生命周期与进化 — 知识的生老病死
知识不是静态快照,它有诞生、成长、衰退和消亡 — 六态状态机管理整个旅程。
问题场景
你提取了一条 "所有网络请求必须通过 NetworkManager 单例" 的 Recipe。半年后,团队重构为 async/await 原生并发,NetworkManager 已经被弃用。但 Recipe 还在,AI 继续按旧模式生成代码——更糟的是,Guard 会对新代码报出 violation,因为它没有经过早已废弃的 NetworkManager。
另一种场景:Agent 在冷启动时生成了两条几乎相同的 Recipe,描述同一个设计模式但措辞略有不同。搜索时两条都被命中,用户无法确定哪条是权威版本。
还有一种场景:某条 Recipe 的 reasoning.sources 引用了三个文件,其中两个在最近的重构中被删除了。这条知识的"证据链"已经断裂,但系统不会自动发现。
这三个场景指向同一个根本问题:代码在持续进化,知识库如果不跟上,就会从资产变成负债。
一个知识引擎不能只解决"如何提取知识"的问题。它必须同时解决:知识什么时候生效?如何安全地更新?什么时候过时?怎样退出?
设计决策
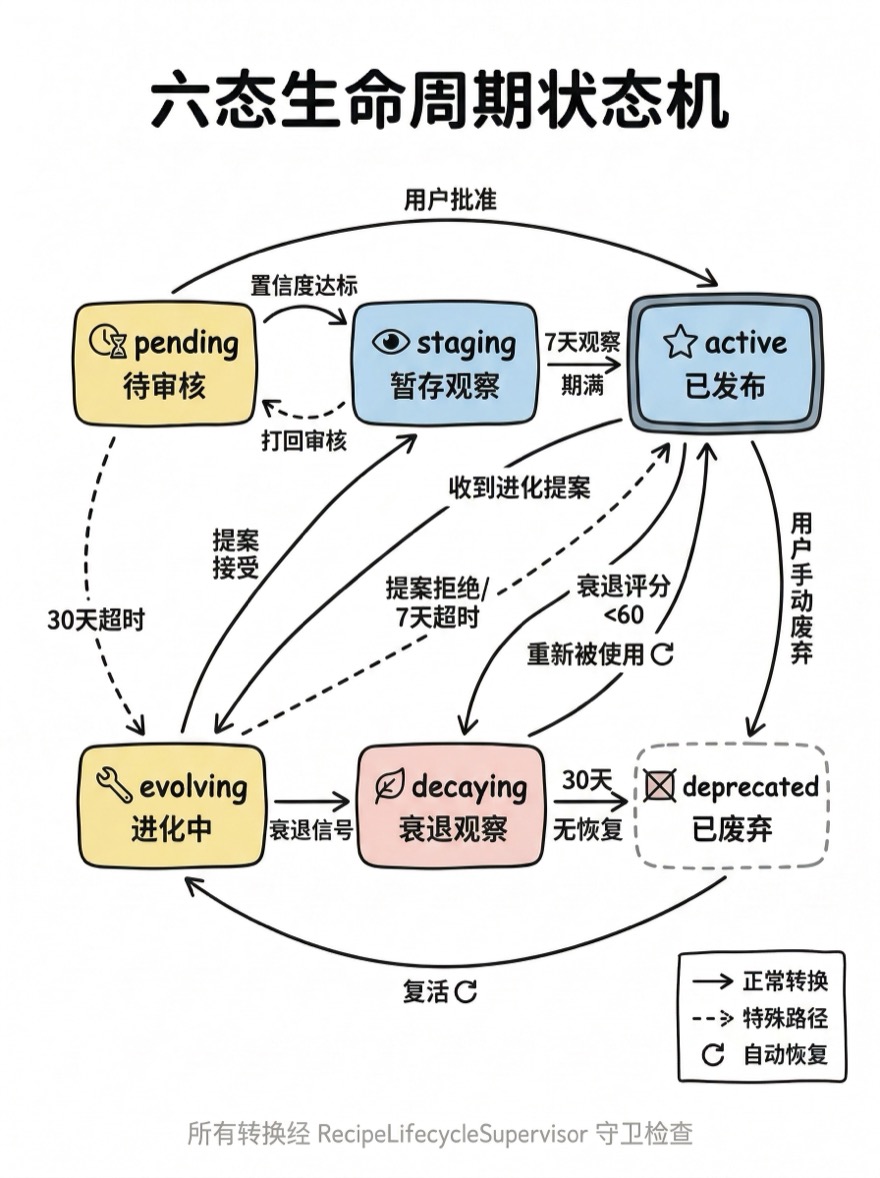
六态状态机
传统知识库通常只有两种状态:active(有效)和 archived(归档)。这对于人工维护的文档也许够用——人可以在切换状态时完成所有必要的判断。但对于 AI 驱动的知识引擎,二态模型无法区分两种截然不同的情况:
- 一条知识"正在被评估中"和"已经完全可用"——消费方(搜索、Guard)应该给予不同的权重
- 一条知识"正在被修改"和"正在衰退"——前者只是暂时不稳定,后者可能需要永久退出
Alembic 设计了六态生命周期模型:
pending → staging → active → evolving → decaying → deprecated每个状态有明确的语义和消费规则:
| 状态 | 语义 | 搜索可见 | Guard 参与 | 权重 |
|---|---|---|---|---|
pending | 待审核,所有新条目的初始状态 | ✗ | ✗ | — |
staging | 暂存期,高置信度条目在此观察 | ✓ | ✓ | 降权 |
active | 已发布,正式知识 | ✓ | ✓ | 全权重 |
evolving | 进化中,有 Evolution Proposal 附着 | ✓ | ✓ | 全权重 |
decaying | 衰退观察期,可能已过时 | ✓(降权) | ✓(降级为 warning) | 降级 |
deprecated | 已废弃 | ✗ | ✗ | — |
状态分组在代码中定义为常量数组,供搜索、Guard、统计等模块直接引用:
// lib/domain/knowledge/Lifecycle.ts
/** 可消费状态(Guard/Search/Delivery 可使用的状态) */
export const CONSUMABLE_STATES = [
Lifecycle.STAGING,
Lifecycle.ACTIVE,
Lifecycle.EVOLVING,
];
/** 降级消费状态(Guard violation 降为 warning,Search 降权) */
export const DEGRADED_STATES = [Lifecycle.DECAYING];
/** Guard 可消费状态(含降级 decaying)*/
export const GUARD_LIFECYCLES = [
Lifecycle.STAGING,
Lifecycle.ACTIVE,
Lifecycle.EVOLVING,
Lifecycle.DECAYING,
] as const;注意 CONSUMABLE_STATES 和 GUARD_LIFECYCLES 的区别:Guard 检查会遍历 GUARD_LIFECYCLES(包括 decaying),但 decaying 状态的规则产生的 violation 会被降级为 warning——提示开发者可能有问题,但不阻断工作流。这是一个刻意的设计:衰退期的知识仍然可能是有价值的,只是不够确定。
合法的状态转换定义在一张静态表中:
// lib/domain/knowledge/Lifecycle.ts
const VALID_TRANSITIONS: Record<string, string[]> = {
[Lifecycle.PENDING]: [Lifecycle.STAGING, Lifecycle.ACTIVE, Lifecycle.DEPRECATED],
[Lifecycle.STAGING]: [Lifecycle.ACTIVE, Lifecycle.PENDING],
[Lifecycle.ACTIVE]: [Lifecycle.EVOLVING, Lifecycle.DECAYING, Lifecycle.DEPRECATED],
[Lifecycle.EVOLVING]: [Lifecycle.STAGING, Lifecycle.ACTIVE, Lifecycle.DECAYING],
[Lifecycle.DECAYING]: [Lifecycle.ACTIVE, Lifecycle.DEPRECATED],
[Lifecycle.DEPRECATED]: [Lifecycle.PENDING],
};
export function isValidTransition(from: string, to: string): boolean {
const normalFrom = normalizeLifecycle(from);
const normalTo = normalizeLifecycle(to);
const allowed = VALID_TRANSITIONS[normalFrom];
return Array.isArray(allowed) && allowed.includes(normalTo);
}几个值得注意的转换路径:
deprecated → pending:已废弃的知识可以被"复活"——回到待审核状态重新走一遍晋升流程。这不是随意设计的,而是因为在实践中确实存在"某个被废弃的库重新被采用"的情况。evolving → staging:进化后的知识不直接回到active,而是进入staging重新观察。即使是对已有知识的修改,也要经过一个 grace period——这是 SOUL 原则中"永不覆盖"精神的体现。staging → pending:暂存期的知识可以打回待审核。这发生在用户通过 Dashboard 发现某条自动晋升的候选存在问题时。
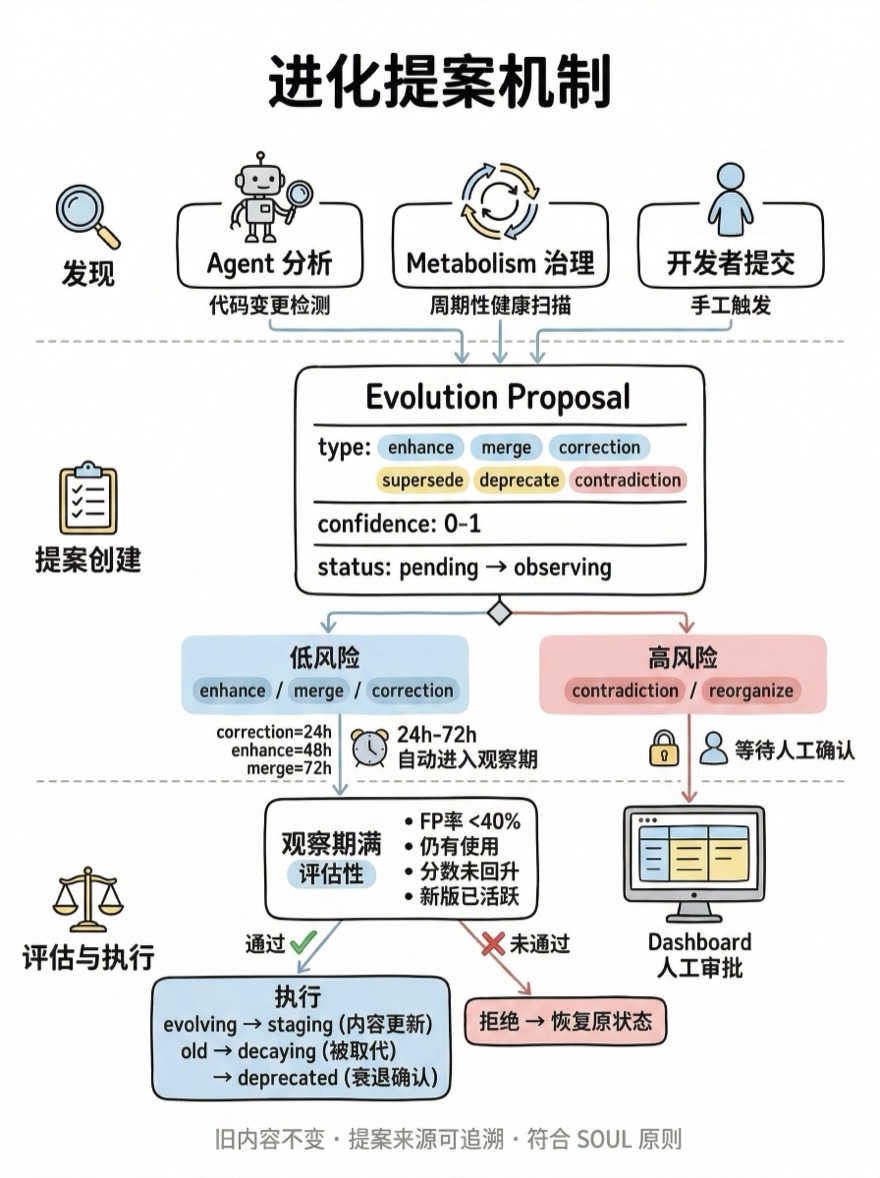
进化而非直接修改
知识库最危险的操作不是"删除一条知识"——而是"悄悄修改一条知识的内容"。
假设 Agent 在一次代码分析中"发现"某条 Recipe 的 coreCode 需要更新。如果系统允许 Agent 直接修改,会产生两个风险:
- AI 幻觉风险:Agent 可能产生错误的判断,用一段有问题的代码替换了正确的代码。由于修改是原地发生的,旧内容不可恢复。
- 静默漂移:知识的内容在没有任何人知道的情况下发生了变化。下次 Guard 根据修改后的规则检查代码时,开发者完全不知道规则已经变了。
Alembic 的安全设计是:Agent 永远不能直接修改已有知识,只能提出进化提案(Evolution Proposal)。
进化提案是一种"附加"机制——它不修改原有知识的任何字段,而是创建一条独立的提案记录,关联到目标 Recipe。提案有六种类型:
| 类型 | 语义 | 风险等级 |
|---|---|---|
enhance | 增强现有知识(添加示例、扩展适用场景) | 低 |
merge | 合并两条语义相似的知识 | 低 |
correction | 修正事实性错误(代码片段过时等) | 低 |
supersede | 新知识完全取代旧知识 | 中 |
deprecate | 标记为过时(来自衰退检测) | 中 |
contradiction | 检测到与其他知识的硬矛盾 | 高 |
风险等级决定了提案的执行路径。低风险提案(enhance、merge、correction)经过一个观察期后可以自动执行——如果在观察期内没有出现负面信号(如误报率上升、使用量下降)。高风险提案(contradiction)永远不会自动执行,必须由开发者在 Dashboard 上明确确认。
// lib/service/evolution/ProposalExecutor.ts
const HIGH_RISK_TYPES = new Set<ProposalType>([
'contradiction',
'reorganize',
]);观察期的长度也因类型而异:
| 提案类型 | 观察窗口 |
|---|---|
correction | 24 小时 |
enhance | 48 小时 |
merge / supersede | 72 小时 |
deprecate / contradiction / reorganize | 7 天 |
这些时间窗口不是拍脑门的数字。enhance 类型的风险最低——它只是往已有知识上添加内容,24 小时足以观察有没有新增误报。merge 涉及两条知识的合并,需要更长时间观察合并后的搜索命中情况。deprecate 则需要 7 天,因为一条知识可能只在每周一次的发版流程中被使用——7 天覆盖一个完整的开发周期。
为什么不让 Agent 直接修改知识?根本原因是 SOUL 原则中的两条硬约束:永不删除(所有变更都是新增操作,旧版本保留在审计日志中)和无 AI 不伪装(AI 的判断必须标记为 AI 产出,不能假装是人工确认的)。进化提案机制天然满足这两条约束:旧内容不变、提案来源明确(source: 'ide-agent' | 'metabolism' | 'decay-scan')。
架构与数据流
状态转换触发条件
六态状态机的每一次转换都有明确的触发条件和前置检查。RecipeLifecycleSupervisor 是状态转换的统一入口——所有状态变更都必须通过它,绕过它直接修改数据库中的 lifecycle 字段是被禁止的。
pending → staging
新创建的知识条目初始状态为 pending。当 ConfidenceRouter 判断其置信度满足阈值时,自动推进到 staging。置信度的阈值因 kind 而异:rule 类型要求较高的置信度(因为规则会影响 Guard 检查),fact 类型要求较低(事实性描述的风险小)。
staging → active
两条路径:
- 路径 A(自动):暂存期(7 天)满且无负面反馈(无用户打回、无验证错误)。
RecipeLifecycleSupervisor.checkTimeouts()定期检查暂存时间。 - 路径 B(手动):用户在 Dashboard 上审阅后主动批准。
active → evolving
当系统或 Agent 创建了一条关联到该 Recipe 的 Evolution Proposal,目标 Recipe 自动进入 evolving 状态。进入 evolving 不影响消费——Recipe 仍然以全权重参与搜索和 Guard,只是系统记录了一个 evolvingStartedAt 时间戳用于超时监控。
evolving → staging / active
提案被接受(内容更新)→ 进入 staging 重新观察。提案被拒绝 → 回到 active。如果 evolving 状态超过 7 天无结论,RecipeLifecycleSupervisor 自动回退到 active——这是一个安全网,防止提案被遗忘导致知识长期卡在中间态。
// lib/service/evolution/RecipeLifecycleSupervisor.ts
const TIMEOUT_MS = {
evolving: 7 * 24 * 60 * 60 * 1000, // 7 天
decaying: 30 * 24 * 60 * 60 * 1000, // 30 天
staging: 7 * 24 * 60 * 60 * 1000, // 7 天(安全兜底,正常由 StagingManager 处理)
pending: 30 * 24 * 60 * 60 * 1000, // 30 天
};
const TIMEOUT_TARGET = {
evolving: 'active', // 回退到 active(内容不变)
decaying: 'deprecated', // 长期衰退 → 废弃
pending: 'deprecated', // 30 天未审核 → 废弃
};active → decaying
这是最关键的自动转换——它不依赖定时任务,而是由 DecayDetector 的信号驱动。当 DecayDetector 评估一条 active 状态的 Recipe 分数低于 60 分时,触发 active → decaying 转换。衰退评分的计算在下文详述。
decaying → active(自动恢复)
如果处于 decaying 状态的 Recipe 重新被搜索命中或被 Guard 使用(searchHit 或 guardHit 信号),系统判断它仍然有价值,自动恢复到 active。这个自动恢复机制是信号驱动设计的典型体现——不需要人工干预,使用行为本身就是最好的信号。
decaying → deprecated
30 天的衰退观察期内没有恢复信号,RecipeLifecycleSupervisor.checkTimeouts() 自动将其推进到 deprecated。特殊情况:如果 DecayDetector 给出 dead 级别(0-19 分),跳过 30 天等待直接废弃。
每一次状态转换都会被记录为不可变的 TransitionEvent:
interface TransitionEvent {
recipeId: string;
from: string;
to: string;
reason: string;
triggeredBy: string; // 'system' | 'user' | 'decay-scan' | 'proposal-executor'
timestamp: number;
}这些事件构成了一条知识的完整"传记"——你可以在 Dashboard 中回溯任何一条 Recipe 的生命历程:它何时被创建、何时进入观察、何时正式发布、是否经历过进化提案、是否衰退过又恢复。
SourceRef 可信链
上一章提到,KnowledgeEntry 的 reasoning.sources 字段保存了知识的来源文件路径——它是知识的"证据链"。但文件路径是脆弱的:文件会被重命名、移动、删除。如果证据链断裂了,知识的可信度就应该下降。
SourceRefReconciler 负责维护这个可信链的健康状态。它管理一张独立的 recipe_source_refs 表,每条记录有三种状态:
| 状态 | 含义 |
|---|---|
active | 文件存在,路径有效 |
renamed | 文件被 git rename,新路径已检测到 |
stale | 文件不存在,无法自动修复 |
核心流程分三个阶段:
阶段 1:reconcile() — 存在性验证
遍历所有 Recipe 的 reasoning.sources,检查文件是否仍然存在于项目目录中。验证结果有 24 小时 TTL 缓存——同一天内不会重复检查同一个路径。如果发现 stale 引用,发射 quality 信号,信号权值与 stale 比例成正比。
阶段 2:repairRenames() — git rename 追踪
对于标记为 stale 的引用,尝试通过 git log --diff-filter=R 追踪文件的重命名历史。如果发现旧路径被 rename 到了新路径,将引用状态更新为 renamed 并记录 new_path。这个步骤使用 execFile() 的数组参数形式执行 git 命令,而非模板字符串拼接——防止路径中的特殊字符被用于命令注入。
阶段 3:applyRepairs() — 写回修复
将 renamed 状态的引用自动修复回 Recipe 的 .md 文件中。定位 reasoning.sources 部分,将旧路径替换为新路径,然后将引用状态更新为 active。
这三个阶段不是在一次调用中串行执行的。reconcile() 可能在每次 Guard 运行后触发,repairRenames() 在每次项目扫描时运行,applyRepairs() 需要在用户确认后执行。它们通过信号机制松散耦合。
SourceRef 的健康度直接影响衰退评分。DecayDetector 在计算 authority 维度时会查询 stale ratio:
authority = baseAuthority × (1 - staleRatio × 0.3)当所有 SourceRef 都失活时(staleRatio = 1.0),authority 维度被乘以 0.7 的惩罚因子。这个惩罚不会让一条高质量的知识立刻衰退,但会在边界情况下把它推入 decaying 状态——给用户一个机会去审视它是否还有价值。
核心实现
RecipeProductionGateway — 统一生产管线
所有 Recipe 创建——不论来自 Agent Tool、MCP 外部调用、IDE Agent 还是批量导入——都通过 RecipeProductionGateway 的统一管线。它保证无论入口在哪,前置校验的顺序和严格度完全一致。
管线分为 7 个步骤,每个步骤有独立的中止和回退逻辑:
Step 1: Schema Validation (UnifiedValidator)
↓ 不通过 → rejected[]
Step 2: Similarity Check (可选跳过)
↓ 相似度 ≥ 0.7 → duplicates[]
Step 3: Consolidation Scan (可选跳过)
↓ 建议 merge/reorganize → merged[] / blocked[]
Step 4: KnowledgeService.create()
↓ ConfidenceRouter → staging 或 pending
Step 5: Quality Scoring (best effort)
↓ 不阻塞创建流程
Step 6: Supersede Proposal (如果指定被替代的旧 Recipe)
Step 7: Audit 日志// lib/service/knowledge/RecipeProductionGateway.ts
type GatewaySource = 'agent-tool' | 'mcp-external' | 'ide-agent' | 'batch-import';
interface CreateRecipeResult {
created: CreatedRecipeInfo[]; // ✅ 成功创建
rejected: RejectedRecipeInfo[]; // ❌ 校验不通过
merged: MergedRecipeInfo[]; // ⚠️ ConsolidationAdvisor 建议合并,已建提案
blocked: BlockedRecipeInfo[]; // 🚫 被融合建议阻止
duplicates: SimilarRecipeInfo[]; // 📍 相似度过高
supersedeProposal: { proposalId: string } | null;
}Step 1 — Schema Validation
UnifiedValidator 检查必填字段(title、trigger、description 等)的合法性,同时在批量提交中追踪已提交的标题和指纹集合(existingTitles / existingFingerprints),防止批量内重复。
Step 2 — Similarity Check
对每个候选调用 findSimilarRecipes(),阈值 0.5 召回候选、0.7 判定重复。重复项记入 duplicates[] 但不阻塞(信息性警告)。batch-import 来源可通过 skipSimilarityCheck 跳过此步骤。
Step 3 — Consolidation Scan
ConsolidationAdvisor.analyzeBatch() 对通过相似度检查的候选做融合分析——如果发现某个候选与已有 Recipe 高度重叠,建议 merge、reorganize 或 supersede。建议被转换为 Evolution Proposal 写入 evolution_proposals 表,候选本身不创建。ConsolidationAdvisor 失败时静默降级——直接进入 Step 4。
Step 4 — Create
通过 KnowledgeService.create() 写入数据库,ConfidenceRouter 根据置信度决定进入 staging 还是 pending。
Step 5 — Quality Scoring
创建后立即调用 updateQuality() 执行 5 维度质量评分。这是 best effort——评分失败不回滚创建。
Step 6 — Supersede Proposal
如果调用方指定了 options.supersedes(被替代的旧 Recipe ID),在新 Recipe 创建成功后自动创建 supersede 类型的进化提案,关联新旧 Recipe。
这个设计的核心价值是入口统一——Agent 通过 submit_knowledge 工具调用和用户通过 MCP asd_submit_knowledge 走完全相同的校验管线。没有"捷径"可以绕过 Schema Validation 或 Similarity Check 直接创建 Recipe。
RecipeLifecycleSupervisor
RecipeLifecycleSupervisor 是所有状态转换的守门人。它不只是检查 VALID_TRANSITIONS 表——在每次转换的进入和退出时执行副作用:
// lib/service/evolution/RecipeLifecycleSupervisor.ts(简化)
async transition(request: TransitionRequest): Promise<TransitionResult> {
const { recipeId, from, to, reason, triggeredBy } = request;
// 1. 守卫检查:合法性
if (!isValidTransition(from, to)) {
return { success: false, error: `Invalid transition: ${from} → ${to}` };
}
// 2. Exit Action — 离开旧状态
this.#recordExitTimestamp(recipeId, from);
// 3. Entry Action — 进入新状态
this.#recordEntryTimestamp(recipeId, to);
// 4. 持久化 lifecycle 字段
await this.#repository.updateLifecycle(recipeId, to);
// 5. 记录不可变事件
this.#eventLog.push({ recipeId, from, to, reason, triggeredBy, timestamp: Date.now() });
return { success: true };
}Entry/Exit Action 记录的时间戳被后续模块消费:例如 stagingEnteredAt 用于计算暂存期是否满 7 天,evolvingStartedAt 用于检测进化提案是否超时。
checkTimeouts() 是 Supervisor 的另一个核心方法。它扫描所有处于中间态(evolving、decaying、pending、staging)的 Recipe,检查是否超过预设时间:
async checkTimeouts(): Promise<TimeoutCheckResult> {
const now = Date.now();
const results = [];
for (const [state, timeoutMs] of Object.entries(TIMEOUT_MS)) {
const stuck = await this.#repository.findByLifecycleOlderThan(state, now - timeoutMs);
for (const recipe of stuck) {
const target = TIMEOUT_TARGET[state];
await this.transition({
recipeId: recipe.id,
from: state,
to: target,
reason: `Timeout: stuck in ${state} for >${timeoutMs / DAY_MS}d`,
triggeredBy: 'system',
});
results.push({ recipeId: recipe.id, from: state, to: target });
}
}
return { transitioned: results };
}这个方法不是 cron job 调用的——它在每次知识库操作(搜索、Guard 检查、Dashboard 访问)的伴随流程中被触发。这符合 SOUL 原则"信号驱动 > 时间驱动"的设计哲学:不依赖外部调度器,而是利用用户的使用行为作为"心跳"。
DecayDetector:四维衰退评分
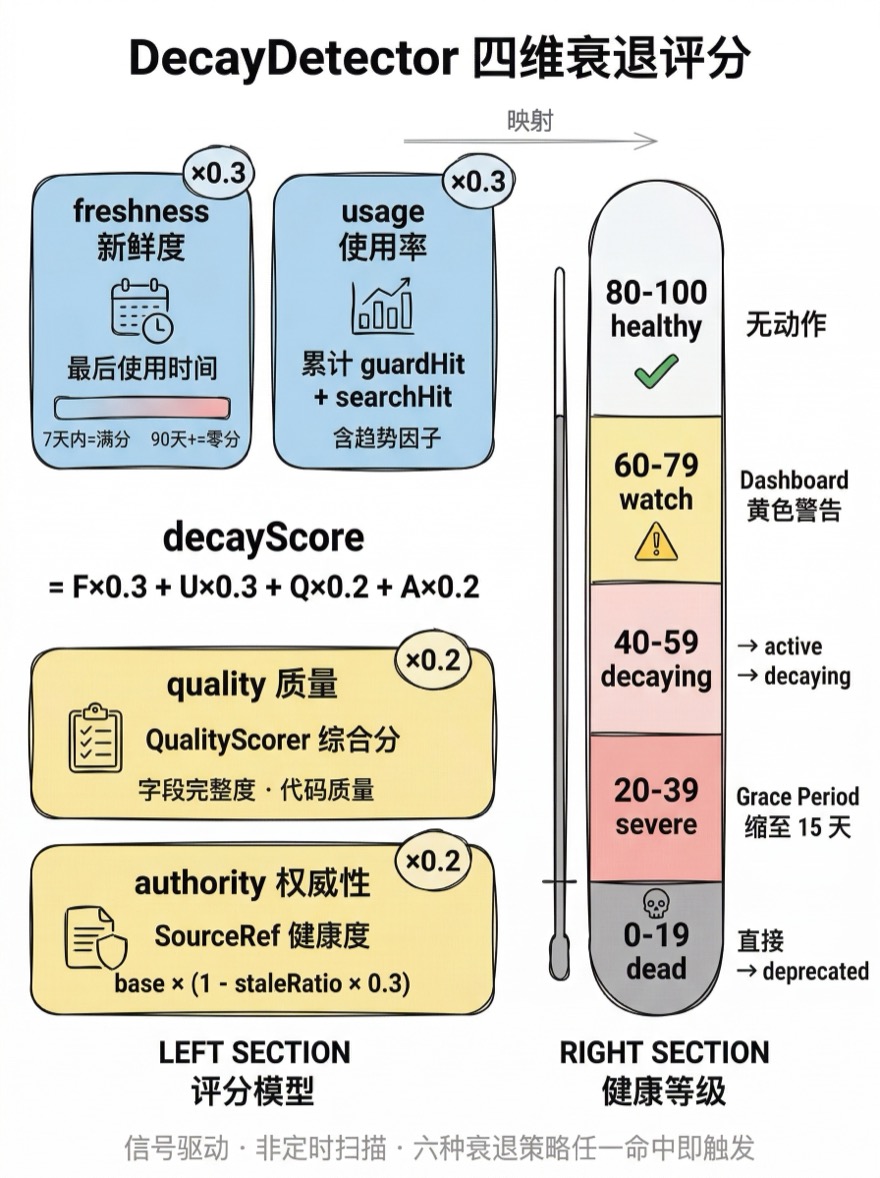
DecayDetector 是衰退信号的核心引擎。它不是简单地检查"最后使用时间是否超过 N 天"——而是用四个维度综合评估一条知识的健康度:
decayScore = freshness × 0.3 + usage × 0.3 + quality × 0.2 + authority × 0.2freshness(新鲜度 · 0.3 权重)
基于最后一次被使用的时间距今。365 天无使用得 0 分,当天使用过得满分,中间线性插值(1 - daysSinceHit / 365)。这里的"使用"包括两种信号:guardHit(Guard 检查时命中该 Recipe 的规则)和 searchHit(搜索结果中返回了该 Recipe)。
usage(使用率 · 0.3 权重)
统计最近 90 天的命中次数(hitsLast90d),归一化为 0-1 分数:min(1, hitsLast90d / 50)——即 50 次以上命中得满分,0 次得 0 分。注意这里只看近期窗口而非全生命期累计:如果一条知识在最近 90 天完全没有被使用,usage 维度得分为零。这是一个刻意的设计选择——衰退检测关注的是"现在还有没有价值",而非"历史上曾经有过多少价值"。
quality(质量 · 0.2 权重)
来自 QualityScorer v2 的综合评分。v2 采用五维度加权模型:结构完整性(completeness, 0.25)、内容深度(contentDepth, 0.30)、交付就绪度(deliveryReady, 0.20)、可操作性(actionability, 0.15)、溯源可信度(provenance, 0.10)。低质量的知识更容易被判定为衰退——这是一个有意义的设计选择:如果一条知识本身质量就不高,又长期无人使用,它几乎可以确定是过时的。
authority(权威性 · 0.2 权重)
基于 SourceRef 健康度。当引用文件大量失活时,authority 下降,推动衰退评分恶化。这是 SourceRefReconciler 和 DecayDetector 的连接点。
评分结果映射为五个级别:
| 分数 | 级别 | 系统行为 |
|---|---|---|
| 80-100 | healthy | 无动作 |
| 60-79 | watch | Dashboard 显示黄色警告 |
| 40-59 | decaying | 触发 active → decaying 转换 |
| 20-39 | severe | 缩短 Grace Period 至 15 天 |
| 0-19 | dead | 跳过确认,直接 deprecated |
除了综合评分,DecayDetector 还检测六种具体的衰退策略:
// 六种衰退策略(任一命中即产生衰退信号)
type DecayStrategy =
| 'no_recent_usage' // 90+ 天无使用
| 'high_false_positive' // 误报率 >40%(至少 10 次触发)
| 'symbol_drift' // ReverseGuard 检测到 API 符号已删除
| 'source_ref_stale' // SourceRef 引用路径失活
| 'superseded' // 存在 deprecated_by 关系指向更新版本
| 'contradiction'; // ContradictionDetector 发现硬矛盾symbol_drift 策略值得特别说明。当 ReverseGuard 执行反向验证时,它会检查 Recipe 的 coreCode 中引用的 API 符号是否仍然存在于项目代码中。如果 coreCode 中调用了 NetworkManager.shared.request(),但项目中 NetworkManager 类已经被彻底删除,symbol_drift 会被触发。这比简单的"无人使用"更精准——它直接检测知识内容的语义有效性。
KnowledgeMetabolism:治理编排
KnowledgeMetabolism 是知识治理的编排层——它不做具体的检测工作,而是协调 DecayDetector、ContradictionDetector、RedundancyAnalyzer 三个引擎的执行顺序,收集结果,生成进化提案。
一个完整的治理周期:
// lib/service/evolution/KnowledgeMetabolism.ts(简化)
async runFullCycle(): Promise<MetabolismResult> {
// 1. 衰退扫描 — 哪些知识在变旧?
const decayResults = await this.#decayDetector.scanAll();
// 2. 矛盾检测 — 哪些知识互相冲突?
const contradictions = await this.#contradictionDetector.detectAll();
// 3. 冗余分析 — 哪些知识在说同一件事?
const redundancies = await this.#redundancyAnalyzer.analyzeAll();
// 4. 生成提案
const proposals = [
...this.#createDecayProposals(decayResults),
...this.#createContradictionProposals(contradictions),
...this.#createMergeProposals(redundancies),
];
// 5. 持久化到 evolution_proposals 表
await this.#proposalRepository.insertBatch(proposals);
// 6. 发射信号触发下游(如 Dashboard 通知)
this.#signalBus.emit('quality', { type: 'metabolism-complete', proposals });
return { decayResults, contradictions, redundancies, proposals };
}runFullCycle() 不是定时执行的。它通过 SignalBus 订阅 decay | quality | anomaly 信号,30 秒防抖后执行。触发信号的来源包括:
- Guard 检查发现高误报率 → 发射
quality信号 - SourceRefReconciler 发现大量 stale 引用 → 发射
quality信号 - 用户在 Dashboard 标记某条知识有问题 → 发射
anomaly信号
30 秒防抖的设计是为了批量处理:如果一次项目扫描触发了 10 个 quality 信号,系统只会在最后一个信号后 30 秒执行一次 runFullCycle(),而不是执行 10 次。
ProposalExecutor:到期提案执行
提案在观察期内是"待评估"状态(observing)。ProposalExecutor 负责检查哪些提案的观察期已满,并根据观察期内收集到的信号决定是否执行。
核心判据是:提案创建后的这段时间里,被提案的 Recipe 的使用情况有没有变化?
// lib/service/evolution/ProposalExecutor.ts(简化判据)
async #evaluateProposal(proposal, currentMetrics, snapshot): Promise<Decision> {
switch (proposal.type) {
case 'merge':
case 'enhance':
// FP 率 <40% 且仍有使用 → 通过
return currentMetrics.fpRate < 0.4 && currentMetrics.totalHits > 0
? 'execute' : 'reject';
case 'supersede':
// 新 Recipe 已 active 且使用量 ≥ 旧的 50% → 通过
return newRecipe.lifecycle === 'active'
&& newRecipe.usage >= oldRecipe.usage * 0.5
? 'execute' : 'reject';
case 'deprecate':
// decay score 无回升 → 通过
return currentMetrics.decayScore <= snapshot.decayScore
? 'execute' : 'reject';
case 'correction':
// 有使用信号 → 通过
return currentMetrics.totalHits > 0 ? 'execute' : 'reject';
}
}执行动作因提案类型而异:
- merge/enhance:将 Recipe 推入
evolving,应用内容补丁,然后进入staging重新观察 - supersede:旧 Recipe 推入
decaying,在知识图中建立deprecated_by边指向新 Recipe - deprecate:根据衰退级别推入
decaying或直接deprecated - correction:推入
evolving,应用修正,进入staging
如果观察期内 Recipe 的情况好转(比如被重新使用、误报率下降),提案会被自动拒绝。这就是观察期存在的意义——它给了系统一个"后悔"的窗口。
运行时行为
场景 1:新建候选的晋升之路
Agent 在项目冷启动时提取了一条关于 CookieProviding 的 Recipe,置信度 0.85。
- T+0:Recipe 创建,状态
pending - T+0(秒级):ConfidenceRouter 评估置信度 0.85 高于阈值,自动推进到
staging - T+7 天:
RecipeLifecycleSupervisor.checkTimeouts()检测到暂存期满且无负面反馈 →staging → active - T+7 天后:Recipe 以全权重参与搜索和 Guard 检查
场景 2:重构导致的自然衰退
团队决定弃用 NetworkManager,用原生 async/await 重写网络层。
- T+0:
NetworkManager.swift被删除 - T+N(下次扫描):
SourceRefReconciler.reconcile()发现引用该文件的三条 Recipe 的 SourceRef 变为stale - T+N:发射
quality信号(stale_ratio: 0.67) - T+N+30s:
KnowledgeMetabolism.runFullCycle()被触发 - T+N+30s:
DecayDetector评估三条 Recipe:authority 大幅下降 + 无近期使用 → decayScore 42 分(decaying级别) - T+N+30s:Metabolism 生成三条
deprecate类型的提案,观察期 7 天 - T+N+30s:三条 Recipe 进入
decaying状态 - T+N+7 天:
ProposalExecutor检查——decay score 无回升,提案通过 →decaying → deprecated
场景 3:Agent 驱动的知识增强
Agent 在一次代码分析中发现某条 Recipe 的 coreCode 缺少了错误处理的示例。
- T+0:Agent 通过 MCP 工具创建一条
enhance类型的进化提案 - T+0:目标 Recipe 进入
evolving状态 - T+0:提案进入
observing状态,观察窗口 24-48 小时 - T+36h:
ProposalExecutor检查——FP 率仍然为 0,且 Recipe 在观察期内有 3 次使用命中 → 通过 - T+36h:Recipe 内容被更新(新增错误处理示例),状态推入
staging - T+36h+7 天:暂存期满,无负面反馈 →
staging → active
场景 4:冗余知识的合并
RedundancyAnalyzer 在一次治理周期中检测到 Recipe A("使用 CookieProviding 管理 Cookie")和 Recipe B("Cookie 操作必须通过 CookieProviding")语义相似度 > 0.85。
- T+0:
KnowledgeMetabolism生成一条merge提案,关联 Recipe A 和 B - T+0:两条 Recipe 都进入
evolving状态 - T+72h:
ProposalExecutor检查——两条 Recipe 都有使用记录,FP 率正常 → 通过 - T+72h:执行合并——保留 Recipe A 作为主体,将 B 的独特内容合入 A,B 推入
deprecated并建立merged_into关系边 - T+72h:合并后的 Recipe A 进入
staging重新观察
权衡与替代方案
为什么不用二态模型?
简单的 active / archived 二态模型面临三个无法回避的问题:
- 缺少缓冲区:新创建的知识直接进入
active,没有观察窗口让人或系统验证其质量。对于 AI 生成的知识,这是不可接受的风险。 - 无法区分变化类型:一条正在被修改的知识和一条正在衰退的知识,在二态模型下都是
active——但系统对它们应该有不同的处理策略。 - 归档不可逆:一旦标记为
archived,恢复成本很高,因为两个状态之间没有中间地带。六态模型中的decaying状态天然支持自动恢复。
为什么不让 Agent 直接修改?
最直接的方案确实是允许 Agent 在发现更好的模式时直接更新 Recipe 内容。但这引入了两个不对称风险:
- 修改正确的概率 << 幻觉错误的成本:Agent 修改对了,知识库改善一点点;Agent 修改错了,可能导致后续所有基于此 Recipe 的代码检查和生成都出错。
- 静默漂移的可追溯性:如果允许直接修改,要准确回答"这条知识为什么变成现在这样"需要完整的 diff 历史——而进化提案机制天然记录了每次变更的原因、来源和判据。
提案机制的代价是增加了中间步骤和延迟。一个 enhance 类型的改进需要等待 24-48 小时的观察期才能生效。在 Alembic 的设计判断中,知识库的准确性比更新的及时性更重要——一条过时但正确的知识,远好于一条新但错误的知识。
staging 期的价值
有人可能质疑:既然已经有了 pending(待审核),为什么还需要 staging?它们的区别是什么?
pending 是"尚未被系统信任"——搜索不可见、Guard 不使用。staging 是"系统初步信任,但给用户一个观察窗口"——搜索可见(降权)、Guard 参与(降权),用户可以在 Dashboard 上看到这些"试用版"的知识条目。
这个设计的核心价值是渐进式信任。对于一个 AI 驱动的系统,让用户参与但不要求用户参与——高置信度的知识自动走完 staging → active,低置信度的停留在 staging 等待人工审阅。这比"全自动"或"全手动"都更符合实际的工作流。
小结
知识生命周期是 Alembic 中最能体现"信号驱动"设计哲学的子系统。六态状态机不是复杂性的来源,而是复杂性的管理工具——每个状态对应一种明确的知识状态语义,每次转换都有可追溯的触发条件和审计日志。
进化提案机制将 AI 的能力(发现、建议、评估)和人类的判断(确认、否决)分离到不同的阶段——低风险的变更自动化,高风险的交给人。这不是对 AI 能力的不信任,而是对知识库准确性的工程保障。
下一章将探讨质量评分体系——它是 ConfidenceRouter 和 DecayDetector 的数据来源,也是知识从候选到正式的关键判据。
下一章