代码理解 — 多语言 AST · Discovery · 增强
Alembic 如何"看懂"一个项目:从语法树到架构全景。
问题场景
Alembic 要从代码中提取知识,第一步是理解代码。但"理解"有层次——你可以用正则表达式找到 class 关键字,但你无法知道这个类继承了谁、实现了什么接口、被哪些方法调用。更困难的是,系统要同时理解 10+ 种编程语言,每种语言的语法和语义模型都不同。
一个 Swift 项目有 protocol、extension、@propertyWrapper;一个 Java 项目有 interface、@Annotation、record;一个 Rust 项目有 trait、impl 块、derive 宏。如果为每种语言写一套独立的分析系统,代码维护成本会随语言数量线性增长。如果用正则做字符串匹配,跨行声明和嵌套结构会产生大量误报。
Alembic 的策略是:用 Tree-sitter 的 WASM 引擎做确定性语法解析,然后通过统一的抽象类型把 10+ 种语言的语法差异收敛到一个接口——上层的知识提取、模式检测和架构分析完全不需要关心底层是 Swift 还是 Python。
设计决策回溯:从专用解析器到通用 WASM
在讲述 Tree-sitter WASM 方案之前,值得回溯一段关键的技术决策历程——它解释了为什么系统没有走"每种语言一个专业解析器"的路线。
项目初期,Alembic 使用的是 Swift SPM(Swift Package Manager)专用解析器来处理 Swift 项目的依赖关系——解析 Package.swift 中的 target 定义、依赖声明和模块结构。这个解析器能准确还原 SPM 的依赖图,为后续的模块分析提供了可靠的基础数据。
但仅仅是这一个 SPM 解析器,就暴露了专用方案的致命问题:
- 安装过程极其繁琐。SPM 解析器作为 npm 包依赖,包含原生二进制文件,安装过程需要下载平台特定的编译产物。在用户执行
npm install后,这些包只能作为后置依赖安装(postinstall),耗时从 30 秒到数分钟不等——取决于网络环境和平台缓存。对于一个 CLI 工具来说,这是不可接受的首次体验。而这还只是一个语言的一个子功能的代价。 - 语言覆盖的线性成本。如果连 SPM 依赖解析都需要一个专用包,那代码结构分析呢?要支持 Java,就要找到 Java 的专业解析器包并集成;要支持 Go,又要找另一个。每增加一种语言,就要处理一次原生绑定的平台兼容性、版本锁定和安装体积问题。到了 Kotlin、Dart、Rust 这些相对小众语言,甚至找不到成熟可用的 npm 解析器包。
转折点出现在 Tree-sitter WASM 方案的评估。Tree-sitter 的 WASM 模式将每种语言的语法规则编译为一个独立的 .wasm 文件(单个文件约 500KB–1.5MB),这些文件是预编译的、跨平台一致的、无需原生编译链。一旦把 web-tree-sitter 作为依赖引入,只需将对应语言的 .wasm 文件放入 resources/grammars/ 目录,系统就能解析该语言——从支持 1 种语言到支持 11 种语言,只花了一个下午。
当然,这是一个 trade-off。以 Swift 为例,Tree-sitter 的 Swift grammar 无法像 SwiftSyntax 那样区分 protocol 继承列表中的父协议和关联类型约束;它也无法解析宏展开后的语法结构。但这些"精度损失"在 Alembic 的使用场景中是可接受的——系统的目标不是构建 IDE 级别的 100% 精确语义分析,而是为 AI 推理提供足够准确的结构化上下文。Tree-sitter 能告诉 AI"这个文件有一个 NetworkClient 类,继承了 BaseClient,包含 sendRequest 方法",这对 AI 理解架构和提取知识已经足够了。
这个决策可以总结为一条设计原则:在 AI 辅助场景中,覆盖广度比单点精度更有价值。一个覆盖 11 种语言、每种语言达到"够用"精度的解析系统,远比一个只覆盖 1 种语言、拥有编译器级精度的解析系统更有用——因为 AI 有能力弥补结构解析的缺失,但它无法凭空理解一种完全没有结构信息的语言。
Tree-sitter WASM 方案
为什么是 WASM 而非原生绑定
Tree-sitter 有两种 Node.js 绑定方式:NAPI 原生绑定和 WASM 绑定。NAPI 的性能更好(约快 2-3 倍),但它需要为每个平台(macOS arm64、macOS x64、Linux x64、Windows x64)编译原生二进制文件,并且 Node.js 大版本升级时需要重新编译。
Alembic 选择了 WASM 方案:
// lib/core/ast/parser-init.ts
export async function initParser() {
if (_initialized) { return; }
try {
const mod = await import('web-tree-sitter');
_namespace = mod.default || mod;
Parser = typeof _namespace === 'function' ? _namespace : _namespace.Parser;
await Parser.init();
_initialized = true;
} catch {
// web-tree-sitter 不可用时优雅降级
Parser = null;
_initialized = false;
}
}初始化采用延迟加载——只在第一次需要解析时才 import('web-tree-sitter')。Parser.init() 初始化 WASM 运行时,后续每种语言的 .wasm 文件按需加载。
语言加载也做了特殊处理——自行读取 .wasm 文件为 Uint8Array,绕过 ESM 模块系统下 __require("fs/promises") 的兼容问题:
export async function loadLanguageWasm(wasmFileName: any) {
if (!_initialized || !_namespace) { return null; }
const wasmPath = path.join(GRAMMARS_DIR, wasmFileName);
try {
const buffer = await readFile(wasmPath);
const Language = _namespace.Language || Parser.Language;
return await Language.load(new Uint8Array(buffer));
} catch {
return null;
}
}WASM 的优势:一次编译,所有平台一致运行。11 个 .wasm 文件(总计约 8MB)打包在 resources/grammars/ 目录,不需要 node-gyp,不需要 Python,不需要 C++ 编译器。用户 npm install 后即可运行,没有原生模块的平台兼容性噩梦。
语言注册表
系统维护一个静态的语言注册表,将 11 种语言映射到 WASM 文件和解析插件:
// lib/core/ast/index.ts
const LANG_REGISTRY = [
{ langId: 'swift', wasmFile: 'tree-sitter-swift.wasm', module: './lang-swift.js' },
{ langId: 'typescript', wasmFile: 'tree-sitter-typescript.wasm', module: './lang-typescript.js' },
{ langId: 'tsx', wasmFile: 'tree-sitter-tsx.wasm', module: './lang-typescript.js',
setFn: 'setTsxGrammar', pluginKey: 'tsxPlugin' },
{ langId: 'javascript', wasmFile: 'tree-sitter-javascript.wasm', module: './lang-javascript.js' },
{ langId: 'python', wasmFile: 'tree-sitter-python.wasm', module: './lang-python.js' },
{ langId: 'java', wasmFile: 'tree-sitter-java.wasm', module: './lang-java.js' },
{ langId: 'kotlin', wasmFile: 'tree-sitter-kotlin.wasm', module: './lang-kotlin.ts' },
{ langId: 'go', wasmFile: 'tree-sitter-go.wasm', module: './lang-go.js' },
{ langId: 'dart', wasmFile: 'tree-sitter-dart.wasm', module: './lang-dart.js' },
{ langId: 'rust', wasmFile: 'tree-sitter-rust.wasm', module: './lang-rust.js' },
{ langId: 'objectivec', wasmFile: 'tree-sitter-objc.wasm', module: './lang-objc.js' },
];注意 TypeScript 和 TSX 使用同一个解析插件但不同的 WASM grammar——TSX 需要一个专门的 grammar 来处理 JSX 语法节点。
统一抽象类型
AstFileSummary
每个语言解析器最终产出的都是同一个结构——AstFileSummary:
// lib/core/AstAnalyzer.ts
interface AstFileSummary {
lang: string; // 语言标识
classes: AstClassRecord[]; // 类/结构体
protocols: AstProtocolRecord[]; // 接口/协议
categories: AstCategoryRecord[]; // 扩展/分类
methods: AstMethodRecord[]; // 方法/函数
properties: AstPropertyRecord[]; // 属性/字段
patterns: AstPatternRecord[]; // 设计模式
imports: string[]; // 导入语句
exports: string[]; // 导出声明
callSites: CallSiteInfo[]; // 调用点(用于调用图)
references: AstReferenceRecord[]; // 类型引用
inheritanceGraph: InheritanceEdge[]; // 继承关系边
metrics: AstMetrics; // 复杂度指标
}这个结构覆盖了所有语言的共性概念:
| 抽象类型 | Swift | Java | Python | Go | Rust |
|---|---|---|---|---|---|
AstClassRecord | class/struct/enum | class/record/enum | class | struct | struct/enum |
AstProtocolRecord | protocol | interface | ABC | interface | trait |
AstCategoryRecord | extension | — | — | — | impl block |
AstMethodRecord | func | method | def | func/method | fn |
AstPropertyRecord | var/let | field | attribute | field | field |
统一类型的字段设计
interface AstClassRecord {
name: string;
superclass?: string; // Java extends / Swift : SuperClass
protocols?: string[]; // Java implements / Swift : Protocol
methodCount?: number;
line?: number;
file?: string;
}
interface AstMethodRecord {
name: string;
className?: string; // 所属类(顶级函数为空)
isClassMethod?: boolean; // 静态方法标记
bodyLines?: number; // 函数体行数
complexity?: number; // 圈复杂度估算
nestingDepth?: number; // 最大嵌套深度
}为什么 superclass 和 protocols 分开?因为 Swift 和 Kotlin 的继承列表中,第一个可能是父类也可能是接口——解析器需要用启发式规则判断:
// lang-swift.ts — 继承列表解析
let detectedSuper: any = null;
if (protocols.length > 0 && kind === 'class') {
const first = protocols[0];
// 不以 Protocol/Delegate/DataSource 结尾 → 可能是父类
if (!first.endsWith('Protocol') && !first.endsWith('Delegate') && !first.endsWith('DataSource')) {
detectedSuper = first;
}
}这是一个"最大努力"的启发式——它不能覆盖所有情况(比如一个叫 Animal 的协议),但在实践中覆盖了 95% 以上的 Swift 项目。
语言解析器
统一的分发入口
所有语言共享同一个分析入口——analyzeFile():
// lib/core/AstAnalyzer.ts
function analyzeFile(source: string, lang: string, options = {}): AstFileSummary | null {
const plugin = _langPlugins.get(lang);
if (!plugin) { return null; } // 无插件 → 优雅降级
const parser = _getParser(lang);
if (!parser) { return null; }
const tree = parser.parse(source);
const root = tree.rootNode;
const ctx: AstWalkerContext = {
classes: [], protocols: [], categories: [], methods: [],
properties: [], patterns: [], imports: [], exports: [],
callSites: [], references: [],
};
// 1. 分发到语言特定的 walker
plugin.walk(root, ctx);
// 2. 提取调用点
if (options.extractCallSites !== false) {
const extractor = plugin.extractCallSites || getCallSiteExtractor(lang) || defaultExtractCallSites;
extractor(root, ctx, lang);
}
// 3. 构建继承图
const inheritanceGraph = _buildInheritanceGraph(ctx.classes, ctx.protocols, ctx.categories);
// 4. 检测设计模式
const detectedPatterns = plugin.detectPatterns
? plugin.detectPatterns(root, lang, ctx.methods, ctx.properties, ctx.classes)
: _detectPatterns(root, lang, ctx.methods, ctx.properties, ctx.classes);
ctx.patterns.push(...detectedPatterns);
// 5. 计算度量指标
const metrics = _computeMetrics(root, lang, ctx.methods);
return { lang, classes: ctx.classes, protocols: ctx.protocols, ... };
}每个语言解析器只需实现 walk(root, ctx) 方法——遍历 Tree-sitter 的语法树节点,把发现的类、方法、属性等写入共享的 ctx 对象。解析器不需要关心调用图、设计模式、继承图——这些由上层统一处理。
三种代表性解析器
JavaScript/TypeScript — 处理 JSX、箭头函数和 class 语法:
// lang-javascript.ts
function _walkJSNode(node, ctx, parentClassName) {
for (let i = 0; i < node.namedChildCount; i++) {
const child = node.namedChild(i);
switch (child.type) {
case 'import_statement': { /* 提取导入路径 */ break; }
case 'class_declaration': {
const classInfo = _parseJSClass(child);
ctx.classes.push(classInfo);
_walkJSClassBody(body, ctx, classInfo.name);
break;
}
case 'function_declaration': {
ctx.methods.push(_parseJSFunction(child, parentClassName));
break;
}
case 'lexical_declaration':
case 'variable_declaration': {
// 箭头函数和 React Hooks:const useAuth = () => { ... }
_parseJSVariableDecl(child, ctx, parentClassName);
break;
}
}
}
}Swift — 处理 protocol、extension 和结构化导入:
// lang-swift.ts
function _walkSwiftNode(node, ctx, parentClassName) {
for (let i = 0; i < node.namedChildCount; i++) {
const child = node.namedChild(i);
switch (child.type) {
case 'protocol_declaration': {
ctx.protocols.push(_parseSwiftProtocol(child));
break;
}
case 'extension_declaration': {
const extInfo = _parseSwiftExtension(child);
ctx.categories.push(extInfo); // extension → 统一抽象为 category
_walkSwiftNode(body, ctx, extInfo.className);
break;
}
case 'property_declaration': {
ctx.properties.push(_parseSwiftProperty(child, parentClassName));
break;
}
}
}
}Swift 的 extension 被映射到统一类型的 categories(沿用 Objective-C 的 category 概念)——因为两者的语义一致:为已有类型添加新成员。
Python — 处理 decorator 和 dataclass 模式:
// lang-python.ts
function _walkPyNode(node, ctx, parentClassName) {
for (let i = 0; i < node.namedChildCount; i++) {
const child = node.namedChild(i);
switch (child.type) {
case 'decorated_definition': {
const actualDef = child.namedChildren.find(
(c) => c.type === 'class_definition' || c.type === 'function_definition'
);
const decorators = child.namedChildren
.filter((c) => c.type === 'decorator')
.map((d) => d.text);
if (actualDef?.type === 'class_definition') {
const classInfo = _parsePyClass(actualDef);
classInfo.decorators = decorators;
if (decorators.some((d) => d.includes('dataclass'))) {
classInfo.isDataclass = true; // @dataclass 标记
}
ctx.classes.push(classInfo);
}
break;
}
}
}
}Python 的 decorated_definition 是一个包含 decorator 和实际定义的复合节点——解析器需要先提取 decorator 列表,再递归到内部的 class/function 定义。
各语言的特有难点
| 语言 | 特有难点 | 处理策略 |
|---|---|---|
| Java | static import、annotation、record 类型 | 区分 import static 和普通 import,annotation 收集到 class 元数据 |
| Kotlin | 主构造器属性注入、companion object、sealed class | 从构造器参数提取属性(DI 模式),companion 方法归为类方法 |
| Go | receiver method、接口组合、type alias | 从 method_declaration 提取 receiver 类型,接口内嵌接口 |
| Rust | trait、impl 块、use 路径、derive 宏 | trait → protocol,impl → category,:: 路径解析 |
| Dart | mixin、extension、show/hide 导入 | mixin → 带 mixin 标记的 class,show 子句解析为命名导入 |
| Objective-C | category、@protocol、#import | category(ClassName) → extension 抽象 |
结构分析链
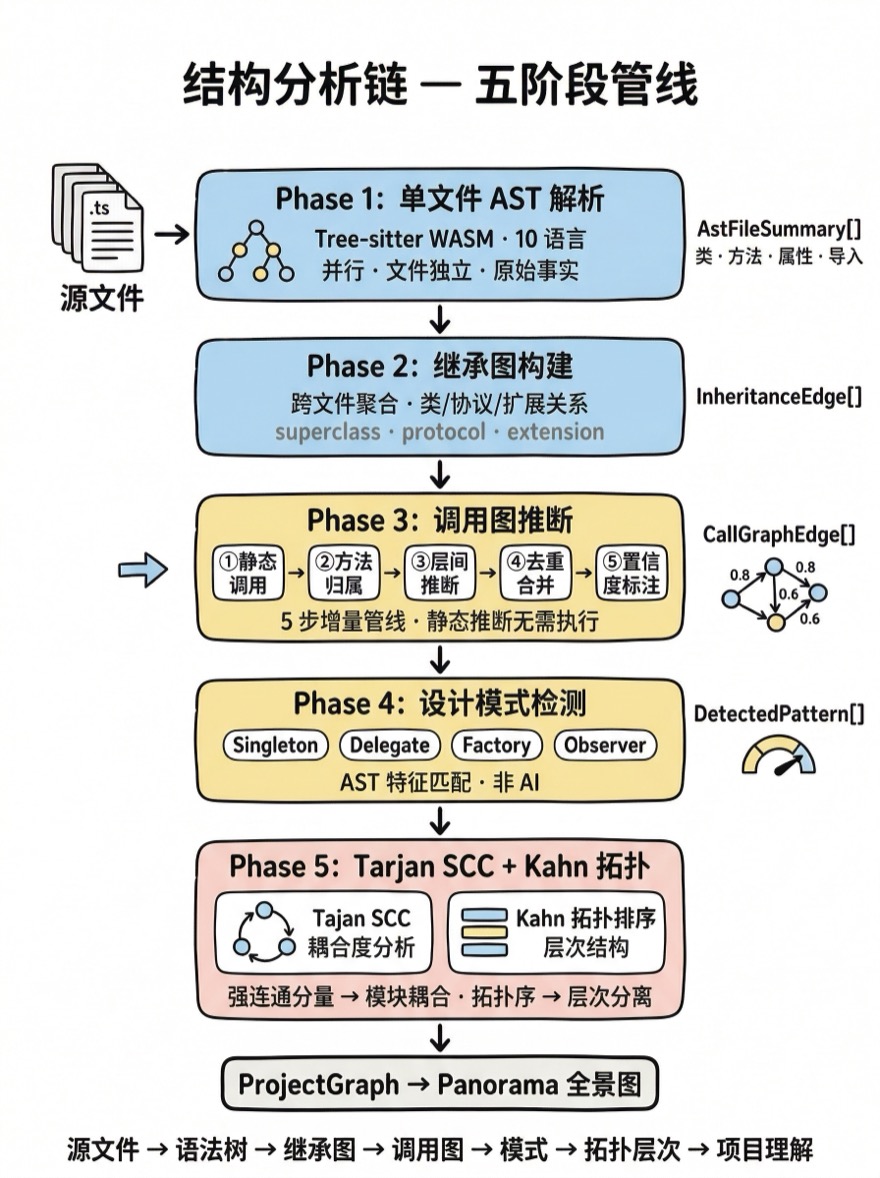
AST 解析只是第一步。单文件的语法树需要经过 5 个阶段的分析才能变成可用的项目理解:
源文件 → Phase 1: 单文件 AST 解析
→ Phase 2: 继承图构建
→ Phase 3: 调用图推断(5 步管线)
→ Phase 4: 设计模式检测
→ Phase 5: Tarjan SCC + Kahn 拓扑分层Phase 1: 单文件解析
对项目中的每个源文件执行 analyzeFile(),产出 AstFileSummary[]。解析是并行的——每个文件独立,不依赖其他文件的结果。这一步的输出是原始事实:这个文件有哪些类、方法、属性、导入。
Phase 2: 继承图构建
跨文件聚合所有类、协议和扩展的关系:
// lib/core/AstAnalyzer.ts
function _buildInheritanceGraph(classes, protocols, categories) {
const edges: InheritanceEdge[] = [];
for (const cls of classes) {
if (cls.superclass) {
edges.push({ from: cls.name, to: cls.superclass, type: 'inherits' });
}
for (const proto of cls.protocols || []) {
edges.push({ from: cls.name, to: proto, type: 'conforms' });
}
}
for (const proto of protocols) {
for (const parent of proto.inherits || []) {
edges.push({ from: proto.name, to: parent, type: 'inherits' });
}
}
for (const cat of categories) {
const className = cat.className || cat.targetClass;
edges.push({ from: `${className}(${cat.categoryName || cat.name})`, to: className, type: 'extends' });
}
return edges;
}三种边类型:inherits(类继承)、conforms(协议/接口遵循)、extends(扩展/分类)。这个图是后续模块拓扑分析的基础。
Phase 3: 调用图推断
调用图是最复杂的分析——从"A 文件的第 42 行调用了 doSomething()"到"A.foo() → B.doSomething()"需要解析导入路径、匹配符号表、推断 receiver 类型。
CallGraphAnalyzer 实现了 5 步管线:
// lib/core/analysis/CallGraphAnalyzer.ts
// Pipeline:
// 1. CallSiteExtractor — 从 AST 提取调用点(已在 Phase 1 完成)
// 2. SymbolTableBuilder — 构建全局符号表
// 3. ImportPathResolver — 导入路径解析
// 4. CallEdgeResolver — 调用点 → 调用边
// 5. DataFlowInferrer — 调用边 → 数据流边Step 2: 符号表——遍历所有文件的 AST 摘要,注册每个类、接口、方法的全限定名(file::Class.method),标记是否被导出:
// SymbolTableBuilder.ts
static build(projectSummary) {
const table = { declarations: new Map(), fileExports: new Map(), ... };
for (const fileSummary of projectSummary.fileSummaries) {
for (const cls of fileSummary.classes || []) {
const fqn = `${filePath}::${cls.name}`;
table.declarations.set(fqn, {
fqn, name: cls.name, file: filePath, kind: 'class',
isExported: _isExported(cls.name, exportNames),
});
}
// ... 同样注册 protocols、methods
}
return table;
}Step 4: 调用边解析——4 优先级匹配策略:
// CallEdgeResolver.ts — 4-priority resolution:
// 1. this.xxx() → 同类方法
// 2. ImportedType.method() → 基于导入路径
// 3. localFunc() → 同文件函数
// 4. globalSearch(name) → 全局唯一匹配(fallback)Step 5: 数据流推断——从调用边推导参数流向和返回值流向:
// DataFlowInferrer.ts
static infer(resolvedEdges) {
const dataFlowEdges = [];
for (const edge of resolvedEdges) {
// 正向:参数从 caller 流向 callee
if ((edge.argCount || 0) > 0) {
dataFlowEdges.push({ from: edge.caller, to: edge.callee, flowType: 'argument', direction: 'forward' });
}
// 反向:返回值从 callee 流向 caller
dataFlowEdges.push({ from: edge.callee, to: edge.caller, flowType: 'return-value', direction: 'backward', confidence: 0.3 });
}
return dataFlowEdges;
}返回值的 confidence: 0.3 表明这是低置信度推断——没有类型系统支持,我们只能假设返回值会被使用。
调用图分析支持增量模式——当只有少数文件变更时,analyzeIncremental() 只重新分析变更文件和它们的依赖方,配合超时机制避免大型项目分析阻塞:
async analyze(astProjectSummary, options = {}) {
const timeout = options.timeout || 15_000;
const deadline = Date.now() + timeout;
// 渐进式超时:逐文件检查,超时返回部分结果
return this._doAnalyze(astProjectSummary, maxCallSitesPerFile, deadline);
}Phase 4: 设计模式检测
在 AST 数据上应用启发式规则检测常见设计模式:
// lib/core/AstAnalyzer.ts
function _detectPatterns(root, lang, methods, properties, classes) {
const patterns: AstPatternRecord[] = [];
// Singleton — 静态 shared/instance/current 属性
for (const m of methods) {
if (m.isClassMethod && /^shared|^default|^instance$|^current$/.test(m.name)) {
patterns.push({ type: 'singleton', className: m.className, confidence: 0.9 });
}
}
// Delegate — 属性名包含 delegate + weak 修饰
for (const p of properties) {
if (/delegate/i.test(p.name)) {
patterns.push({ type: 'delegate', className: p.className, isWeakRef: (p.attributes || []).includes('weak'), confidence: 0.95 });
}
}
// Factory — 静态 make/create/from 方法
for (const m of methods) {
if (m.isClassMethod && /^make|^create|^new|^from/.test(m.name)) {
patterns.push({ type: 'factory', className: m.className, confidence: 0.8 });
}
}
// Observer — observe/subscribe/didChange 方法
for (const m of methods) {
if (/^observe|^addObserver|^subscribe|^didChange|^willChange/.test(m.name)) {
patterns.push({ type: 'observer', className: m.className, confidence: 0.7 });
}
}
return patterns;
}每个模式都带有 confidence 值——delegate 模式的置信度最高(0.95),因为 Cocoa 生态中属性名包含 delegate 几乎确定是委托模式。factory 略低(0.8),因为 createUser() 也可能不是工厂方法。
语言特定的解析器可以覆盖通用检测,添加更精确的规则。例如 Java 解析器检测 private constructor + static getInstance 组合来识别 Singleton,Spring 增强包检测 @RestController、@Service、@Repository 注解来识别 Spring 分层模式。
Phase 5: Tarjan SCC + Kahn 拓扑分层
当所有文件的分析结果聚合为模块级的依赖图后,两个经典图算法被用来分析架构健康度:
Tarjan 强连通分量——检测模块间的循环依赖:
// lib/service/panorama/CouplingAnalyzer.ts
#tarjanSCC(adjacency, allNodes) {
let index = 0;
const stack = [], onStack = new Set(), indices = new Map(), lowlinks = new Map();
const sccs = [];
const strongConnect = (v) => {
indices.set(v, index);
lowlinks.set(v, index);
index++;
stack.push(v);
onStack.add(v);
for (const w of (adjacency.get(v)?.keys() || [])) {
if (!indices.has(w)) {
strongConnect(w);
lowlinks.set(v, Math.min(lowlinks.get(v)!, lowlinks.get(w)!));
} else if (onStack.has(w)) {
lowlinks.set(v, Math.min(lowlinks.get(v)!, indices.get(w)!));
}
}
if (lowlinks.get(v) === indices.get(v)) {
const scc = [];
let w;
do { w = stack.pop()!; onStack.delete(w); scc.push(w); } while (w !== v);
sccs.push(scc);
}
};
for (const node of allNodes) {
if (!indices.has(node)) { strongConnect(node); }
}
// size > 1 的 SCC 就是循环依赖
return sccs.filter((scc) => scc.length > 1)
.map((cycle) => ({ cycle: cycle.reverse(), severity: cycle.length > 3 ? 'error' : 'warning' }));
}3 个模块的循环是 warning(可能是合理的双向依赖),4 个以上是 error(几乎一定是架构问题)。
Kahn 拓扑排序——从依赖图推断分层结构:
// lib/service/panorama/LayerInferrer.ts
// 1. 移除环边(已由 Tarjan 检测),构建 DAG
// 2. Kahn 算法拓扑排序
const queue = [];
for (const [mod, deg] of inDegree) {
if (deg === 0) { queue.push(mod); } // 入度为 0 → 源头节点
}
const order = [];
while (queue.length > 0) {
const node = queue.shift()!;
order.push(node);
for (const neighbor of adjacency.get(node) ?? []) {
const newDeg = (inDegree.get(neighbor) ?? 1) - 1;
inDegree.set(neighbor, newDeg);
if (newDeg === 0) { queue.push(neighbor); }
}
}
// 3. 最长路径法分配层级
// level(A) = max(level(dep) for dep in A 的依赖) + 1
// 无出度的模块 = Layer 0(底层)拓扑排序后,用"最长路径法"分配层级——一个模块的层级等于它所有依赖的最大层级加 1。这确保了"Controller 依赖 Service,Service 依赖 Repository"被正确分为三层,而不是把没有直接依赖关系的模块混在一起。
DiscovererRegistry:项目类型探测
在 AST 解析之前,系统需要回答一个更基本的问题:这是什么类型的项目?
置信度探测
DiscovererRegistry 收集所有注册的 Discoverer,每个 Discoverer 检查特定的标记文件并返回置信度:
// lib/core/discovery/DiscovererRegistry.ts
async detect(projectRoot: string) {
const results = await Promise.all(
this.#discoverers.map(async (d) => ({
discoverer: d,
result: await d.detect(projectRoot).catch(() => ({ match: false, confidence: 0 })),
}))
);
const matched = results
.filter((r) => r.result.match)
.sort((a, b) => b.result.confidence - a.result.confidence);
return matched.length > 0 ? matched[0].discoverer : this.#discoverers.find((d) => d.id === 'generic');
}以 NodeDiscoverer 为例,置信度的计算是累加的:
// NodeDiscoverer.ts
async detect(projectRoot) {
let confidence = 0;
if (existsSync(join(projectRoot, 'package.json'))) {
confidence = 0.9; // package.json → 90%
}
if (existsSync(join(projectRoot, 'tsconfig.json'))) {
confidence = Math.max(confidence, 0.9);
confidence += 0.05; // + tsconfig.json → 95%
}
if (existsSync(join(projectRoot, 'node_modules'))) {
confidence += 0.05; // + node_modules → 100%
}
// 检测到其他生态标记时压低置信度
if (existsSync(join(projectRoot, 'Gemfile'))) {
confidence *= 0.05; // Ruby 项目中可能有 package.json 只是前端工具
}
if (existsSync(join(projectRoot, 'Cargo.toml'))) {
if (!existsSync(join(projectRoot, 'tsconfig.json'))) {
confidence *= 0.05; // Rust 项目中可能有 package.json 只是 WASM 工具
} else {
confidence *= 0.5; // 两者都有 → 可能是混合项目
}
}
return { match: confidence > 0, confidence: Math.min(confidence, 1.0) };
}关键设计:竞争性降权。当一个 Node.js 项目根目录同时存在 Gemfile,NodeDiscoverer 会把自己的置信度乘以 0.05(几乎归零),因为这更可能是一个 Rails 项目碰巧有前端工具链。但如果同时存在 tsconfig.json,说明 TypeScript 是项目的一等公民,降幅减小到 0.5。
混合项目处理
detectAll() 返回所有匹配的 Discoverer(按置信度排序),支持混合项目:
async detectAll(projectRoot) {
const matched = results
.filter((r) => r.result.match)
.sort((a, b) => b.result.confidence - a.result.confidence);
// 用户偏好提升到首位
const preference = loadPreference(projectRoot);
if (preference?.userConfirmed) {
const prefIdx = matched.findIndex((m) => m.discoverer.id === preference.selectedDiscoverer);
if (prefIdx > 0) {
matched.unshift(matched.splice(prefIdx, 1)[0]);
}
}
return matched;
}analyzeConflict() 分析检测结果的冲突性——如果最高置信度的两个 Discoverer 分差小于 0.1,标记为 ambiguous: true,提示用户手动选择。选择结果被持久化,下次不再询问。
所有 Discoverer
| Discoverer | 标记文件 | 基础置信度 |
|---|---|---|
NodeDiscoverer | package.json, tsconfig.json | 0.9 - 0.95 |
JvmDiscoverer | build.gradle(.kts), pom.xml | 0.85 - 0.95 |
SpmDiscoverer | Package.swift, *.xcodeproj | 0.9 - 0.95 |
PythonDiscoverer | setup.py, pyproject.toml, requirements.txt | 0.85 - 0.9 |
GoDiscoverer | go.mod | 0.9 |
RustDiscoverer | Cargo.toml | 0.9 |
DartDiscoverer | pubspec.yaml | 0.9 |
GenericDiscoverer | 任何源码文件 | 0.3 - 0.5 |
框架增强包
项目类型确定后,系统进入更细粒度的分析——框架增强包(Enhancement Pack)。每个增强包针对特定框架,提供额外的分析维度、Guard 规则和模式检测。
增强包接口
// lib/core/enhancement/EnhancementPack.ts
export class EnhancementPack {
get id(): string;
get conditions(): { languages: string[]; frameworks?: string[] };
// 额外的 Bootstrap 扫描维度
getExtraDimensions(): ExtraDimension[];
// 额外的 Guard 检查规则
getGuardRules(): GuardRule[];
// 框架特定的设计模式检测
detectPatterns(astSummary): DetectedPattern[];
// SFC 预处理(Vue .vue → script 块)
preprocess(content: string): { content: string; lang?: string } | null;
}每个 ExtraDimension 定义了一个扫描指南——告诉 Bootstrap 服务在分析这个框架时应该关注什么:
{
id: 'hook-pattern-scan',
label: '自定義 Hook 分析',
guide: '自定义 Hook 提取(useXxx 函数 + 内部状态/副作用分析)、Hook 组合模式、Hook 依赖关系...',
tierHint: 2, // 优先级
knowledgeTypes: ['code-pattern'],
skillWorthy: true, // 可生成 Skill
dualOutput: true, // 同时生成 Recipe + Skill
}代表性增强包
React Enhancement — 4 个额外维度 + 模式检测:
// react-enhancement.ts
getExtraDimensions() {
return [
{ id: 'hook-pattern-scan', label: '自定義 Hook 分析' },
{ id: 'component-structure-scan', label: '组件结构约定' },
{ id: 'rsc-boundary-scan', label: 'Server/Client 边界分析' },
{ id: 'state-management-scan', label: '状态管理分析' },
];
}
getGuardRules() {
return [{
ruleId: 'react-no-direct-dom',
pattern: /document\.(getElementById|querySelector|getElementsBy)/,
message: '避免直接 DOM 操作,使用 React ref 或状态管理',
}];
}
detectPatterns(astSummary) {
// 检测自定义 Hook:以 use[A-Z] 开头的函数
for (const method of astSummary.methods || []) {
if (/^use[A-Z]/.test(method.name)) {
patterns.push({ type: 'custom-hook', methodName: method.name, confidence: 0.95 });
}
}
}Spring Enhancement — DI 拓扑 + API 分析 + 注解检测:
// spring-enhancement.ts
getGuardRules() {
return [{
ruleId: 'spring-field-injection',
pattern: /@Autowired\s+(?:private|protected)\s/,
message: '建议使用构造函数注入替代字段注入(@Autowired on field)',
}];
}
detectPatterns(astSummary) {
for (const cls of astSummary.classes || []) {
const annos = cls.annotations || [];
if (annos.some((a) => /@RestController/.test(a))) {
patterns.push({ type: 'spring-rest-controller', className: cls.name, confidence: 0.95 });
}
if (annos.some((a) => /@Service/.test(a))) {
patterns.push({ type: 'spring-service', className: cls.name, confidence: 0.95 });
}
}
}Vue Enhancement — Composable 分析 + Pinia Store 拓扑 + 安全规则:
// vue-enhancement.ts
getGuardRules() {
return [
{ ruleId: 'vue-no-v-html', pattern: /v-html/, message: '避免使用 v-html,存在 XSS 风险' },
{ ruleId: 'vue-composable-naming', pattern: /export\s+function\s+(?!use)[a-z]/,
message: 'Composable 函数建议以 use 前缀命名' },
];
}全部 17 个增强包
EnhancementRegistry 根据项目的语言和框架筛选适用的增强包:
// EnhancementRegistry.ts
resolve(primaryLang, detectedFrameworks = []) {
return this.#packs.filter((pack) => {
const langMatch = pack.conditions.languages.includes(primaryLang);
const fwMatch = !pack.conditions.frameworks
|| pack.conditions.frameworks.some((f) => detectedFrameworks.includes(f));
return langMatch && (pack.conditions.frameworks ? fwMatch : true);
});
}| 增强包 | 语言 | 框架 | 核心能力 |
|---|---|---|---|
| React | TS/JS | React, Next.js | Hook 分析、组件结构、RSC 边界、状态管理 |
| Vue | TS/JS | Vue, Nuxt | Composable 分析、Pinia Store、组件 API |
| Next.js | TS/JS | Next.js | App Router / Pages Router 约定 |
| Spring | Java/Kotlin | Spring | DI 拓扑、REST API、Entity |
| Django | Python | Django | Model-View-Template |
| FastAPI | Python | FastAPI | Pydantic 模型、依赖注入 |
| Rust Web | Rust | Rocket/Axum/Actix | Handler、Extractor、中间件 |
| Rust Tokio | Rust | Tokio | 异步运行时模式 |
| Go Web | Go | Gin/Echo | HTTP Handler、中间件链 |
| Go gRPC | Go | gRPC | Service 定义、Protobuf |
| Node Server | TS/JS | Express/Nest.js | 路由、中间件、Controller |
| Android | Java/Kotlin | Android SDK | Activity/Fragment 生命周期 |
| ML | Python | TensorFlow/PyTorch | 模型定义、训练循环 |
| LangChain | Python | LangChain | Agent/Chain/Tool 模式 |
| SwiftUI | Swift | SwiftUI | View 组件、@State/@Binding |
| UIKit | Swift | UIKit | ViewController 生命周期 |
| Flutter | Dart | Flutter | Widget 树、Provider |
从 AST 到 Panorama
所有分析最终汇入 Panorama——项目的架构全景。数据流转分为四个阶段:
Phase 1: ProjectGraph 构建
ProjectGraph.build() 收集所有源文件,逐一解析,建立类、协议、方法的索引:
// lib/core/ast/ProjectGraph.ts
static async build(projectRoot, options = {}) {
const files = collectSourceFiles(projectRoot, extensions, opts);
const graph = new ProjectGraph();
for (const filePath of files) {
if (opts.timeoutMs && Date.now() - startTime > opts.timeoutMs) { break; }
const content = fs.readFileSync(filePath, 'utf-8');
const lang = extToLang[path.extname(filePath)];
const summary = analyzeFile(content, lang);
if (summary) {
graph.#indexFileSummary(relativePath, summary);
}
}
graph.#buildReverseIndices();
return graph;
}超时保护确保大型项目(数万文件)不会阻塞——超时后返回已解析的部分结果。
Phase 2: PanoramaScanner 扫描
PanoramaScanner 调用 Bootstrap 的共享阶段函数,将 AST 结果写入数据库:
// lib/service/panorama/PanoramaScanner.ts
async scan() {
// Phase 1.0: 文件收集(最多 500 文件)
const phase1 = await runPhase1_FileCollection(projectRoot, logger, { maxFiles: 500 });
// Phase 1.5: AST 分析 → AstProjectSummary
const phase1_5 = await runPhase1_5_AstAnalysis(phase1.allFiles, phase1.langStats, logger);
// Phase 1.6: Entity Graph → code_entities 表
const phase1_6 = await runPhase1_6_EntityGraph(phase1_5.astProjectSummary, projectRoot, container, logger);
// Phase 1.7: Call Graph → knowledge_edges 表
await runPhase1_7_CallGraph(phase1_5.astProjectSummary, projectRoot, container, logger);
// Phase 2.0: Dependency Graph → 模块发现
const phase2 = await runPhase2_DependencyGraph(projectRoot, logger, { skipCallGraph: true });
return { entities, edges, modules, durationMs: Date.now() - t0 };
}ensureData() 是幂等的——如果数据库中已有该项目的实体数据,跳过扫描。扫描过一次后设置 #hasScanned 标志,同一会话不重复执行。
Phase 3: PanoramaAggregator 聚合
4 阶段聚合管线将原始数据转化为架构洞察:
// lib/service/panorama/PanoramaAggregator.ts
async compute(moduleCandidates, options) {
// Stage 1: RoleRefiner — 模块角色分类(Controller / Service / Utility / Entity)
const refinedRoles = await this.#roleRefiner.refineAll(moduleCandidates);
// Stage 2: CouplingAnalyzer — 依赖图分析(fan-in, fan-out, 循环)
const coupling = await this.#couplingAnalyzer.analyze(moduleFiles, externalModules);
// Stage 3: LayerInferrer — 从耦合数据推断分层(Presentation / Business / Data)
const layers = this.#layerInferrer.infer(coupling.edges, modules, coupling.cycles, { configLayers });
// Stage 4: PanoramaModule synthesis — 聚合角色 + 层级 + 知识覆盖率
const panoramaModules = new Map();
for (const mc of moduleCandidates) {
panoramaModules.set(mc.name, {
name: mc.name,
refinedRole: refined?.refinedRole, // Controller / Service / ...
layer: moduleLayerMap.get(mc.name), // Layer 0 / 1 / 2 / ...
fanIn: metrics?.fanIn, // 被依赖次数
fanOut: metrics?.fanOut, // 依赖他人次数
coverageRatio: recipeCount / fileCount, // 知识覆盖率
});
}
return { modules: panoramaModules, layers, projectRecipeCount, computedAt: Date.now() };
}Phase 4: 缓存与失效
PanoramaService 缓存计算结果,通过 SignalBus 监听信号标记失效:
// PanoramaService.ts
constructor(opts) {
if (this.#signalBus) {
// 当 guard/lifecycle/usage 信号触发时,缓存失效
this.#signalBus.subscribe('guard|lifecycle|usage', () => {
this.#cache = null;
});
}
}
async getOverview(): Promise<PanoramaOverview> {
const result = await this.#getOrCompute(); // 命中缓存或重新计算
const isStale = Date.now() - result.computedAt > STALE_THRESHOLD_MS;
return { moduleCount, layerCount, totalFiles, totalRecipes, overallCoverage, stale: isStale };
}缓存失效有两种触发:信号驱动(实时)和时间阈值(兜底)。当新的 Guard 命中或知识生命周期变化时,缓存立即清除;即使没有信号,超过阈值时间的缓存也会被标记为 stale。
权衡与替代方案
为什么不用 LSP
Language Server Protocol(LSP)提供了精确的语义分析——类型推断、跳转定义、查找引用。但 LSP 有三个问题:
- 重量级 — 每种语言需要启动一个 Language Server 进程(TypeScript 的 tsserver、Python 的 Pyright、Swift 的 sourcekit-lsp),内存占用数百 MB
- 依赖项目配置 — LSP 需要项目的构建配置(tsconfig.json 完整配置、build.gradle 依赖解析),无法在 setup 阶段运行
- 启动延迟 — Language Server 初始化需要数秒到数十秒
Alembic 的代码理解发生在 Bootstrap 阶段——这时系统可能还没有完整的项目配置。Tree-sitter 只需要源文件文本,不需要编译器、不需要依赖解析、不需要类型检查。它的精确度低于 LSP(没有类型信息),但足以提取结构信息和模式。
为什么不用正则
正则表达式无法可靠地解析编程语言:
# 正则无法区分这三种 class
class RealClass: # 真实的类定义
pass
"""class FakeClass:""" # 注释中的 class
def func():
class InnerClass: # 嵌套的类定义
passTree-sitter 生成的语法树准确区分这三种情况——class_definition 节点、string 节点、嵌套的 class_definition 节点。这对于复杂度估算、嵌套深度分析和调用图构建是必要的。
为什么不用 AI 直接分析代码
SOUL 约束中的确定性标记标注原则要求:确定性分析必须在 AI 介入之前完成。用 AI 分析 AST 结构有三个问题:
- 成本 — 一个 10 万行的项目有数千个文件,逐文件调用 LLM 的 API 费用和延迟不可接受
- 确定性 —
class Foo extends Bar是确定性事实,不应该有概率误差 - 速度 — Tree-sitter 解析一个文件 < 10ms,LLM 需要 1-5 秒
AI 的价值在更上层:从 AST 结果推断架构模式、生成知识描述、评估代码质量。这些需要"判断"的任务适合 AI,而结构提取不需要。
WASM 的已知限制
- 内存上限 — 单个 WASM 实例默认 256MB 内存,分析超大文件(> 10MB)可能触发 OOM
- Parser 质量参差 — 部分语言的 Tree-sitter grammar 维护不积极(如 Objective-C 的 grammar 对新语法支持滞后)
- 无语义信息 — WASM Tree-sitter 只有语法树,没有类型系统。
foo.bar()中foo的类型无法确定,调用图只能做"最大努力"推断
这些限制通过两个机制缓解:优雅降级(解析失败不阻塞)和框架增强包(用领域知识弥补语义信息缺失)。
小结
Alembic 的代码理解是一个从精确到模糊、从局部到全局的渐进过程:
- Tree-sitter WASM 提供跨平台一致的语法解析,11 种语言共享一套加载和缓存机制
- 统一抽象类型 (
AstFileSummary) 把语言差异封装在解析器内部,上层服务面对统一接口 - 10+ 语言解析器 各自处理语言特有的语法结构(protocol、decorator、impl、mixin),输出到统一的
ctx对象 - 5 阶段结构分析链 从单文件 AST → 继承图 → 调用图 → 模式检测 → 耦合分析,逐层叠加理解
- DiscovererRegistry 用置信度竞争机制自动识别项目类型,支持混合项目
- 17 个框架增强包 为特定框架添加分析维度、Guard 规则和模式检测
- Panorama 聚合 把所有分析结果汇聚为模块角色 + 分层拓扑 + 知识覆盖率的全景视图
系统的设计哲学是:确定的事情用确定的方法做。Tree-sitter 提取语法结构、Tarjan 检测循环依赖、Kahn 拓扑分层——这些都是算法可以精确解决的问题。把确定性分析做扎实,才能为上层的 AI 推理提供可靠的输入。
Part II 到此结束。我们已经看到的是系统的工程基石——架构如何分层(ch03)、安全如何纵深防御(ch04)、代码如何被理解(本章)。接下来进入 Part III — 知识领域:代码理解的结果如何被建模为统一实体、经历生命周期、并接受质量评估。