matchTopics: readonly string[]; // 主题匹配规则
readonly weight: number; // Panorama 权重 (0-1)
// 执行面
readonly tierHint?: number; // 1=最先执行, 3=最后
readonly conditions?: { // 激活条件
readonly languages?: readonly string[];
readonly frameworks?: readonly string[];
};
}在 Bootstrap 冷启动中,系统先通过 Discovery 检测项目的语言和框架,然后激活对应的维度子集。Agent 按 tierHint 分批执行分析——architecture 和 security-auth(Tier 1)先行,因为后续维度的分析可能依赖架构和安全上下文。每个维度的 extractionGuide 直接注入 Agent 的提示词,指导它关注什么。一个 Swift + SwiftUI 项目会激活 13 + 1 + 1 = 15 个维度,而一个 Go 项目可能只激活 13 + 1 = 14 个。
维度的 allowedKnowledgeTypes 约束了该维度下可以产出什么类型的知识。architecture 维度允许 architecture、module-dependency、boundary-constraint,但不允许 code-style——这防止 Agent 在错误的维度下产出错误类型的知识。
QualityScorer 多维评分
维度框架解决了"分析什么"的问题。下一步是"怎么评价"——Agent 提交的候选知识质量如何?
传统做法是设置一组硬性阈值:标题不为空 → pass,coreCode 长度大于 20 行 → pass,否则 reject。这种二元判断有一个根本缺陷:一条标题完美但 coreCode 稍短的知识,和一条所有字段都勉强及格的知识,在二元系统中可能得到相同的 pass——但它们的实际质量差距很大。
QualityScorer v2 采用渐进式五维评分,灵感来自三个领域的实践:
- RAG Triad (TruLens):Relevance + Groundedness + Answer Relevance
- RAGAS 框架:Context Precision + Faithfulness + Factual Correctness
- SonarQube:多维度渐进评级,而非二元判断
五个维度及其权重:
// lib/shared/constants.ts
export const QUALITY_WEIGHTS = Object.freeze({
completeness: 0.25, // 结构完整性 — 核心字段齐全度
contentDepth: 0.30, // 内容深度 — markdown 丰富度、推理、溯源
deliveryReady: 0.20, // 交付就绪 — trigger/language/tags/category
actionability: 0.15, // 可操作性 — coreCode、do/dont/when 质量
provenance: 0.10, // 溯源可信 — confidence、sources、authority
});每个维度输出 0-1 的归一化分数,最终加权求和得到综合评分。
completeness(结构完整性 · 0.25)
逐字段检查核心字段的"充实程度"——不只是判断有无,而是渐进评分。textScore() 是核心辅助函数:
// lib/service/quality/QualityScorer.ts
function textScore(
text: string | undefined,
minLen: number,
optimalLen: number,
weight: number
) {
if (!text?.trim()) { return 0; }
const len = text.trim().length;
if (len < minLen) { return weight * 0.2; } // 有内容但太短 → 20% 基础分
if (len <= optimalLen) { return weight * (0.5 + 0.5 * (len / optimalLen)); }
return weight; // 超过最优长度 → 满分
}设计微妙之处在于 0.2 的基础分。一个字段只要有内容(哪怕很短),就不会得零分——这避免了"缺一个字段就崩溃"的脆弱性。textScore 从 20% 基线线性增长到 100%,minLen 是最低可接受长度,optimalLen 是满分长度。
completeness 的字段分配:
| 字段 | 权重 | minLen → optimalLen |
|---|---|---|
title | 0.15 | 3 → 40 字符 |
trigger | 0.15 | 存在即满分 |
description | 0.15 | 10 → 60 字符 |
doClause | 0.15 | 10 → 50 字符 |
whenClause | 0.15 | 10 → 50 字符 |
coreCode | 0.15 | 10 → 200 字符 |
dontClause | 0.10 | 存在即满分 |
dontClause 权重最低(0.10)且只做存在性检查——因为并非所有知识都自然有"不应该做什么",有些 fact 类型的知识天然没有反向约束。
contentDepth(内容深度 · 0.30)
这是权重最高的维度——因为 content.markdown 是知识的核心载体。评分不只看长度,还检查结构化标记:
#scoreContentDepth(r: RecipeInput) {
let s = 0;
const md = r.contentMarkdown || r.usageGuide || '';
s += textScore(md || undefined, 50, 800, 0.3);
// 结构化标记加分
if (md) {
if (/^#{1,4}\s/m.test(md)) { s += 0.08; } // 含标题
if (/```[\s\S]*?```|`[^`]+`/.test(md)) { s += 0.08; } // 含代码块
if (/^[\s]*[-*+]\s/m.test(md)) { s += 0.04; } // 含列表
}
s += textScore(r.contentRationale, 10, 100, 0.15);
s += textScore(r.reasoningWhyStandard, 10, 100, 0.15);
if (r.reasoningSources && r.reasoningSources.length > 0) {
s += Math.min(0.1, r.reasoningSources.length * 0.03);
}
// usageGuide 与 markdown 不同时,额外加分
if (r.usageGuide && r.usageGuide !== md) {
s += textScore(r.usageGuide, 20, 200, 0.1);
}
return Math.min(1, s);
}包含标题、代码块、列表三种结构化标记能获得最多 0.20 的加分。这不是随意的——一篇有结构的知识文档(分段标题 + 代码示例 + 要点列表)比一整段纯文本在实际使用中有用得多。
reasoningSources 的评分是 length × 0.03,上限 0.10。三个来源得 0.09 分,四个以上封顶。为什么不是线性到底?因为引用太多反而可能是"捞取"行为——Agent 可能把一个目录下所有文件都列为来源。三四个精准引用比十几个泛泛引用更有价值。
deliveryReady(交付就绪 · 0.20)
评估知识是否能被实际交付给 Cursor IDE。trigger 格式是否合法?language 是否在系统已知的语言列表中?
#scoreDeliveryReady(r: RecipeInput) {
let s = 0;
// trigger 格式:kebab-case, 长度 2-80
if (r.trigger) {
const valid = /^[a-zA-Z0-9_\-:.@]+$/.test(r.trigger)
&& r.trigger.length >= 2 && r.trigger.length <= 80;
s += valid ? 0.25 : r.trigger.length >= 2 ? 0.15 : 0;
}
// language 合法性
if (r.language) {
s += LanguageProfiles.validCodeLanguages.has(r.language.toLowerCase())
? 0.25 : 0.1;
}
s += presenceScore(r.category, 0.2);
if (r.tags && r.tags.length > 0) { s += Math.min(0.15, r.tags.length * 0.04); }
if (r.headers && r.headers.length > 0) { s += Math.min(0.15, r.headers.length * 0.05); }
return Math.min(1, s);
}注意对于 trigger,即使格式不完全合法(缺少 @ 前缀或含有不允许的字符),只要长度达标就能拿到 0.15 分而非零分。这是"渐进式"的核心理念——不因一个小问题全盘否定。
actionability(可操作性 · 0.15)
能否让 AI Agent 基于这条知识有效地生成代码?coreCode 的质量是关键:
#scoreActionability(r: RecipeInput) {
let s = 0;
// 代码示例质量:30-500 字符为最佳区间
const codeLen = (r.coreCode || '').trim().length;
if (codeLen >= 30 && codeLen <= 500) { s += 0.3; }
else if (codeLen >= 10) { s += 0.2; }
else if (/```[\s\S]{10,}?```/.test(md)) { s += 0.2; } // markdown 中的代码块兜底
// doClause 具体度:15-200 字符为最佳
if (r.doClause) {
const len = r.doClause.trim().length;
s += (len >= 15 && len <= 200) ? 0.25 : len >= 5 ? 0.1 : 0;
}
// 正反约束成对:do + don't → 指导更精确
if (r.doClause?.trim() && r.dontClause?.trim()) { s += 0.2; }
// whenClause 触发场景
if (r.whenClause) {
s += r.whenClause.trim().length >= 15 ? 0.25 : 0.1;
}
return Math.min(1, s);
}coreCode 的最佳区间是 30-500 字符。低于 30 字符的代码片段通常不完整——可能只有一行声明;超过 500 字符的代码块则失去了"骨架"的意义,变成了完整的实现代码。知识引擎需要的是可复制的模式骨架,不是完整的源文件。
do + don't 成对出现能拿到 0.20 的额外分数——这对 AI 来说意义重大。"使用 async/await 处理异步操作" + "不要使用裸回调嵌套" 的组合,比单独一条 doClause 提供了更精确的行为边界。
provenance(溯源可信 · 0.10)
权重最低的维度——但它在自动审批流程中起着关键作用:
#scoreProvenance(r: RecipeInput) {
let s = 0;
// 置信度直接转化
s += Math.min(0.30, (r.reasoningConfidence || 0) * 0.30);
// 来源文件数量
s += Math.min(0.30, (r.reasoningSources?.length || 0) * 0.10);
// 来源类型加权:manual > mcp > bootstrap
const sourceType = r.source || 'unknown';
if (sourceType === 'manual') { s += 0.20; }
else if (sourceType === 'mcp') { s += 0.15; }
else if (sourceType === 'bootstrap') { s += 0.10; }
// 用户评分/使用权威
if (r.rating && r.rating > 0) {
s += (r.rating / 5) * 0.20;
}
return Math.min(1, s);
}人工创建的知识(source: 'manual')比 Bootstrap 自动生成的知识获得更高的溯源分数——这符合直觉:人类审阅过的内容天然比 AI 自动提取的更可信。但差距不大(0.20 vs 0.10),因为 Alembic 的设计目标是让 Agent 产出的知识质量接近人工水平,而非永远被打折。
评分等级
综合分数通过等级表映射为 A-F 评级:
| 等级 | 阈值 | 含义 |
|---|---|---|
| A | ≥ 0.85 | 优秀,可直接交付 |
| B | ≥ 0.70 | 良好,小改即可 |
| C | ≥ 0.55 | 合格,需要补充 |
| D | ≥ 0.35 | 不合格,需大幅改进 |
| F | < 0.35 | 极差,建议重写 |
架构与数据流
置信度推理链
质量分评价的是知识条目本身的"长相"——字段完不完整?内容深不深?但还有另一个同样重要的维度:这条知识有多大把握是正确的?这就是 reasoning(推理链)要解决的问题。
每条 KnowledgeEntry 都携带一个 reasoning 值对象,包含三个核心字段:
| 字段 | 含义 | 构建方式 |
|---|---|---|
whyStandard | 为什么这是标准做法 | Agent 从代码证据推导的论证文本 |
sources | 证据来源文件列表 | Agent 分析过程中收集的文件路径(非空) |
confidence | 置信度 (0-1) | Agent 综合多信号给出的确信程度 |
whyStandard 不是一句"因为大家都这么做"——它需要包含具体的项目证据。例如:"在 23 个 ViewController 中,21 个通过 Coordinator 进行页面跳转而非直接 push,两个例外存在于 Legacy/ 目录下的旧代码中。" 这种基于统计的论证比泛泛的"这是最佳实践"有力得多。
sources 必须非空——这是 FieldSpec 的硬性约束。Agent 不能声称一条知识是从代码中提取的,却不指出具体来自哪些文件。这些文件路径是 SourceRefReconciler(上一章讲过)持续追踪的对象。
confidence 的影响范围远超评分系统:
- 搜索排序:高置信度知识在搜索结果中排名更高(通过交付排名公式
confidence × 50权重) - Guard 执行:高置信度规则产生的 violation 更严格(不降级为 warning)
- 发布路由:高置信度候选可以自动晋升到
staging(由 ConfidenceRouter 决定) - 衰退检测:高置信度知识更不容易被判定为衰退
ConfidenceRouter
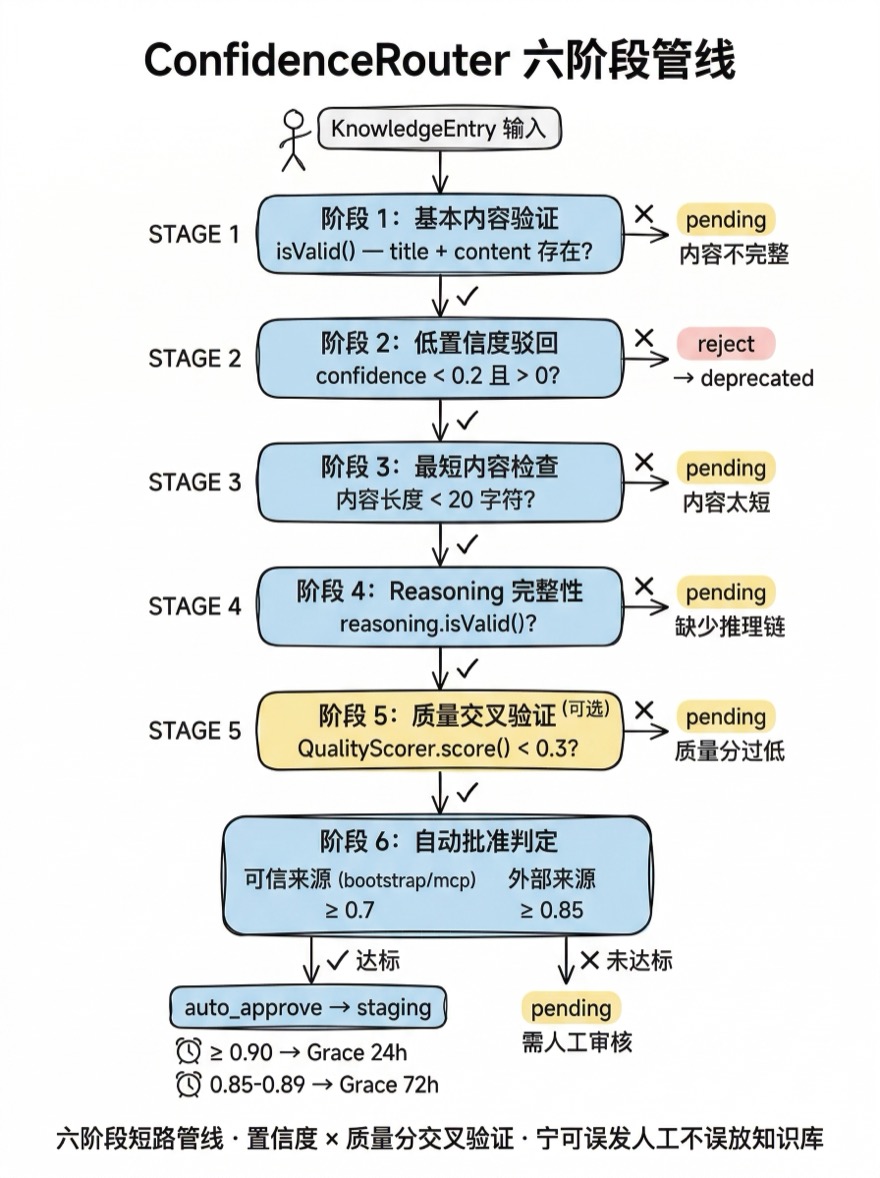
ConfidenceRouter 是质量评分和生命周期状态机之间的桥梁。它根据置信度、质量分、内容完整性等信号,自动决定每条候选知识的发布路径。
路由结果只有三种:
// lib/service/knowledge/ConfidenceRouter.ts
interface RouteResult {
action: 'auto_approve' | 'pending' | 'reject';
reason: string;
confidence?: number;
targetState?: 'staging' | 'pending' | 'deprecated';
gracePeriod?: number; // staging → active 的等待时间(毫秒)
}决策通过六个阶段的管线完成,每个阶段可以"短路"返回:
阶段 1:基本内容验证
if (!entry.isValid()) {
return { action: 'pending', reason: 'Content incomplete' };
}isValid() 检查 title 和 content 是否存在——这是最低门槛,缺一不可。
阶段 2:低置信度驳回
if (confidence < this._config.rejectThreshold && confidence > 0) {
return {
action: 'reject',
reason: `Confidence too low: ${confidence} < 0.2`,
targetState: 'deprecated',
};
}注意 confidence > 0 这个条件。如果 Agent 没有提供置信度(默认为 0),系统不会驳回——而是放到后续阶段继续评估。只有当 Agent 明确表示置信度低于 0.2 时,才会直接标记为废弃。
阶段 3:最短内容检查
内容总长度低于 20 字符 → pending。这防止了空壳候选进入自动审批流程。
阶段 4:Reasoning 完整性检查
如果配置了 requireReasoning: true(默认),reasoning.isValid() 必须通过。isValid() 检查 whyStandard 和 sources 是否非空。缺少推理链不会被驳回,而是进入 pending 等人工审核——这是一个务实的选择,因为部分合法的知识确实难以自动构建推理链。
阶段 5:质量评分交叉验证(可选)
如果系统中有 QualityScorer 实例可用,ConfidenceRouter 会调用它进行交叉验证:
if (this._qualityScorer) {
const result = this._qualityScorer.score(scorerInput);
qualityScore = result.score;
}即使置信度达标,如果质量分低于 0.3,也会被降级到 pending。这防止了一种特殊情况:Agent 对自己的输出给出了很高的 confidence,但实际内容质量很差。置信度是 Agent 的自我评估,质量分是系统的客观测量——两者交叉验证提供了更可靠的判断。
阶段 6:自动批准判定
到了这一步,内容完整、推理链健全、质量分及格。现在只需要判断置信度是否达标:
const threshold = isTrusted
? this._config.trustedAutoApproveThreshold // 0.7
: this._config.autoApproveThreshold; // 0.85
if (confidence >= threshold) {
const gracePeriod = confidence >= 0.9
? 24 * 60 * 60 * 1000 // 极高置信度 → 24 小时 Grace
: 72 * 60 * 60 * 1000; // 标准 → 72 小时 Grace
return {
action: 'auto_approve',
targetState: 'staging',
gracePeriod,
};
}两个关键设计:
可信来源差异化阈值。Bootstrap、Cursor 扫描、MCP 工具提交的候选使用 0.7 的阈值(而非 0.85)。理由是这些来源经过了系统内部的多层质量把控——Bootstrap 有 UnifiedValidator 前置验证,MCP 工具有 FieldSpec 约束。外部手动提交则需要更高的置信度门槛。
分级 Grace Period。自动批准不是直接进入 active,而是进入 staging 状态;staging 多久后自动晋升为 active,取决于置信度等级。置信度 ≥ 0.90 的候选只需等待 24 小时(极高置信度意味着更小的错误风险),0.85-0.89 的候选需要 72 小时。在 Grace Period 内,如果出现负面反馈(用户打回、Guard 误报率上升),晋升会被中止。
未达标的候选进入 pending 状态等待人工审核。ConfidenceRouter 的设计保证了"宁可误发到人工审核,不要误放到知识库"——这是一个有明确偏向的决策。
以下是完整的路由决策流的可视化:
| 置信度 | 来源 | 质量分 | 结果 | Grace Period |
|---|---|---|---|---|
| ≥ 0.90 | 任意 | ≥ 0.3 | 自动批准 → staging | 24h |
| 0.85-0.89 | 非可信 | ≥ 0.3 | 自动批准 → staging | 72h |
| 0.70-0.84 | 可信来源 | ≥ 0.3 | 自动批准 → staging | 72h |
| ≥ 0.85 | 任意 | < 0.3 | 降级 → pending | — |
| 0.20-0.84 | 非可信 | 任意 | pending(需人工) | — |
| 0.01-0.19 | 任意 | 任意 | 驳回 → deprecated | — |
| 0 | 任意 | 任意 | 继续评估(无置信度视为未知) | — |
核心实现
反馈循环
质量评分不是一次性计算——它是一个闭环。知识被创建、评分、发布后,真实的使用数据会回流到评分系统,持续修正质量判断。
信号系统(SignalBus)是这个闭环的基础设施。所有模块通过统一的信号总线通信:
// lib/infrastructure/signal/SignalBus.ts
export type SignalType =
| 'guard' // Guard 引擎命中
| 'search' // 搜索结果使用
| 'usage' // 查看、采纳、应用
| 'lifecycle' // 状态转换
| 'quality' // 质量评估
| 'decay' // 知识衰退
| 'anomaly' // 异常检测
// ... 共 12 种信号类型
interface Signal {
type: SignalType;
source: string; // 发射模块
target: string | null; // 目标 Recipe ID
value: number; // 0-1 归一化值
metadata: Record<string, unknown>; // 载荷
timestamp: number;
}SignalBus 的三条设计公理:同步分发(每次 emit < 0.1ms)、消费者异常隔离(一个订阅者崩溃不影响其他)、无队列缓冲(信号即时发射)。
在信号总线之上,HitRecorder 负责高频使用事件的批量采集:
// lib/service/signal/HitRecorder.ts
type HitEventType = 'guardHit' | 'searchHit' | 'view' | 'adoption' | 'application';每次 Guard 检查命中一条 Recipe 的规则(guardHit)或搜索结果返回一条 Recipe(searchHit),HitRecorder 做两件事:
- 即时发射信号:通过 SignalBus 通知所有订阅者(DecayDetector 会监听,用于实时恢复
decaying状态的 Recipe) - 缓冲批量写入:累积在内存缓冲区中,当缓冲区达到 100 条或每隔 30 秒,批量 flush 到数据库
持久化使用 SQLite 的 json_set() 原子操作,避免读取-修改-写回的竞态:
UPDATE knowledge_entries
SET stats = json_set(
COALESCE(stats, '{}'),
'$.guardHits',
COALESCE(json_extract(stats, '$.guardHits'), 0) + 1
),
updatedAt = ?
WHERE id = ?反馈闭环的完整路径:
用户操作 → Guard/Search 命中 → HitRecorder 记录 → SignalBus 发射
↓
DecayDetector 实时监听 ← KnowledgeMetabolism ← 30s 批量 flush → DB stats 更新
↓
QualityScorer 下次评分时读取 engagement 数据在 QualityScorer 的 provenance 维度中,rating 字段来自用户的直接评分;在 DecayDetector 的四维公式中,usage 维度来自 stats.adoptions + stats.applications + stats.guardHits 的累计值。这形成了两条反馈链路:
- 短回路:使用信号 → DecayDetector → 状态恢复/衰退(实时)
- 长回路:使用统计 → QualityScorer engagement → 质量等级变化 → 交付排名变化(跟随评分更新周期)
FeedbackCollector 补充了用户交互层面的反馈——Dashboard 上的浏览(view)、点击(click)、复制(copy)、插入(insert)、评分(rate)事件。这些数据持久化在 .asd/feedback.json 中(Git 友好),通过 getTopRecipes(n) 提供 Top-K 排名供 Dashboard 展示。
StyleGuide:项目特写的写作规范
知识质量的另一个重要维度不在评分公式里——它在评分之前,决定了 Agent 怎么写一条知识。StyleGuide 模块定义了"项目特写"(Project Snapshot)的写作规范,这是 content.markdown 字段的内容标准。
一条高质量的 content.markdown 不是技术文档的复制粘贴,也不是纯代码罗列。它是一种特殊的文体——将一种技术的基本用法与项目的具体特征融合为一体:
// lib/domain/knowledge/StyleGuide.ts
export const PROJECT_SNAPSHOT_STYLE_GUIDE = `
## 四大核心内容
1. **项目选择了什么** — 采用了哪种写法/模式/约定
2. **为什么这样选** — 统计分布、占比、历史决策
3. **项目禁止什么** — 反模式、已废弃写法
4. **新代码怎么写** — 可直接复制使用的代码模板 + 来源标注
`;四大核心内容的设计来自一个朴素的观察:大多数知识库条目要么太抽象("使用 Repository 模式"),要么太具体(一整个文件的代码)。项目特写要求 Agent 在"选了什么 → 为什么选 → 禁止什么 → 怎么写"的框架中组织信息,确保每条知识都是可操作的。
写作规约中几条关键约束:
- 标题使用项目真实类名——"NetworkKit 请求封装规范"而非"网络请求模式"
- 代码来源标注——
(来源: CookieProviding.swift:42)而非无出处的代码块 - 不要纯代码罗列——必须有项目上下文的文字说明
- 标题和正文中不得出现 "Agent" 字样——知识是给人和 AI 共同消费的,不应暴露生产过程
StyleGuide 不只是文档——它被 buildProducerStyleGuide() 编译为 Agent 提示词的一部分,在 Bootstrap 和 MCP 提交流程中强制注入。Agent 每次生成候选知识时,都带着这份写作指南工作。随后 UnifiedValidator 在验证阶段检查内容是否符合这些约束——不含代码块的 markdown 会被标记为 warning,标题含"Agent"字样会被拒绝。
StyleGuide 与 QualityScorer 形成了"前后夹击":前者约束 Agent 的生产行为,后者评估生产结果。
权衡与替代方案
为什么不用 LLM 评分?
一个自然的替代方案是让 LLM 直接给候选知识打分——毕竟 LLM 可以理解语义,判断内容是否合理。Alembic 选择了纯工程评分(正则 + 字段检查 + 统计公式),原因有三:
可复现性。同一条知识用 QualityScorer 评分,任何时候、任何环境都会得到完全相同的结果。LLM 的输出是概率性的——同一段内容在不同调用中可能被判为 70 分或 85 分。对于自动审批这样的关键决策,不可复现的评分是不可接受的。
成本与延迟。QualityScorer 评一条知识用时 < 1ms。LLM 评分需要一次 API 调用(100-500ms + 网络延迟 + Token 成本)。在 Bootstrap 冷启动中可能有数百条候选需要评分,LLM 方案的成本会快速累积。
SOUL 原则对齐。"AI 编译期 + 工程运行期"原则要求运行期的核心逻辑不依赖 AI。评分是运行期的关键路径(搜索排序、Guard 权重、发布决策都依赖它),必须用确定性逻辑实现。LLM 的角色在"编译期"——它负责生产知识,不负责评判知识。
为什么 25 维分类而非更简单的方案?
一个精简方案是只定义 5 个维度(架构、代码、测试、安全、性能),然后让 Agent 自由发挥。这在小项目上可能工作良好,但在大项目上会出现两个问题:
- 分析盲区。Agent 倾向于关注它最容易识别的模式(比如设计模式、命名约定),而忽略更微妙的维度(比如可观测性、并发模型)。25 维框架强制 Agent 逐维扫描,确保不遗漏。
- 维度间的精度丧失。把"错误处理"和"安全认证"合并为一个"防御性编程"维度,Agent 可能只在其中之一深入分析。细粒度维度指导 Agent 在每个方向上都做出具体的提取。
25 这个数字也不是越多越好——每增加一个维度,就增加了 Agent 的一次分析循环和系统的一个配置项。在 Bootstrap 中,25 个维度按 tierHint 分为三批执行(Tier 1 → 2 → 3),每批并行。如果维度增加到 50 个,并行度的边际收益会被 Token 预算和超时限制抵消。
已知局限
评分系统有一个结构性弱点:冷启动缺乏使用信号。在项目刚完成 Bootstrap 时,所有 Recipe 的 stats 都是零——provenance 维度中的 rating 和 engagement 无法提供有效信号,DecayDetector 的 usage 和 freshness 维度也没有数据。
这意味着在冷启动初期,质量评估几乎完全依赖内容本身(completeness + contentDepth + deliveryReady + actionability)。provenance 维度的权重只有 0.10,所以这不会严重扭曲整体评分,但确实意味着早期的知识排名主要反映"写得好不好",而非"用起来好不好"。
随着使用信号的积累(通常在项目中使用 Alembic 1-2 周后),反馈循环开始生效,评分逐渐从"内容质量"向"实际价值"演化。这是一个有意的设计——知识引擎不应该在缺乏证据时假装知道答案。
小结
质量保证体系的三个核心组件形成了一个闭环:
- 25 维分类框架回答"分析什么"——按语言和框架自适应激活维度,确保覆盖不遗漏
- QualityScorer 五维评分回答"多好"——渐进式评价替代二元判断,容忍局部缺陷
- ConfidenceRouter回答"怎么办"——六阶段管线将评分结果映射为发布路径
这三个组件共享一个设计基调:偏向保守。不确定的知识进入人工审核而非自动发布,低质量的知识降级而非丢弃,缺乏证据时承认无知而非猜测。在知识引擎中,一条错误的规则比十条缺失的规则造成更大的伤害——因为错误规则会主动污染 AI 的输出。
Part III 到此结束。从 KnowledgeEntry 统一实体、六态生命周期 到本章的质量评分框架,我们已经看完了知识领域的全部建模。接下来 Part IV 将展示这些知识如何被生产(Bootstrap)、如何被审查(Guard)、如何被检索(Search)、如何自我治理(Metabolism)。