数据基础设施
SQLite + 向量混合持久化 · 自建 DI 容器 · 零外部依赖的工程选择。
问题场景
Alembic 是一个本地化工具,用户 npm install -g alembic 后就应该能用。这意味着不能依赖 PostgreSQL、Redis、Elasticsearch 等外部服务。但系统需要:关系型存储(知识条目 · 审计日志 · 14 张表)、向量存储(语义搜索 · HNSW 索引)、缓存(AST 图谱 · 搜索结果 · 跨进程失效)、事件总线(信号分发)、依赖注入(70+ 服务管理)。
核心约束:所有基础设施必须内嵌,npm install 即用——不能要求用户启动 Docker、安装 PostgreSQL 或配置 Redis。
这不是一个"简单的命令行工具"的基础设施需求。它的复杂度接近一个小型 SaaS 后端,但部署形态是一个 npm 包。本章展示 Alembic 如何在这个约束下构建完整的数据基础设施。
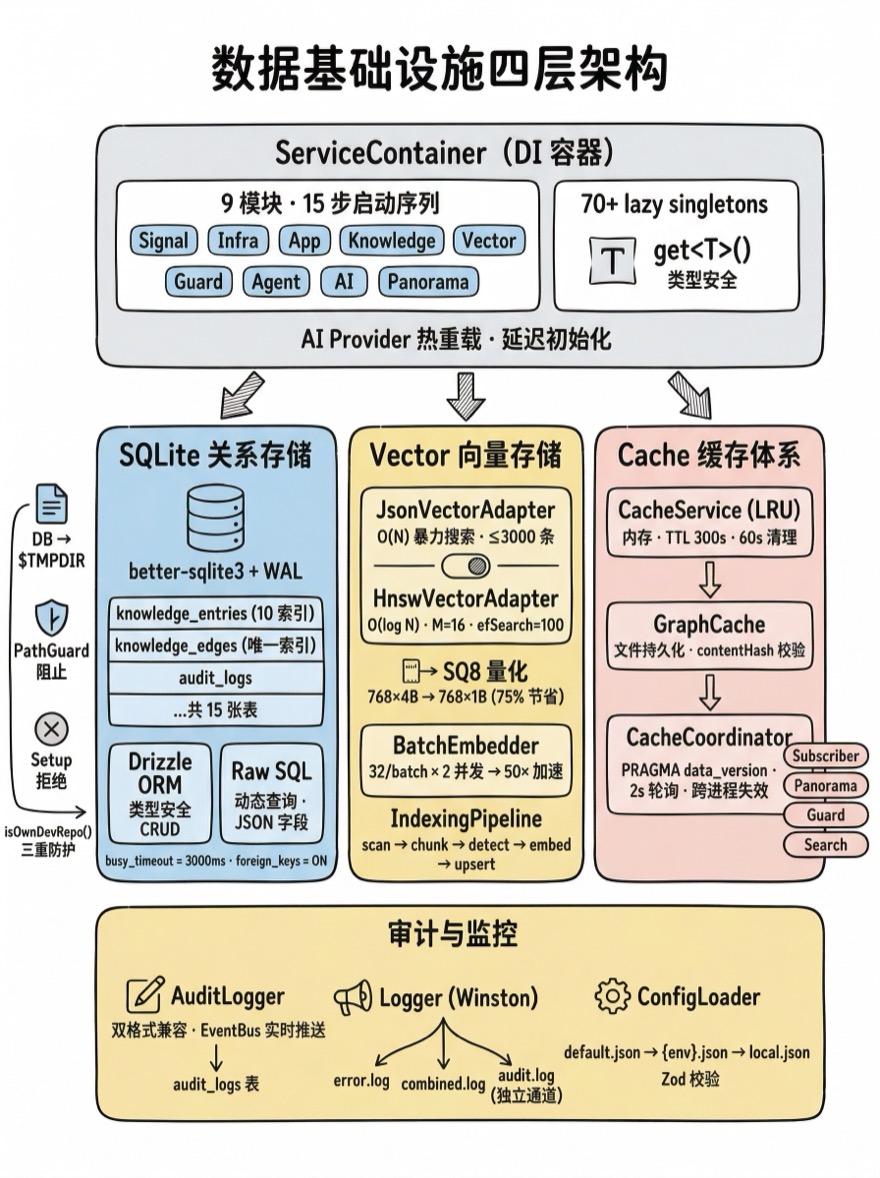
设计决策
SQLite 作为唯一关系存储
Alembic 需要存储带有复杂关系的结构化数据——知识条目之间有图谱关系,Guard 违规需要按文件路径和时间范围查询,Bootstrap 快照需要跨表关联维度和文件。这排除了纯 KV 存储(LevelDB、RocksDB)。
为什么不用 PostgreSQL?答案很简单:安装负担。一个 npm install -g alembic 命令不应该要求用户先装数据库服务器。SQLite 作为嵌入式数据库,二进制文件随 npm 包分发,零配置即可使用。
SQLite 的性能特征恰好匹配 Alembic 的工作负载——读多写少。知识库建立后,90% 的操作是搜索和查询;写入集中在 Bootstrap 扫描和 Agent 产出阶段。SQLite 的 WAL(Write-Ahead Logging)模式允许一个写者和多个读者并发执行,正好适合"MCP Server 持续读 + Agent 偶尔写"的场景。
具体的数据库引擎选择:better-sqlite3 而不是 sql.js。better-sqlite3 是 C++ 原生绑定,提供同步 API——这不是性能让步,而是刻意的工程选择。在 Node.js 中,SQLite 查询通常在微秒到毫秒级别完成,同步 API 消除了 Promise 开销,代码也更直观。sql.js 是 Wasm 编译版本,跨平台兼容好但性能明显更低。
Drizzle ORM + raw SQL 混用策略:
Alembic 没有采用纯 ORM 或纯 SQL 的极端方案,而是让两者各取所长:
// Drizzle:schema 定义 + 类型安全 CRUD
const entry = await db.select()
.from(knowledgeEntries)
.where(eq(knowledgeEntries.id, id));
// Raw SQL:复杂动态查询 + 性能关键路径
const results = db.prepare(`
SELECT ke.*, GROUP_CONCAT(edge.toId) as related
FROM knowledge_entries ke
LEFT JOIN knowledge_edges edge ON ke.id = edge.fromId
WHERE ke.lifecycle IN (?, ?)
GROUP BY ke.id
ORDER BY ke.stats_json->>'$.hitCount' DESC
LIMIT ?
`).all('active', 'evolving', 20);Drizzle 负责 schema 定义(编译期列名检查)、migration 管理和简单 CRUD。raw SQL 处理动态过滤、多表 JOIN 和 JSON 字段查询——这些场景下 ORM 的抽象反而是障碍。KnowledgeRepository 使用 _assertSafeColumn() 列名白名单验证,防止 raw SQL 的注入风险。
向量存储的双引擎策略
语义搜索需要向量索引。Alembic 提供两个引擎——JsonVectorAdapter 和 HnswVectorAdapter——通过统一的 VectorStore 抽象层切换:
// VectorStore 基类定义标准接口
async upsert(item: { id: string; content: string; vector: number[]; metadata })
async searchVector(queryVector: number[], options: { topK, filter, minScore })
async hybridSearch(queryVector, queryText, options)JsonVectorAdapter 是默认引擎——纯 JSON 文件存储,零额外依赖。适合中小规模知识库(≤ 3000 条),搜索采用暴力余弦相似度计算(O(N)),混合搜索时向量贡献 70%、关键词贡献 30%。优势是实现简单、调试方便——向量数据人类可读。
HnswVectorAdapter 是性能引擎——实现了完整的 HNSW(Hierarchical Navigable Small World)近似最近邻算法,搜索复杂度 O(log N)。当知识库增长到数千条以上时,暴力搜索的延迟会从毫秒级恶化到百毫秒级,HNSW 把它控制在个位数毫秒。
为什么不直接用 HNSW?因为它有初始化开销——索引在内存中构建,需要加载和序列化。对于 50 条知识的小项目,JsonAdapter 的启动时间近乎零,HNSW 反而更慢。
自建 DI 容器
Alembic 管理 70+ 服务的依赖关系。为什么不用 InversifyJS 或 TSyringe 这些成熟框架?
第一个原因是装饰器兼容性。InversifyJS 和 TSyringe 都依赖 TypeScript 装饰器和 reflect-metadata——这在 ESM 模块系统中有持续的兼容性问题。Alembic 是纯 ESM 项目("type": "module"),装饰器的转义行为在不同构建工具间不一致。
第二个原因是体积和控制权。InversifyJS 大约 10,000 行代码;Alembic 的 ServiceContainer 不到 200 行,却能覆盖实际需要的所有功能——延迟单例、模块化注册、AI Provider 热重载、类型安全的 get<T>()。没有装饰器魔法,没有运行时元数据反射,每个服务的注册和解析过程完全透明。
// 服务注册:工厂函数 + 延迟初始化
container.singleton('searchEngine', (c) =>
new SearchEngine(c.get('knowledgeRepository'), c.get('vectorStore'))
);
// 服务获取:TypeScript 类型安全
const engine = container.get<'searchEngine'>('searchEngine');
// 返回类型自动推断为 SearchEngineServiceContainer 唯一的"高级功能"是 AI Provider 热重载:用户在 Dashboard 切换 AI 模型时,标记了 aiDependent: true 的单例会被清除缓存,下次访问时用新 Provider 重建——无需重启 MCP Server。
架构与数据流
数据库 Schema——14 张表
Alembic 的 SQLite 数据库包含 14 张表,用 Drizzle ORM 定义 schema,编译期保证列名和类型的正确性。以下是核心表的设计:
知识存储(3 张表):
| 表 | 职责 | 关键字段 | 索引策略 |
|---|---|---|---|
knowledge_entries | 知识条目主表 | id · title · lifecycle · kind · knowledgeType · content(JSON) · stats(JSON) · trigger | 10 个索引——按 lifecycle、language、category、kind、createdAt、trigger、title 等 |
knowledge_edges | 知识关系图谱 | fromId · toId · relation · weight · metadata_json | 唯一索引 (fromId, toId, relation) 防重复 |
recipe_source_refs | 知识源引用 | recipeId · filePath · lineRange | 支持溯源查询 |
knowledge_entries 是系统中最重要的表。10 个索引看似激进,但每个都对应一个高频查询路径——按生命周期过滤(lifecycle = 'active')、按语言筛选、按触发器精确匹配等。写入集中在 Bootstrap 阶段,查询分散在 MCP 服务的整个生命周期,读优化的索引策略是正确的权衡。
content 和 stats 使用 JSON 字段存储。为什么不拆成独立列?因为这些字段的结构在知识类型之间差异很大——code-pattern 类型有 coreCode 和 headers,architecture 类型有 components 和 layers。JSON 字段避免了大量可空列,SQLite 的 json_extract() 和 ->> 操作符为 JSON 查询提供了足够的性能。
分析与审计(4 张表):
| 表 | 职责 | 关键设计 |
|---|---|---|
code_entities | AST 代码实体 | 组合唯一索引 (entityId, entityType, projectRoot) 支持多项目 |
guard_violations | Guard 检查记录 | violations 以 JSON 数组存储,按 filePath + triggeredAt 索引 |
audit_logs | 操作审计 | actor · action · resource · result · duration,独立日志通道 |
evolution_proposals | 进化提案 | 7 天 TTL,状态机流转 |
会话与记忆(3 张表):
| 表 | 职责 | 关键设计 |
|---|---|---|
sessions | 会话管理 | scope + scopeId 分区,expiredAt 自动过期 |
semantic_memories | Agent 语义记忆 | type(fact/insight/preference) · importance 评分 · 30 天归档 · 90 天遗忘 |
bootstrap_snapshots + bootstrap_dim_files | Bootstrap 快照 | 父子关系——快照关联维度-文件映射 |
运行时支撑(2 张表):
| 表 | 职责 |
|---|---|
token_usage | AI Token 消耗追踪——provider · model · inputTokens · outputTokens |
remote_commands | 远程指令队列——飞书等外部渠道的命令入队/执行 |
Migration 策略
数据库迁移在 DatabaseConnection.connect() 时自动执行。系统支持三种迁移文件格式——.sql、.js、.ts——通过 schema_migrations 表追踪已应用版本。每次迁移在事务中执行,保证原子性:要么全部成功,要么回滚到迁移前状态。
迁移的设计原则是向后兼容:新增列使用 DEFAULT 值,不会删除已有列。这保证了旧版本产生的数据库文件在新版本中依然可用——用户升级 Alembic 版本后不需要重建知识库。
向量索引体系
向量存储承载语义搜索的基础能力。Alembic 实现了完整的向量索引管线——从文本分块到向量生成,再到索引构建和查询。
HNSW 索引
HNSW 是近似最近邻搜索的主流算法。Alembic 的实现遵循原始论文的参数约定:
M = 16 # 每层最大邻居数
M0 = 32 # L0 层最大邻居数 (2 × M)
efConstruct = 200 # 构建时搜索宽度
efSearch = 100 # 查询时搜索宽度
mL = 1/ln(M) ≈ 0.72 # 层级采样因子为什么这些参数值? M=16 是准确率和内存的平衡点——更大的 M 提高召回但增加每个节点的存储开销。efConstruct=200 高于常见的 128 默认值,因为知识库的索引构建是离线操作(Bootstrap 阶段),多花一些构建时间换取更高质量的图结构是值得的。efSearch=100 在查询时提供 >95% 的召回率,且延迟保持在个位数毫秒。
SQ8 标量量化
当文档数超过 3000 时,HNSW 自动启用 SQ8 标量量化——把 32 位浮点向量压缩为 8 位整数:
量化:q_i = round((v_i - min_i) / (max_i - min_i) × 255)
反量化:v̂_i = q_i / 255 × (max_i - min_i) + min_iper-dimension 线性映射——每个维度独立统计最小值和最大值,然后线性映射到 [0, 255]。对于 768 维的 Embedding 向量,内存从 3072 字节降到 768 字节——75% 节省,而召回率损失小于 5%。
实际的搜索流程采用粗排 + 精排两阶段:先用量化向量快速筛选候选集(速度更快),再用原始向量对候选集精确计算(准确率更高)。
BatchEmbedder——50× 加速
向量生成的性能瓶颈不在本地计算,而在 Embedding API 的网络延迟。串行处理 100 个文本块(每次 300ms)需要 30 秒;BatchEmbedder 把它们分成每批 32 个,2 个批次并行,总耗时降到约 600ms——50 倍加速。
// BatchEmbedder 并发策略
batchSize = 32 // 每批文本数
maxConcurrency = 2 // 最多 2 个批次并行(p-limit 背压控制)为什么不用更高的并发?因为 Embedding API(OpenAI、Google、DashScope 等)都有速率限制。2 个并发批次在不触发限流的前提下最大化吞吐量。
IndexingPipeline——完整管线
索引构建的完整流程:scan → chunk → detect → embed → upsert。
1. 扫描:遍历 recipes/ 目录,收集 .md/.swift/.ts 等 14 种扩展名
2. 分块:Chunker v2 自动选择策略(AST / section / fixed)
- maxChunkTokens = 512, overlapTokens = 50
3. 增量检测:SHA256 前 16 字符作为 sourceHash,跳过未变化的文档
4. 批量向量生成:BatchEmbedder 批处理
5. 批量写入:VectorStore.batchUpsert()增量检测是关键优化——用户修改一条知识后执行 asd embed,只有该条知识会重新生成向量,其余跳过。这把重复索引的时间从分钟级降到秒级。
缓存体系——三层协作
Alembic 的缓存体系由三个组件构成,分别解决不同层次的问题:
CacheService——内存 LRU 缓存,处理热数据。默认 TTL 300 秒,每 60 秒自动清理过期项(定时器使用 unref() 不阻塞进程退出)。通过 CacheKeyBuilder 生成类型化的键(candidate:{id}、recipe:{id}、health:status),避免键冲突。
GraphCache——文件持久化缓存,处理重型计算结果。AST 图谱分析耗时较长(大项目可达数秒),结果序列化为 JSON 保存在 .asd/cache/ 目录下。每次读取时对比 contentHash——文件内容没变就复用缓存,变了就失效重算。
CacheCoordinator——跨进程缓存失效,处理多进程一致性。这是最有趣的组件。
Alembic 可能同时运行多个进程——MCP Server 在后台持续服务 IDE 请求,用户在终端执行 asd guard 命令。两个进程共享同一个 SQLite 数据库文件,但内存缓存各自独立。当 CLI 进程写入新的 Guard 规则后,MCP Server 的缓存不知道数据库已经变了。
CacheCoordinator 利用 SQLite 内置的 PRAGMA data_version 解决这个问题:
// data_version 是连接级别的计数器
// 当其他连接提交写事务后,当前连接的 data_version 会递增
const currentVersion = db.pragma('data_version', { simple: true });
if (currentVersion !== lastKnownVersion) {
// 数据库被其他进程修改了——通知所有订阅者失效缓存
subscribers.forEach(handler => handler());
lastKnownVersion = currentVersion;
}轮询间隔 2 秒,单次 PRAGMA 读取开销小于 0.01ms——近乎零成本的跨进程同步。订阅者包括 PanoramaService(模块图缓存)、GuardCheckEngine(规则缓存)和 SearchEngine(搜索索引)。
CacheCoordinator 仅在长驻进程中启动(HTTP Server / MCP Server),CLI 命令这种执行完就退出的进程不需要轮询。
审计与日志
Alembic 的审计系统分为两层——AuditLogger 负责记录,AuditStore 负责持久化和查询。
AuditLogger 兼容两种日志格式。Gateway 调用链产出 { actor, action, resource, result, duration } 结构,Service 层产出 { actor, action, resourceType, resourceId, details } 结构——AuditLogger 统一适配后写入 audit_logs 表,同时通过 EventBus 发送 audit:entry 事件推送到 Dashboard 实时展示。
interface AuditEntry {
id: string; // 请求 ID(可追踪完整调用链)
timestamp: number;
actor: string; // 执行者(agent · user · system)
action: string; // 操作类型(create · update · search · guard)
resource: string; // 资源标识
result: 'success' | 'failure';
duration: number; // 毫秒
}AuditStore 提供多维度查询——按时间范围、按执行者、按操作类型、按结果状态——以及统计聚合(成功率、平均耗时、按 Actor 分布)。审计日志写入独立的 audit.log 文件,不受 LOG_LEVEL 影响——即使把日志级别设为 error,审计记录依然完整保留。这是业务关键数据,不能被日志级别裁切。
日志系统基于 Winston,使用两种传输层。Console 传输在非 MCP 模式下启用(MCP 模式下 Console 输出会污染 JSON-RPC 协议流),使用 ANSI 亮色变体保证深色终端可读。File 传输写入三个独立文件——error.log(只记错误)、combined.log(全量日志)和 audit.log(审计专用)。
配置管理使用 ConfigLoader 静态类,三级覆盖链 default.json → {env}.json → local.json——后者覆盖前者。配置加载后经过 Zod schema 运行时校验(非阻塞,只发出告警),防止错误配置在运行时引发难以定位的问题。
核心实现
DatabaseConnection
DatabaseConnection 是整个数据层的入口——管理唯一的 SQLite 连接,执行迁移,配置运行时参数。
class DatabaseConnection {
connect(): Promise<SqliteDatabase> {
// 1. 开发仓库保护
if (isAlembicDevRepo(projectRoot)) {
dbPath = path.join(os.tmpdir(), 'alembic-dev', 'data.db');
}
// 2. 打开连接 + 运行时配置
const db = new Database(dbPath);
db.pragma('journal_mode = WAL'); // 写前日志
db.pragma('foreign_keys = ON'); // 外键约束
db.pragma('busy_timeout = 3000'); // 写锁等待 3 秒
// 3. 初始化 Drizzle ORM
this.drizzle = initDrizzle(db);
// 4. 自动迁移
await this.runMigrations();
return db;
}
}三个 PRAGMA 配置值得解释:
journal_mode = WAL:允许读写并发——一个写者 + 多个读者同时操作。传统的 rollback journal 模式下,写操作会阻塞所有读操作。foreign_keys = ON:SQLite 默认不启用外键约束(历史原因)。Alembic 的knowledge_edges表引用knowledge_entries.id,没有这个配置,删除知识条目不会级联清理关系边。busy_timeout = 3000:当另一个进程持有写锁时,不立即返回SQLITE_BUSY错误,而是等待最多 3 秒。这避免了 MCP Server 和 CLI 同时写入时的频繁失败。
开发仓库保护是一个精巧的防护机制:isAlembicDevRepo() 检测当前项目是否是 Alembic 源码仓库本身。如果是,数据库文件重定向到 $TMPDIR/alembic-dev/——防止开发和测试期间的 MCP Server 在源码仓库中产生运行时数据。这个检测配合 PathGuard(阻止创建 .asd/ 目录)和 SetupService(拒绝执行 setup),形成三重保护。
ServiceContainer 启动序列
ServiceContainer 的初始化是一个精心编排的启动序列——9 个模块按严格顺序注册,因为模块之间有依赖关系:
① Bootstrap 组件注入(database · auditLogger · gateway)
② AiModule.initialize() → AI Provider 初始化
③ InfraModule.register() → 数据库 · 缓存 · 日志 · 8+ 仓储
④ SignalModule.register() → 信号总线(预热确保单例就绪)
⑤ AppModule.register() → 配置 · 通用服务
⑥ KnowledgeModule.register() → 知识 CRUD
⑦ VectorModule.register() → 向量索引
⑧ GuardModule.register() → 合规检查
⑨ AgentModule.register() → Agent 工厂 · 工具注册表
⑩ AiModule.register() → AI 轮询
⑪ PanoramaModule.register() → 全景分析(依赖所有上层)
⑫ initEnhancementRegistry() → 异步加载框架增强包
⑬ VectorModule.initializeVectorService() → 绑定事件
⑭ KnowledgeModule.initializeKnowledgeServices()
⑮ 初始化 CacheCoordinator为什么是 15 步而不是 9 步?因为某些模块的注册和初始化需要分离——VectorModule 的服务注册在第 ⑦ 步,但事件监听绑定在第 ⑬ 步。事件监听依赖 SignalBus 和 KnowledgeService,而这些在注册时可能还不存在。分离注册和初始化避免了循环依赖。
SignalModule 优先注册并预热(步骤 ④)——因为 SignalBus 是信号系统的底层总线,后续几乎所有模块都需要通过它发送或接收信号。如果 SignalBus 在 AgentModule 注册时还不是单例,会导致多个模块持有不同的 Bus 实例,信号不互通。
// ServiceContainer 核心机制
class ServiceContainer {
private services: Record<string, () => unknown> = {}; // 工厂注册表
private singletons: Record<string, unknown> = {}; // 单例缓存
singleton(name: string, factory: (c: this) => unknown,
options?: { aiDependent?: boolean }) {
this.services[name] = () => {
if (!this.singletons[name]) {
this.singletons[name] = factory(this);
}
return this.singletons[name];
};
if (options?.aiDependent) {
this._aiDependentSingletons.push(name);
}
}
get<K extends keyof ServiceMap>(name: K): ServiceMap[K] {
const factory = this.services[name as string];
if (!factory) { throw new Error(`Service not found: ${String(name)}`); }
return factory() as ServiceMap[K];
}
}延迟单例是关键设计——工厂函数在注册时不执行,首次 get() 时才创建实例。这意味着启动时间只包含模块注册(微秒级),实际服务构建推迟到第一次使用。对于 MCP Server 场景,某些服务(如 PanoramaService)可能在整个会话中都不会被调用,延迟初始化避免了浪费。
AI Provider 热重载是 ServiceContainer 唯一的"动态"能力:
reloadAiProvider(newProvider) {
// 清除所有标记为 aiDependent 的单例缓存
for (const name of this._aiDependentSingletons) {
delete this.singletons[name];
}
// 下次 get() 时用新 Provider 重建
}用户在 Dashboard 切换 AI 模型后,AgentFactory、SearchEngine 等依赖 AI 的服务会在下次请求时自动用新配置重建——无需重启进程。
ServiceMap 类型安全
70+ 服务的类型安全依赖 ServiceMap 接口——一个 TypeScript 映射,把字符串键绑定到具体的服务类型:
export interface ServiceMap {
database: DatabaseConnection;
logger: Logger;
knowledgeRepository: KnowledgeRepositoryImpl;
searchEngine: SearchEngine;
vectorStore: VectorStore;
guardCheckEngine: GuardCheckEngine;
agentFactory: AgentFactory;
toolRegistry: ToolRegistry;
// ... 60+ 更多服务
}这消除了传统 DI 容器的类型断言问题——container.get('searchEngine') 的返回类型在编译期就确定为 SearchEngine,IDE 自动补全和重构完全可用。新增服务时只需在 ServiceMap 中添加一行类型声明,TypeScript 编译器会自动检查所有使用点。
AiProviderManager — 统一 AI 管理器
前文提到 ServiceContainer 的 reloadAiProvider() 可以热重载 AI Provider。实际上,热重载的完整实现由 AiProviderManager 承担——它是当前 AI Provider 的唯一权威管理入口,所有 Provider 读取和切换操作集中在此,消除了散落在各模块的 name === 'mock' 判断。
// lib/external/ai/AiProviderManager.ts
class AiProviderManager {
#provider: ManagedAiProvider; // 当前主 Provider
#embedProvider: ManagedAiProvider | null; // Embedding 备选
#tokenRecorder: TokenRecorder | null; // Token 追踪器
#listeners: Set<SwitchListener>; // 切换监听器
get isMock(): boolean; // 是否 Mock 模式
get isReady(): boolean; // 是否可用于 AI 操作
get info(): ProviderInfo; // 结构化信息快照
switchProvider(newProvider): SwitchResult; // 热切换
}热切换管线(switchProvider())是一个原子操作,6 步顺序执行:
| 步骤 | 操作 | 说明 |
|---|---|---|
| 1 | 替换核心引用 | #provider = newProvider |
| 2 | Token AOP 重新挂载 | _onTokenUsage 回调绑定到新 Provider |
| 3 | Embedding Fallback 重建 | 如果新 Provider 不支持 Embedding,尝试创建独立的 Embed Provider |
| 4 | DI 数据管道同步 | 将新 Provider 引用写入 ServiceContainer 的 singletons |
| 5 | DI 级联清除 | 清除所有标记 aiDependent: true 的 singleton 缓存 |
| 6 | 监听器通知 | 回调所有 SwitchListener(Realtime 广播、SearchEngine 重建等) |
步骤 2 的 Token AOP(Aspect-Oriented Programming)是一个精巧的设计:每个 AI Provider 实例有一个 _onTokenUsage 回调属性,在 chat() / chatWithTools() 执行后自动触发。Manager 在切换 Provider 时重新安装这个回调,指向当前的 TokenRecorder——调用者无需关心 Token 追踪的存在,它作为切面透明地附着在每次 AI 调用上。
// AOP Token 追踪 — 透明挂载
#wireTokenTracking(): void {
this.#provider._onTokenUsage = (usage) => {
this.#tokenRecorder?.record({
source: usage.source || 'provider',
provider: this.#provider.name,
model: this.#provider.model,
inputTokens: usage.inputTokens || 0,
outputTokens: usage.outputTokens || 0,
});
};
}MockProvider 不是简单的空操作——它实现了 9 种现实场景的模拟响应(scan、search、chat、structured output 等),让 Dashboard 和集成测试在没有 AI 密钥的环境下也能完整运行。用户在 Dashboard 切换到 Mock 模式后,所有 AI 依赖的服务(AgentFactory、SearchEngine 等)通过 DI 级联清除自动用 MockProvider 重建。
三层依赖注入绑定避免了 AiProviderManager 与 ServiceContainer 之间的循环依赖:
| 绑定 | 回调来源 | 用途 |
|---|---|---|
_bindDependentClearer | ServiceContainer | 切换时清除 AI 依赖 singleton |
_bindEmbedFallbackInit | AiModule | 初始化 Embedding 备选 Provider |
_bindDiSync | AiModule | 将 Provider 引用同步到 DI singletons |
Token Metering — 用量追踪
AI API 调用是 Alembic 运行中唯一有真实成本的操作。TokenUsageStore 追踪每次 AI 调用的 Token 消耗,提供 7 天维度的聚合分析。
数据模型:
// token_usage 表
{
timestamp: number; // 调用时间
source: string; // 调用场景(bootstrap · chat · guard · search)
dimension: string; // Bootstrap 维度(如 "networking")
provider: string; // AI 提供商(openai · google · anthropic)
model: string; // 具体模型
inputTokens: number;
outputTokens: number;
totalTokens: number;
durationMs: number;
toolCalls: number; // 工具调用次数
sessionId: string;
}聚合查询提供三种 7 天视图:
| 查询 | 维度 | 用途 |
|---|---|---|
getLast7DaysDaily() | 按日期分组 | Dashboard Token 消耗趋势图 |
getLast7DaysBySource() | 按 source 分组 | 识别哪个场景消耗最多 Token |
getLast7DaysSummary() | 全局汇总 | 总消耗 + 平均每次调用消耗 |
容量治理:MAX_ROWS = 10000,每次写入有 1% 概率触发裁剪(保留最新 10000 条按时间排序)。概率触发而非每次检查是为了摊销 DELETE 操作的开销——大部分写入零额外成本。
Developer Identity(developer-identity.ts)标识 Token 消耗的归属人:
优先链:AUTOSNIPPET_USER 环境变量 → git config user.name → os.userInfo().username → 'unknown'这个优先链确保在 CI 环境(ENV 优先)、本地开发(git 优先)和极端场景(OS fallback)下都能正确标识。结果在进程级别缓存——不会每次 AI 调用都 spawn git config。
KnowledgeRepository——混合查询
KnowledgeRepository 是仓储层的核心——知识条目的 CRUD 和复杂查询全部经过它。
简单操作使用 Drizzle:
async findById(id: string): Promise<KnowledgeEntry | null> {
const row = await this.db.select()
.from(knowledgeEntries)
.where(eq(knowledgeEntries.id, id))
.limit(1);
return row[0] ? this._rowToEntity(row[0]) : null;
}复杂查询保留 raw SQL——动态过滤条件(可能按 lifecycle、language、category、kind 的任意组合筛选)和 JSON 字段查询(按命中次数排序 stats_json->>'$.hitCount')在 ORM 中难以优雅表达:
async findWithPagination(filters, options) {
let sql = 'SELECT * FROM knowledge_entries WHERE 1=1';
const params: unknown[] = [];
if (filters.lifecycle) {
sql += ' AND lifecycle = ?';
params.push(filters.lifecycle);
}
if (filters._search) {
sql += ' AND (title LIKE ? OR content LIKE ?)';
params.push(`%${filters._search}%`, `%${filters._search}%`);
}
// 列名白名单验证防注入
this._assertSafeColumn(options.orderBy);
sql += ` ORDER BY ${options.orderBy} ${options.order}`;
// ...
}_assertSafeColumn() 维护一份允许的列名白名单。动态 ORDER BY 无法参数化(SQL 参数只能用于值,不能用于标识符),白名单是防止 SQL 注入的标准做法。
权衡与替代方案
SQLite 的并发限制
SQLite WAL 模式允许并发读,但写操作仍然是串行的——同一时刻只有一个写者。busy_timeout = 3000 缓解了短时间的写冲突,但如果多个进程持续高频写入,3 秒等待仍可能超时。
这对 Alembic 来说不是实际问题。写入场景集中在两个时刻:Bootstrap 扫描(单进程批量写入)和 Agent 产出(偶发写入)。日常使用中,MCP Server 几乎只做读操作——搜索知识库、获取 Guard 规则、读取配置——写入频率极低。
如果未来需要更高的写并发(例如多个 Agent 同时产出知识),可以考虑写队列——把写操作序列化到一个队列中,由单个 writer 进程消费。但当前阶段,3 秒超时足够了。
JSON 向量存储的规模上限
JsonVectorAdapter 的暴力搜索在 3000 条以上会出现可感知的延迟(>100ms)。HNSW 索引把这个上限推到了数万条。但对于超大规模知识库(10 万+),纯内存的 HNSW 索引会占用大量 RAM。
VectorStore 抽象层预留了扩展点——可以接入外部向量数据库(如 Milvus、Qdrant)。但"零外部依赖"是 Alembic 的核心承诺,所以外部引擎只作为可选的高级配置,不是默认路径。
自建 DI 的取舍
自建 ServiceContainer 的好处在前面已经讨论——轻量、无装饰器、类型安全。代价是:没有自动依赖解析。每个模块的注册顺序需要手动维护——如果 GuardModule 依赖 KnowledgeModule,就必须确保 KnowledgeModule 先注册。15 步启动序列的顺序是人工确定的,新增模块需要开发者理解依赖关系图。
InversifyJS 这类框架可以自动解析依赖顺序(基于装饰器声明),但代价是运行时反射和装饰器兼容问题。对于 Alembic 当前 9 个模块的规模,手动排序的维护成本完全可接受。如果模块数增长到 20 以上,可能需要在 ServiceContainer 中加入拓扑排序。
Drizzle vs Prisma
Drizzle 和 Prisma 是 TypeScript 生态中两个主流 ORM。Alembic 选择 Drizzle 的原因:
- 运行时零依赖:Drizzle 是纯 TypeScript,不需要生成代理文件(Prisma Client 需要
npx prisma generate) - SQL 亲和:Drizzle 的查询构建器几乎 1:1 映射 SQL 语法,不引入新的查询语言
- SQLite 原生支持:Drizzle 对 better-sqlite3 的同步 API 有一等支持,Prisma 只支持异步
代价是 Drizzle 的 migration 工具不如 Prisma 成熟,复杂的 schema 变更需要手写 SQL migration 文件。
小结
Alembic 在"npm 包"的部署约束下构建了一套完整的数据基础设施:
- SQLite + WAL 提供关系存储,14 张表覆盖知识、分析、审计、会话四个领域
- HNSW + SQ8 量化 提供高性能向量搜索,BatchEmbedder 50× 加速索引构建
- 三层缓存(内存 LRU · 文件持久化 · 跨进程协调)覆盖不同时效需求
- 自建 DI 容器 管理 70+ 服务的延迟初始化和 AI Provider 热重载
- Drizzle + raw SQL 混用 在类型安全和查询灵活性之间取得平衡
这些选择的共同原则是:内嵌优先——每个组件都不依赖外部进程。SQLite 替代 PostgreSQL,HNSW 替代 Elasticsearch,内存 LRU 替代 Redis,自建 DI 替代装饰器框架。代价是每个方向的能力天花板都低于专用方案,但对于知识库规模在万条以内的典型项目,这些天花板远未触及。
下一章我们将看到这些基础设施如何为上层的 MCP 协议和六通道交付系统提供支撑——知识从 SQLite 表到 IDE 规则文件的完整链路。
下一章