Guard — 四层合规检测引擎
不是静态 lint,而是一个四层检测 + 三态输出的项目免疫系统。
问题场景
知识库里有一条 Recipe:“所有网络请求必须设置 30 秒超时”。Agent 按照这条 Recipe 生成了一段网络请求代码。谁来检查这段代码是否真的设置了超时?(Recipe 的质量如何保证,见 ch08 质量评分)
传统的 lint 工具可以做正则匹配——搜索 timeout 关键字是否出现。但"设置超时"在不同语言中有完全不同的表达:Swift 是 timeoutInterval: 30,Go 是 WithTimeout(30 * time.Second),JavaScript 是 AbortSignal.timeout(30000)。同一条 Recipe,同一个语义约束,代码实现千差万别。
更复杂的情况是:一条 Recipe 说"所有 ViewController 必须在 deinit 中移除通知观察者"。这不是一个单行正则能检查的——需要先确认类继承自 UIViewController,再检查 deinit 方法是否存在,最后验证其中是否包含 removeObserver 调用。这跨越了继承关系、方法存在性、调用链三个层次。
还有更棘手的情况:Guard 检查一个文件时发现了 import ModuleA,而另一个文件有 import ModuleB,而 ModuleB 又 import 了 ModuleA。这是一个循环依赖——单文件分析永远发现不了。
三个场景,三种检测深度。这就是 Guard 需要四层检测架构的原因。
设计决策
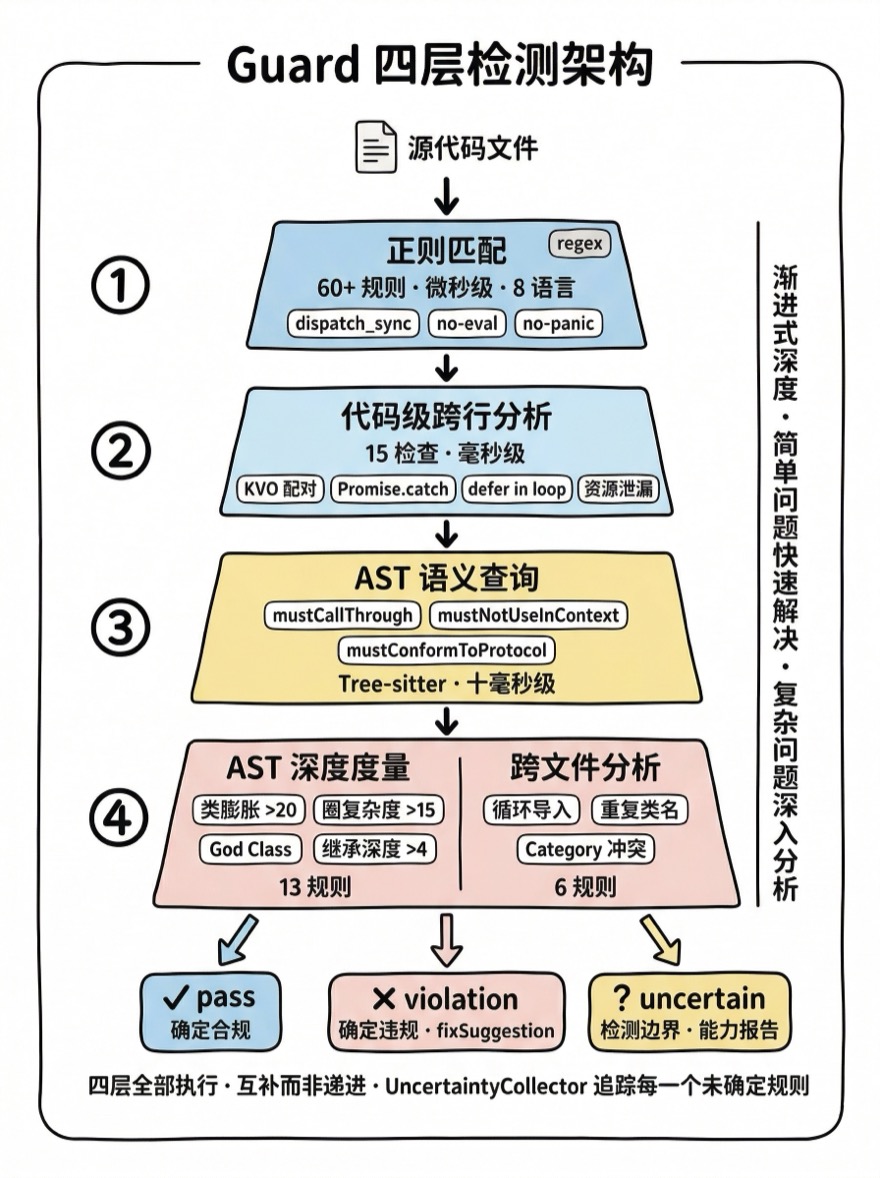
四层检测架构
Guard 的检测架构是渐进式加深的:每一层比上一层检测能力更强,但成本也更高。
| 层 | 名称 | 检测能力 | 速度 | 规则数 |
|---|---|---|---|---|
| Layer 1 | 正则匹配 | 单行模式:命名规范、禁止 API | 微秒级 | 45 |
| Layer 2 | 代码级分析 | 跨行上下文:配对检查、资源清理 | 毫秒级 | 14 |
| Layer 3 | AST 语义 | 结构查询:继承关系、协议遵守、方法签名 | 十毫秒级 | 3 类查询 |
| Layer 4 | AST 深度 + 跨文件 | 度量分析 + 循环依赖、重复类名 | 百毫秒级 | 13 + 6 |
这种分层设计的核心思想是快速短路:大多数代码可以在 Layer 1 就完成检测——正则匹配 dispatch_sync.*main 比解析整个 AST 快三个数量级。只有正则无法覆盖的复杂模式才需要升级到更深层次。
Layer 1 — 正则匹配
最快的一层。45 条内置规则覆盖 9 种语言的常见安全和风格问题:
// lib/service/guard/GuardCheckEngine.ts
// Swift: 禁止主线程同步调用
{ id: 'swift-no-main-thread-sync',
pattern: 'dispatch_sync\\s*\\(\\s*dispatch_get_main_queue',
severity: 'error',
message: '禁止 dispatch_sync(dispatch_get_main_queue()) — 会导致死锁' }
// Go: 禁止忽略 error 返回值
{ id: 'go-no-err-ignored',
pattern: '\\b\\w+,\\s*_\\s*:?=\\s*\\w+\\(',
severity: 'warning',
message: '不要忽略 error 返回值' }规则模式是标准正则表达式,编译后缓存在 _regexCache 中避免重复编译。检测前会对源码做注释遮蔽(buildCommentMask)——把所有注释内容替换为空白字符,只对有效代码做模式匹配。这避免了"注释中的示例代码触发误报"的经典问题。
Layer 2 — 代码级跨行分析
有些检查需要看连续多行的上下文。GuardCodeChecks.ts 提供 15 个语言特定的跨行检查:
| 语言 | 检查 | 检测逻辑 |
|---|---|---|
| ObjC | KVO 观察者配对 | addObserver 必须有对应的 removeObserver |
| Swift | 过量强制解包 | 单文件中 ! 使用超过 5 次(阈值可配) |
| JS/TS | Promise 未处理 | .then() 链缺少 .catch() |
| Java | 资源泄漏 | new FileInputStream 不在 try-with-resources 中 |
| Kotlin | UI 线程阻塞 | runBlocking 出现在非 suspend 函数中 |
| Go | defer in loop | defer 出现在 for 循环体内 |
| Rust | 库代码 panic | unwrap() / expect() / panic!() 出现在非 test 文件 |
// lib/service/guard/GuardCodeChecks.ts
// Swift: 过量强制解包检测
function checkSwiftExcessiveForceUnwrap(
lines: string[], threshold: number
): CodeLevelViolation[] {
let count = 0;
for (const line of lines) {
// 排除注释行和 guard/if let 解包
if (isCommentLine(line)) { continue; }
const matches = line.match(/[^!]=![^=]/g); // 匹配 ! 但排除 != 和 ==
count += matches?.length || 0;
}
if (count > threshold) {
return [{ ruleId: 'swift-excessive-force-unwrap',
message: `Force unwrap (!) used ${count} times, exceeds threshold ${threshold}` }];
}
return [];
}阈值通过配置文件定义,项目级可覆盖:
// config/default.json → guard.codeLevelThresholds
{
"swift-excessive-force-unwrap": 5,
"ast_class_bloat": 20,
"ast_method_complexity": 15,
"ast_method_too_long": 80,
"ast_deep_nesting": 5
}Layer 3 — AST 语义查询
当检测需要理解代码结构而非文本模式时,Guard 调用 Tree-sitter 解析语法树。AST 层支持三种查询类型:
| 查询类型 | 语义 | 示例 |
|---|---|---|
mustCallThrough | 方法必须调用指定的父类方法 | viewDidLoad 必须调用 super.viewDidLoad() |
mustNotUseInContext | 特定上下文中禁止使用某 API | async 函数中禁止使用 std::sync::Mutex |
mustConformToProtocol | 类必须实现协议的所有必选方法 | UITableViewDataSource 必须实现 numberOfRows |
这些查询不是简单的文本搜索——mustCallThrough 需要遍历方法的 AST 节点找到 super.xxx() 调用;mustConformToProtocol 需要交叉检查协议声明和类实现。这是正则永远做不到的。
Layer 4 — AST 深度度量 + 跨文件
最深的一层包含两个子系统:
度量分析(13 条深度规则):基于对整个文件的 AST 分析,计算结构度量值:
| 度量 | 阈值 | 含义 |
|---|---|---|
| 类方法数 | > 20 | 类膨胀(God Object 前兆) |
| 圈复杂度 | > 15 | 方法过于复杂 |
| 方法行数 | > 80 | 方法过长 |
| 嵌套深度 | > 5 | 逻辑层次太深 |
| 继承深度 | > 4 | 继承链过长 |
| 协议遵守数 | > 5 | 类职责过宽 |
| God Class | > 30 方法 + > 15 属性 | 上帝类 |
跨文件分析(GuardCrossFileChecks.ts):需要同时看到多个文件才能发现的问题:
// 循环导入检测
// A.ts: import { foo } from './B'
// B.ts: import { bar } from './A'
function checkCircularImports(
files: { path: string; content: string }[]
): CrossFileViolation[] {
const importGraph = new Map<string, Set<string>>();
for (const f of files) {
const imports = extractImports(f.content);
importGraph.set(normalize(f.path), new Set(imports.map(normalize)));
}
// 检测双向边
for (const [from, deps] of importGraph) {
for (const to of deps) {
if (importGraph.get(to)?.has(from)) {
violations.push({ ruleId: 'js-circular-import',
message: `Circular import: ${from} ↔ ${to}` });
}
}
}
}六种跨文件检查覆盖不同语言的典型问题:ObjC Category 重复声明、JS 循环导入、Java 重复类名、Go 多个 init()、Swift Extension 方法冲突。
三态输出
Guard 的检查结果不是简单的"通过/不通过",而是三态:
| 状态 | 含义 | 后续动作 |
|---|---|---|
| pass | 确定合规 | 无需操作 |
| violation | 确定违规 | Agent 修复或人工处理 |
| uncertain | 检测能力不足,无法判定 | 记录到 UncertaintyCollector |
uncertain 的存在源于一个务实的认知:Guard 不是全知的。当 Tree-sitter 不支持某种语言、当跨文件检查缺少依赖文件、当正则模式编译失败——Guard 无法对这些规则给出确定性结论。
传统做法是:跳过这些检查,默认"通过"。但这会制造虚假的安全感——"Guard 说没问题"实际上是"Guard 根本没检查"。
uncertain 状态诚实地暴露了检测边界。UncertaintyCollector 追踪每一个未确定的规则,记录跳过的层次和原因:
// lib/service/guard/UncertaintyCollector.ts
type SkipReason =
| 'invalid_regex' // 正则编译失败
| 'lang_unsupported' // 语言不支持
| 'ast_unavailable' // Tree-sitter 缺失
| 'file_missing' // 跨文件检查缺少依赖
| 'layer_conflict'; // 不同层结果矛盾
type CapabilityBoundary =
| 'ast_language_gap' // AST 不支持此语言
| 'cross_file_incomplete' // 缺少文件上下文
| 'rule_regex_invalid' // 无效正则模式
| 'scope_unchecked' // 作用域超出检测范围
| 'transitive_cycle'; // 传递性循环依赖最终输出的 GuardCapabilityReport 把这些不确定性汇总为一张"检测能力报告":
interface GuardCapabilityReport {
executedChecks: {
regex: { total: number; executed: number; skipped: number };
codeLevel: { total: number; executed: number; skipped: number };
ast: { total: number; executed: number; skipped: number };
crossFile: { total: number; executed: number; skipped: number };
};
boundaries: CapabilityBoundary[];
uncertainResults: UncertainResult[];
checkCoverage: number; // 0–100,实际执行的检查占总规则的百分比
}checkCoverage 是一个关键指标。如果一次审计的 coverage 只有 40%,意味着 60% 的规则因为能力边界未被执行——报告的"0 违规"不代表代码合规,只代表"在能力范围内未发现违规"。这个区分对于冷启动后的首次审计尤为重要。
规则体系
三源合并
Guard 的规则不是写死的——它们来自三个源头,按优先级合并:
Database Rules (知识库产出) ← 最高优先级
Enhancement Pack Rules (框架增强) ← 中等优先级
Built-in Rules (内置) ← 兜底
Disabled Rules (用户关闭) ← 过滤排除Database Rules:由知识库中 kind='rule' + knowledgeType='boundary-constraint' 的 KnowledgeEntry 转化而来。当 Agent 在冷启动或手动分析中发现了项目特定的编码约束,它会创建一条 rule 类型的 Recipe——这条 Recipe 自动成为 Guard 规则。
// 从 KnowledgeEntry 构建规则
{
id: entry.id,
pattern: entry.constraints?.guards?.[0]?.pattern, // 正则模式
message: entry.description,
severity: entry.constraints?.guards?.[0]?.severity || 'warning',
type: entry.constraints?.guards?.[0]?.type || 'regex',
astQuery: entry.constraints?.guards?.[0]?.astQuery, // AST 查询
fixSuggestion: entry.doClause, // Recipe 的 doClause 作为修复建议
languages: [entry.language],
}Enhancement Pack Rules:框架增强包(如 SwiftUI Pack、React Pack)自带的专项规则。pack.getGuardRules() 在引擎初始化时注入。
Built-in Rules:45 条内置规则,按语言组织:
| 语言 | 规则数 | 典型规则 |
|---|---|---|
| ObjC/Swift | 9 | no-main-thread-sync, force-cast, block-retain-cycle, timer-retain-cycle |
| JS/TS | 6 | no-eval, no-var, no-console-log, no-debugger |
| Python | 5 | no-bare-except, no-exec, no-mutable-default, no-star-import |
| Java/Kotlin | 5 | no-system-exit, no-raw-type, no-force-unwrap |
| Go | 4 | no-panic, no-err-ignored, no-init-abuse |
| Dart | 8 | no-print, avoid-dynamic, dispose-controller, no-build-context-across-async |
| Rust | 8 | no-unwrap, unsafe-block, clone-overuse, std-mutex-in-async |
Disabled Rules:用户可以通过配置文件关闭特定规则:
// .asd/config.json
{ "guard": { "disabledRules": ["swift-no-console-log", "go-no-err-ignored"] } }合并后的规则集在每次检查时加载。Database Rules 优先级最高——如果知识库中有一条与 Built-in 同 ID 的规则,知识库版本覆盖内置版本。这允许项目在使用过程中渐进式替换内置规则为更精确的项目特定版本。
规则输出格式
每条 violation 携带完整的诊断信息:
interface GuardViolation {
ruleId: string; // 'swift-no-main-thread-sync'
message: string; // '禁止 dispatch_sync(main_queue)'
severity: 'error' | 'warning' | 'info';
line: number;
snippet: string; // 违规代码片段
dimension?: string; // 关联的知识维度
fixSuggestion?: string; // 修复建议(来自 Recipe.doClause)
reasoning?: {
whatViolated: string; // 违反了什么
whyItMatters: string; // 为什么重要
suggestedFix: string; // 建议的修复方式
};
}fixSuggestion 不是空泛的"请修复"——它直接来自关联 Recipe 的 doClause 和 coreCode,是具体的、可执行的修复指南。Agent 收到 violation 时可以直接阅读 fixSuggestion 作为修复依据。
GuardCheckEngine 执行流
GuardCheckEngine 是整个检测系统的核心引擎。一次完整的文件审计经过以下步骤:
输入: { code, language, filePath }
│
├─── 1. 规则加载 ────→ getRules(language)
│ 合并三个来源,过滤 disabled
│
├─── 2. Layer 1: 正则匹配 ────→ compilePattern() + test()
│ 注释遮蔽 → 逐规则匹配 → violations[]
│
├─── 3. Layer 2: 代码级 ────→ runCodeLevelChecks()
│ 14 个语言特定检查器 → violations[]
│
├─── 4. Layer 3: AST 语义 ────→ _runAstRuleChecks()
│ 3 种查询类型 → violations[]
│
├─── 5. Layer 4: AST 深度 ────→ _runAstLayer2Checks()
│ 13 个度量规则 → violations[]
│
├─── 6. 跨文件(可选)────→ runCrossFileChecks()
│ 6 种跨文件规则 → violations[]
│
├─── 7. 不确定性收集 ────→ UncertaintyCollector.buildReport()
│
└─── 输出: { violations[], capabilityReport }四层检查是全部执行的——不是"Layer 1 通过就跳过后续层"。因为不同层检查的是不同维度的问题:正则捕获 API 使用禁令,代码级捕获配对缺失,AST 捕获结构违规,跨文件捕获依赖问题。它们之间不是递进关系,而是互补关系。
auditFiles() 支持批量项目级审计,在单文件检查基础上增加跨文件检查,并附带 UncertaintyCollector 的完整能力报告。
ReverseGuard:反向验证
正向 Guard 检查"代码是否符合 Recipe"。但还有一个方向的问题:Recipe 所描述的代码模式还存在吗?
项目代码持续变化——类被重命名、方法签名被修改、旧模块被整体删除。如果 Recipe 还在引用已经不存在的 API,它就成了一条过期知识。ReverseGuard 的任务就是检测这种代码漂移。
五种漂移信号
// lib/service/guard/ReverseGuard.ts
type PatternDriftSignal = {
type: 'symbol_missing' | 'match_rate_drop' | 'api_deprecated' | 'zero_match' | 'source_ref_stale';
severity: 'high' | 'medium' | 'low';
detail: string;
};| 漂移类型 | 检测方式 | 严重度 |
|---|---|---|
symbol_missing | Recipe 的 coreCode 中引用的 API 符号在当前代码中已不存在 | high |
match_rate_drop | Recipe 的 guard pattern 匹配次数下降超过 70% | medium |
api_deprecated | Recipe 引用的 API 已被标记为弃用 | medium |
zero_match | Pattern 现在匹配 0 次(完全失效) | high |
source_ref_stale | Recipe 的 reasoning.sources 中引用的文件已被删除 | medium |
多语言符号提取
symbol_missing 检测需要从 Recipe 的 coreCode 中提取 API 符号,然后在当前代码中搜索。不同语言的符号格式差异巨大:
| 语言 | 符号格式 | 示例 |
|---|---|---|
| Swift/Java/Kotlin | ClassName.method | NetworkKit.request |
| ObjC | [ClassName method] | [NSURLSession dataTaskWith] |
| JS/TS/Python | import { x } from 'y' | import { useState } |
| Rust | module::Type::method | tokio::spawn |
| Go | package.Function | http.ListenAndServe |
ReverseGuard 为每种语言实现了专门的符号提取器,把 coreCode 中的 API 引用解析为可搜索的符号列表。然后在当前项目文件中逐一搜索——找不到的符号就是 symbol_missing 信号。
漂移 → 信号 → 进化
ReverseGuard 的输出是一个建议,不是自动操作:
interface ReverseGuardResult {
recipeId: string;
title: string;
signals: PatternDriftSignal[];
recommendation: 'healthy' | 'investigate' | 'decay';
}决策阈值:
- healthy:无高严重度信号
- investigate:1 个 high 信号 或 ≥ 3 个 medium 信号
- decay:≥ 2 个 high 信号
当 recommendation 为 investigate 或 decay 时,系统向 SignalBus 发出信号,触发 Ch07 中讲述的生命周期流转——Recipe 进入 decaying 状态,等待人工确认或自动进化。
这形成了一条完整的知识新陈代谢链路:
代码变化 → ReverseGuard 检测 → 漂移信号 → SignalBus
→ Lifecycle 状态机 → decaying → 进化提案 或 deprecated反馈闭环
Guard 不是一个孤立的检查工具——它通过两个机制形成闭环:Agent 自动修复和规则学习。
Agent ↔ Guard 自动修复
当 Agent 通过 MCP 调用 asd_guard 进行代码审查时,如果发现违规,Agent 会尝试自动修复。整个过程最多 5 轮:
Round 1: Agent 生成代码
Guard 检查 → 3 violations
↓
Round 2: Agent 读取 violation.fixSuggestion
Agent 修改代码
Guard 再次检查 → 1 violation
↓
Round 3: Agent 继续修复
Guard 检查 → 0 violations ✅ PASSGuardFeedbackLoop 在这个过程中做了一件巧妙的事:它对比前后两轮的 violation 列表,找出被修复的违规:
// lib/service/guard/GuardFeedbackLoop.ts
detectFixedViolations(currentResult, filePath) {
const previousRun = this.violationsStore.getRunsByFile(filePath).pop();
if (!previousRun) { return []; }
const currentRuleIds = new Set(currentResult.violations.map(v => v.ruleId));
const fixed = previousRun.violations.filter(v => !currentRuleIds.has(v.ruleId));
return fixed;
}每一条被修复的 violation 都意味着 Agent 使用了对应的 Recipe 来指导修复。系统自动记录这次 Recipe 使用——不需要 Agent 或用户手动确认:
// 自动确认 Recipe 使用
feedbackCollector.record('insert', recipeId, {
source: 'guard_fix_detection',
automatic: true,
ruleId,
filePath
});这些使用记录驱动 Ch07 中的命中计数器——guardHit 信号增加,Recipe 不会进入衰退。Guard 修复既解决了当前问题,又为知识库的健康提供了"使用证据"。一石二鸟。
RuleLearner:规则健康度
不是所有规则都同样有效。有些规则误报率很高(开发者反复手动忽略),有些规则从未触发过(可能已经过时)。RuleLearner 用精确率/召回率/F1 值追踪每条规则的健康状况:
// lib/service/guard/RuleLearner.ts
interface RuleMetrics {
triggers: number; // 总触发次数
correct: number; // 用户确认为正确的次数
falsePositive: number; // 用户驳回的次数
falseNegative: number; // 规则遗漏的次数
precision: number; // TP / (TP + FP)
recall: number; // TP / (TP + FN)
f1: number; // 2 × P × R / (P + R)
}基于 F1 值,RuleLearner 给出三种建议:
| 状态 | 条件 | 建议 |
|---|---|---|
| Tune | precision 0.3–0.5 | 调整正则模式或收窄语言范围 |
| Disable | precision < 0.3 | 误报太多,建议关闭 |
| Specialize | 高触发 + 高精确率 | 值得为项目创建专属变体 |
判定阈值:误报率 ≥ 40% 且至少触发 5 次才会标记为 problematic。这避免了对低频规则的过早判断——一条只触发过 2 次的规则,即使 1 次误报,也不足以得出"精确率 50%"的结论。
RuleLearner 的数据持久化在 Alembic/guard-learner.json,跟随 Git 版本控制——项目成员共享规则健康度数据。
三维合规报告
ComplianceReporter 生成的项目审计报告不是简单的 violation 计数,而是三个维度的综合评估:
// lib/service/guard/ComplianceReporter.ts
interface ComplianceReport {
qualityGate: {
status: 'PASS' | 'WARN' | 'FAIL';
thresholds: { maxErrors: 10; maxWarnings: 50; minScore: 70 };
};
summary: {
errors: number;
warnings: number;
infos: number;
totalViolations: number;
filesScanned: number;
};
topViolations: { ruleId: string; count: number; severity: string }[];
fileHotspots: { filePath: string; violationCount: number }[];
ruleHealth: { ruleId: string; precision: number; recall: number; f1: number }[];
trend: { errorsChange: number; warningsChange: number; hasHistory: boolean };
}维度 1:合规度(violations)。按严重度加权计分:
// 评分公式
score = 100
- (errors × 10) // 每个 error 扣 10 分
- (warnings × 5) // 每个 warning 扣 5 分
- (infos × 1) // 每个 info 扣 1 分
+ (highF1Rules × 5) // 高 F1 规则加分
- (problematicRules × 3); // 问题规则减分维度 2:覆盖率(coverage)。来自 CoverageAnalyzer——按模块统计规则覆盖率。如果某个模块 NetworkKit 有 15 条适用规则但只有 3 条被执行过,覆盖率为 20%,标记为 low。
interface ModuleCoverage {
module: string;
ruleCount: number;
fpRate: number; // 该模块的误报率
coverage: number; // 0–100
level: 'good' | 'low' | 'zero';
}维度 3:置信度(confidence)。来自 RuleLearner 的规则健康度数据——如果大部分规则的 F1 值都很高,报告的置信度就高;如果很多规则是 problematic 的,即使 violation 数为 0,也不意味着代码真的合规。
Quality Gate 综合三个维度做出最终判定:
| 状态 | 条件 |
|---|---|
| PASS | errors ≤ 10, warnings ≤ 50, score ≥ 70 |
| WARN | 超出 PASS 阈值但不严重 |
| FAIL | errors > 10 或 score < 70 |
trend 字段与历史数据对比(ViolationsStore 保留最近 200 次审计记录),展示 errors 和 warnings 的变化趋势——是在改善还是在恶化。
排除机制
不是所有代码都需要 Guard 检查。测试文件中的 force unwrap 是正常的;生成的代码文件不应触发规则;开发阶段的临时 console.log 不该阻塞提交。
ExclusionManager 提供三级排除策略:
| 级别 | 粒度 | 持久化 |
|---|---|---|
| Path Exclusion | Glob 模式排除整个路径 | guard-exclusions.json |
| Rule Exclusion | 特定文件禁用特定规则 | guard-exclusions.json |
| Global Rule Exclusion | 全局禁用某条规则 | config.json |
// Alembic/guard-exclusions.json
{
"pathExclusions": ["test/**", "*.generated.swift", "Pods/**"],
"ruleExclusions": {
"src/Debug/DebugHelper.swift": ["swift-no-console-log"]
}
}排除配置文件跟随 Git——团队成员共享统一的排除策略,避免个人随意关闭规则。
运行时行为
以四个场景展示 Guard 的实际工作方式:
场景 1:单文件正则命中
输入: UserService.swift 包含 dispatch_sync(dispatch_get_main_queue())
→ Layer 1 正则匹配 → 命中 swift-no-main-thread-sync
→ violation: { severity: 'error', line: 42,
message: '禁止在主线程同步调度',
fixSuggestion: '使用 DispatchQueue.main.async 代替' }场景 2:AST 层发现结构问题
输入: GodController.swift (45 methods, 22 properties)
→ Layer 1 正则 → 无匹配
→ Layer 2 代码级 → 无匹配
→ Layer 3 AST 语义 → 无匹配
→ Layer 4 AST 深度 → 命中 ast_god_class
{ severity: 'warning', message: 'God class: 45 methods + 22 properties' }
→ Layer 4 AST 深度 → 命中 ast_class_bloat
{ severity: 'warning', message: 'Class has 45 methods (threshold: 20)' }场景 3:Agent 自动修复循环
Round 1: Agent 生成 NetworkManager.swift
→ Guard: 2 violations
① no-force-cast (line 15): as! JSONDictionary
② no-err-ignored (line 28): result, _ = parseResponse()
Round 2: Agent 读取 fixSuggestion,修改代码
→ Guard: 0 violations ✅
→ GuardFeedbackLoop: 检测到 2 条 violation 被修复
→ 自动记录 2 条 Recipe 使用
Round 3: 不需要(Round 2 已通过)场景 4:ReverseGuard 发现知识过期
Recipe: "使用 NetworkKit.request() 发起网络请求"
coreCode: NetworkKit.request(url, completion:)
ReverseGuard 扫描项目代码:
→ symbol_missing: NetworkKit.request 不存在
(NetworkKit 已重构为 async/await API: NetworkKit.fetch())
→ source_ref_stale: Sources/NetworkKit/Request.swift 已删除
→ recommendation: 'decay'
→ SignalBus → Lifecycle → Recipe 进入 decaying 状态权衡与替代方案
为什么不用 ESLint / SwiftLint
现有 lint 框架成熟且强大,为什么还要自建 Guard?
核心区别:规则来源。ESLint 的规则是人工编写的静态配置;Guard 的规则来自知识库——Recipe 产出的约束自动成为检测规则。这意味着 Guard 的规则集会随着知识库的增长而增长,随着项目代码的变化而进化。
具体差异:
- Recipe 关联:Guard violation 携带 Recipe 引用,Agent 可以直接阅读 Recipe 的
doClause和coreCode来修复。ESLint 的错误信息只能提供通用建议。 - 三态输出:Guard 明确区分"没问题"和"不知道"。ESLint 默认"不报错就是通过"。
- ReverseGuard:ESLint 不会反过来检查"规则描述的 API 是否还存在"。
- 跨语言统一:Guard 用一套架构覆盖 8+ 语言。每种语言各自安装独立 lint 工具的管理成本高。
当然,Guard 不是 ESLint 的替代品——它们检测的维度不同。项目完全可以同时使用 ESLint(检查语法和格式)和 Guard(检查知识合规和架构约束),互补而非互斥。
为什么不用 AI 做合规检查
另一个方案:把代码和 Recipe 一起喂给 LLM,让 AI 判断是否合规。
不这样做是因为 SOUL 原则的"确定性标记"——Guard 检测的大多数规则都有确定性的答案。dispatch_sync(main_queue) 要么出现要么没出现,不需要概率推理。用 LLM 做这件事有三个问题:
- 速度:正则匹配微秒级,LLM 调用秒级。一次审计检查 500 个文件 × 60 条规则 = 30,000 次检查,LLM 不可行。
- 成本:每次 Guard 检查如果调用 LLM,Token 成本快速累积。
- 确定性:LLM 可能对同一段代码给出不同的判断。Guard 的正则和 AST 规则保证:同样的输入永远产生同样的结果。
AI 在 Guard 中的唯一入口是规则生成——Agent 在冷启动时分析代码模式,自动创建 kind='rule' 的 Recipe。规则一旦创建,执行阶段完全是确定性的工程逻辑。
uncertain 状态的成本
三态设计引入了额外复杂度——UncertaintyCollector、GuardCapabilityReport、coverage 计算都是为了管理 uncertain 状态。如果只用 pass/fail,这些组件都不需要。
但 uncertain 避免了一个更大的问题:虚假安全感。当 Guard 对一段 Rust 代码报告 "0 violations",但实际上因为 Rust 的 AST 语法包未安装导致 Layer 3 和 4 全部跳过时——coverage 可能只有 30%。报告的 "0 violations" 和 "0 violations + 30% coverage" 传递的信息截然不同。
前者让人以为代码是安全的,后者诚实地说"我只检查了 30%,在这 30% 中没发现问题"。对于安全敏感的项目来说,这种诚实比虚假的 "all clear" 更有价值。
小结
Guard 的设计可以归结为三个核心原则:
- 渐进式深度:四层检测架构让简单问题快速解决(正则微秒级),复杂问题深入分析(AST 毫秒级),而不是所有问题都用同一个重量级方案。
- 诚实边界:三态输出坦率承认检测能力的局限。
uncertain不是 bug,是 feature——它防止了误报(标记合规但实际未检查)带来的信任损失。 - 活的规则集:规则不是写死的配置文件,而是知识库的衍生产物。Recipe 增长 → 规则增长 → 检测能力增长。ReverseGuard + RuleLearner 持续淘汰过期和低效规则。
下一章我们将看到知识库的另一个核心服务——Search 如何在 Recipe 海洋中精确找到用户需要的知识。