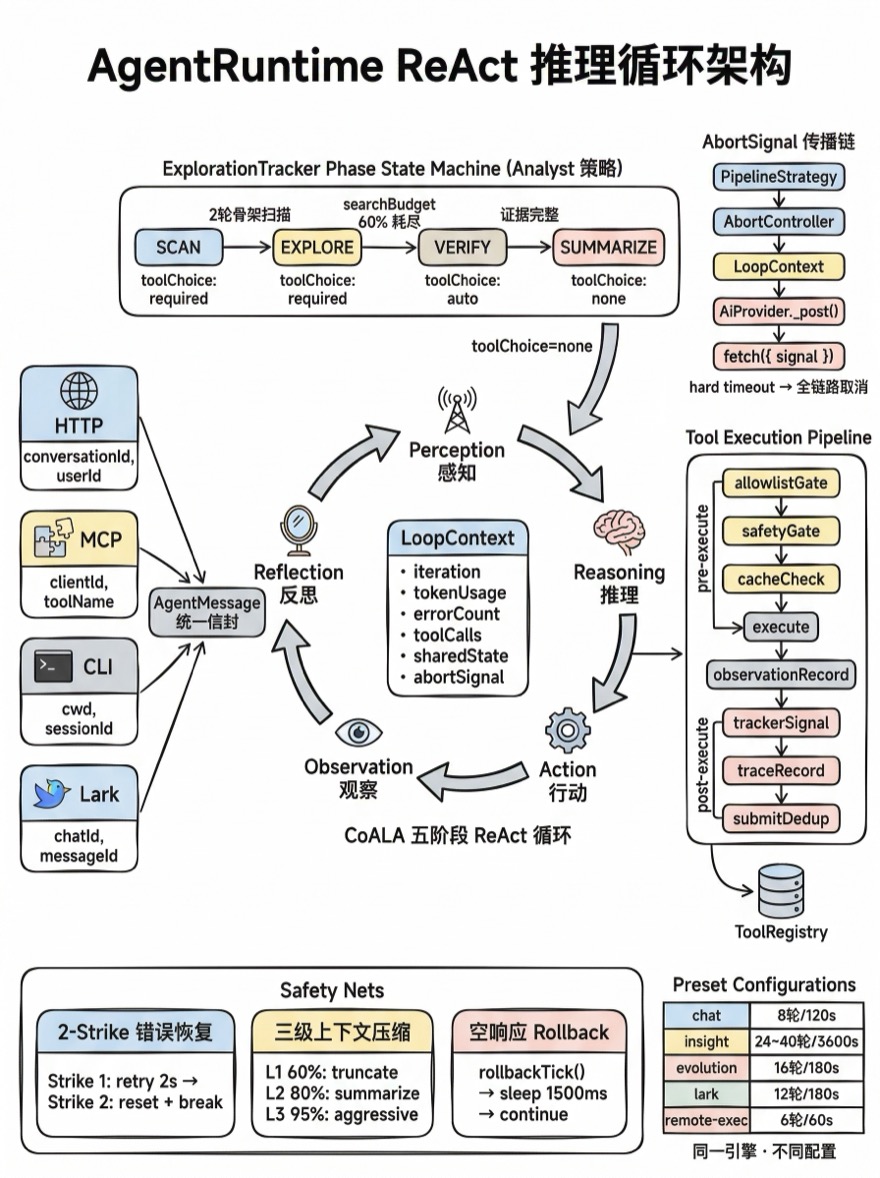
AgentRuntime — ReAct 推理循环
Alembic 的 AI 中枢 — 感知、推理、行动、反思的循环引擎。
相关章节:Agent 在 Bootstrap 冷启动 中驱动知识提取,工具和记忆系统详见 ch15
问题场景
用户说"帮我分析这个模块的设计模式"。Agent 不能一步到位——它需要先搜索知识库看有没有相关记录,然后读取模块的源代码,调用 AST 工具分析类结构,识别出可能的设计模式,最后把发现组织成有条理的回答。
这是一个多步推理 + 多次工具调用的过程。Agent 需要一个循环引擎来驱动"思考 → 行动 → 观察 → 再思考"的迭代,直到得出满意的答案或者耗尽预算。
更关键的是:这个引擎不能只为一种任务服务。聊天场景需要 8 轮以内的快速交互,深度分析需要 24 轮的多阶段流水线,飞书消息需要 12 轮/180 秒的中等执行。这些看似不同的任务,底层用的是同一个循环引擎——通过 Preset 配置来改变行为。
LLM 工作原理速览
本章深入 Agent 的运行时引擎。在此之前,需要理解几个 LLM 的基本工作机制——它们直接决定了 AgentRuntime 为什么要这样设计。
LLM API 是无状态的
LLM 没有记忆。每次 API 调用都是一个独立的 HTTP 请求,模型不知道上一次调用说了什么。要实现多轮对话,必须把之前的对话历史重新发送:
Call 1: messages: [user: "分析这个模块"]
→ assistant: tool_call(search_code, "Module")
Call 2: messages: [user: "分析这个模块",
assistant: tool_call(search_code),
tool: "找到 3 个文件...", ← 上一轮输出变成这一轮输入
]
→ assistant: tool_call(read_file, "Module.ts")
Call 3: messages: [user: "分析这个模块",
assistant: tool_call(search_code),
tool: "找到 3 个文件...",
assistant: tool_call(read_file), ← 又追加了
tool: "class Module { ... }", ← 又追加了
]
→ assistant: "这个模块使用了策略模式..."OpenAI、Anthropic、Google Gemini、DeepSeek——所有 LLM API 都是如此。ChatGPT 网页版、OpenAI Assistants API 看起来有"线程记忆",本质上是服务端帮你管理消息列表,每次调用仍然重新注入全部历史。
上下文窗口与输出膨胀
每个模型有一个上下文窗口(Context Window)上限——消息历史 + 系统提示 + 工具定义的 token 总和不能超过这个值(GPT-5.4 / Claude Opus 4.6 / Gemini 3.1 Pro 均为 1M,mini 模型通常 200K–400K)。
这带来一个核心矛盾:LLM 的输出会成为自己未来的输入。如果不管理,消息历史会随迭代次数线性甚至指数膨胀:
Iter 1: 消息历史 ~500 tokens
Iter 5: 消息历史 ~8,000 tokens ← 每轮增加工具调用+结果+AI推理
Iter 10: 消息历史 ~20,000 tokens ← 逼近小模型上限
Iter 15: 消息历史 ~35,000 tokens ← 超过 GPT-3.5 窗口超过窗口后模型直接报错。但更隐蔽的问题是:即使没超限,过长的上下文会导致 LLM 注意力衰减——模型对中间位置的信息关注度下降("Lost in the Middle"效应),早期搜索到的关键信息可能被"遗忘"。
Tool Calling 协议
现代 LLM API 支持 Tool Calling(也叫 Function Calling):你在请求中声明可用的工具(名称、参数 schema),LLM 可以选择返回结构化的工具调用请求而非纯文本:
// 请求
chatWithTools("分析这个模块", {
toolSchemas: [
{ name: "search_code", parameters: { query: "string" } },
{ name: "read_file", parameters: { path: "string" } },
]
})
// LLM 返回(不是文本,而是结构化调用)
{
functionCalls: [{ name: "search_code", args: { query: "Module 设计模式" } }]
}你的代码执行这个工具调用,把结果追加到消息历史,再次调用 LLM——这就形成了 ReAct 循环的基础。
ReAct 范式
ReAct(Reasoning + Acting) 是目前最主流的 Agent 架构模式。核心思想:让 LLM 在推理和行动之间交替——先思考需要什么信息,调用工具获取,观察结果,再思考下一步。
Thought: 用户想了解设计模式,我应该先搜索相关代码
Action: search_code("Module 设计模式")
Observation: 找到 3 个文件...
Thought: 需要读取 Module.ts 确认具体实现
Action: read_file("Module.ts")
Observation: class Module { ... }
Thought: 这是策略模式,我可以给出回答了
Answer: "这个模块使用了策略模式..."与预定义的线性 Chain(A → B → C)不同,ReAct 循环允许 Agent 在运行时动态决定下一步做什么。Agent 不知道要搜索几次、不知道哪些文件有价值、也不知道什么时候信息"够了"——这些全由 LLM 在每一轮根据当前上下文自行判断。
理解了这些机制,就能明白 AgentRuntime 面临的核心工程挑战:如何在无状态的 LLM API 上构建多轮、有记忆、能自我管理上下文的推理循环。
CoALA 认知架构
AgentRuntime 的设计借鉴了 CoALA(Cognitive Architectures for Language Agents) 框架——一个将 Agent 分解为五个认知阶段的理论模型。Alembic 不是机械地照搬论文,而是把五个阶段映射到了具体的工程组件:
| CoALA 阶段 | Alembic 组件 | 职责 |
|---|---|---|
| Perception | AgentMessage + MessageAdapter | 接收并统一来自 HTTP/MCP/CLI/Lark 的输入 |
| Working Memory | LoopContext + ContextWindow + ActiveContext | 维护循环状态、压缩历史、记录推理链 |
| Reasoning | aiProvider.chatWithTools() + SystemPromptBuilder | LLM 分析当前状态,决定下一步行动 |
| Action | ToolExecutionPipeline + ToolRegistry | 执行工具调用,中间件链过滤和记录 |
| Reflection | ExplorationTracker + MemoryCoordinator | 评估结果、收集信号、驱动阶段转换 |
五个阶段形成一个闭环——Reflection 的输出成为下一次 Perception 的输入。这不是简单的"调 LLM → 调工具 → 调 LLM"线性链,而是有记忆、有反思、有阶段意识的认知循环。
ReAct 循环
核心循环
reactLoop() 是 AgentRuntime 最核心的方法——约 1200 行代码中,超过一半围绕这个循环展开。伪代码:
reactLoop(ctx: LoopContext):
while true:
ctx.iteration++
// ① 退出检查(含 AbortSignal)
if abortSignal?.aborted:
break // 外部中止,立即退出
if shouldExit(tracker, maxIterations, timeout, policy):
break
// ② 迭代准备
if tracker:
nudge ← tracker.getNudge(trace) // 阶段引导提示
appendMessage(nudge)
toolChoice ← tracker.getToolChoice() // dynamic: auto/required/none
systemPrompt ← basePrompt + phaseContext + budgetInfo
// ③ LLM 调用(传入 abortSignal)
try:
llmResult ← aiProvider.chatWithTools(prompt, {
messages, systemPrompt, toolSchemas, toolChoice, abortSignal
})
consecutiveAiErrors ← 0
catch aiErr:
if abortSignal?.aborted: // AbortError 不计入错误计数
break
→ 2-strike 错误恢复(见下文)
// ④ 空响应处理
if not llmResult.text and not llmResult.functionCalls:
→ 空响应 rollback(见下文)
// ⑤ 分支:工具调用
if llmResult.functionCalls:
for each fc in llmResult.functionCalls[0:8]: // 每轮最多 8 次
result ← toolPipeline.execute(fc, ctx)
tracker?.endRound({hasNewInfo, submitCount, toolNames})
continue // 下一轮迭代
// ⑥ 分支:纯文本回复
else if llmResult.text:
if tracker?.onTextResponse().isFinalAnswer:
lastReply ← cleanFinalAnswer(llmResult.text)
break
else:
lastReply ← llmResult.text
break
return finalize(ctx) // 构建 AgentResult几个设计要点:
每轮最多 8 次工具调用(MAX_TOOL_CALLS_PER_ITER = 8)。LLM 有时候会在一次回复中请求十几个工具调用——但执行太多会导致上下文膨胀。截断到 8 次,剩余的下一轮再执行。
toolChoice 动态控制。ExplorationTracker 根据当前阶段返回不同的 toolChoice 值:SEARCH 阶段用 auto(让 LLM 自由选择),SUMMARIZE 阶段用 none(禁止工具调用,强制输出文本)。这是"软约束"——通过 API 参数而非 prompt 文本来引导 LLM 行为。
cleanFinalAnswer。LLM 返回的文本可能包含 Nudge 引导指令的回显(如 searchHints、remainingTasks)、Final Answer: 前缀、[MEMORY:xxx]...[/MEMORY] 标签、轮次计数行等噪声。cleanFinalAnswer 剥离这些标记,只保留面向用户的内容。
LoopContext:状态容器
每次 reactLoop() 调用使用一个独立的 LoopContext 实例来封装所有循环状态:
// lib/agent/core/LoopContext.ts
class LoopContext {
// 循环状态
iteration = 0;
lastReply = '';
toolCalls: ToolCallEntry[] = [];
tokenUsage = { input: 0, output: 0 };
// 错误恢复
consecutiveAiErrors = 0; // 连续 AI 错误计数
consecutiveEmptyResponses = 0; // 连续空响应计数
// 注入的依赖
messages: MessageAdapter; // 消息历史管理
tracker?: ExplorationTracker; // 阶段状态机
trace?: ActiveContext; // 推理链记录
memoryCoordinator?: MemoryCoordinator;
sharedState?: { submittedTitles, submittedTriggers, submittedPatterns }; // 提交去重
// 只读配置
source: 'user' | 'system'; // 消息来源
budget: { maxIterations, maxTokens, temperature, timeoutMs };
capabilities: Capability[];
baseSystemPrompt: string;
toolSchemas: ToolSchema[];
// 外部中止信号
abortSignal: AbortSignal | null; // PipelineStrategy hard timeout 时取消进行中的 LLM 调用
}source 字段区分用户发起和系统发起的循环。用户发起的循环(Chat)容错低——空响应直接终止;系统发起的循环(Bootstrap/Scan)容错高——空响应可以 rollback 重试。
终止条件
循环通过五个条件判断是否退出:
| 条件 | 判断逻辑 | 触发场景 |
|---|---|---|
| Final Answer | LLM 返回纯文本 + tracker 确认为最终答案 | 正常完成 |
| 最大迭代 | iteration ≥ maxIterations + 2(硬编码 grace) | 预算耗尽 |
| 超时 | Date.now() - startTime ≥ timeoutMs | 长时间无进展 |
| 空闲停滞 | roundsSinceNewInfo ≥ idleRoundsToExit 且已探索 ≥ 10 轮 | NudgeGenerator 触发阶段转换 |
| 阶段完成 | SUMMARIZE 阶段 + 已输出文本 | 流水线末尾 |
不同 Preset 的预算差异很大:
| Preset | maxIterations | timeout | 典型场景 |
|---|---|---|---|
| chat | 8 | 120s | Dashboard 对话 |
| insight | 24 | 3600s | 深度分析 + 知识提取 |
| evolution | 16 | 180s | Recipe 演进决策 |
| lark | 12 | 180s | 飞书消息桥接 |
| remote-exec | 6 | 60s | 终端命令执行 |
ExplorationTracker:阶段状态机
系统发起的循环(insight/bootstrap)使用 ExplorationTracker 来控制阶段转换。Tracker 根据管线类型使用不同的阶段策略:
Analyst 策略(纯代码分析,输出 Markdown 报告):
SCAN → EXPLORE → VERIFY → SUMMARIZEBootstrap 策略(有知识提交阶段):
EXPLORE → PRODUCE → SUMMARIZEProducer 策略(纯知识生产):
PRODUCE → SUMMARIZE以 Analyst 策略为例,每个阶段有不同的行为特征:
| 阶段 | toolChoice | 行为 | 转换信号 |
|---|---|---|---|
| SCAN | required | 获取项目骨架(目录 + 关键文件列表) | 2 轮后自动转换 |
| EXPLORE | required | 深入搜索,发现文件和模式 | searchBudget 60% 耗尽或连续 3 轮无新信息 |
| VERIFY | auto | 停止新搜索,确认关键细节 | 迭代达 80% 或连续 2 轮无新信息 |
| SUMMARIZE | none | 禁止工具调用,输出分析结果 | 文本响应完成 |
阶段转换通过**Nudge(引导提示)**实现——Tracker 在阶段边界向消息历史中注入一条系统消息:
"已进入验证阶段。停止新的搜索,确认关键细节。"这比修改 system prompt 更有效——LLM 通常对消息队列中最新的指令响应最敏感。
Tracker 还维护了一组信号指标来判断阶段转换时机:
interface ExplorationMetrics {
submitCount: number;
roundsSinceNewInfo: number; // 连续无新信息的轮次
roundsSinceSubmit: number; // 连续无提交的轮次
iteration: number; // 当前迭代计数
searchRoundsInPhase: number; // 当前阶段的搜索轮次
phaseRounds: number; // 当前阶段的轮次
consecutiveIdleRounds: number; // 连续无工具调用的轮次
}
// FullExplorationMetrics 扩展(含 Set 集合,用于 NudgeGenerator / SignalDetector)
interface FullExplorationMetrics extends ExplorationMetrics {
uniqueFiles: Set<string>; // 发现的唯一文件
uniquePatterns: Set<string>; // 发现的唯一模式
uniqueQueries: Set<string>; // 执行的唯一搜索
totalToolCalls: number;
}roundsSinceNewInfo 是最关键的信号——连续 3 轮没有发现新文件或新模式,意味着搜索已经探索完了可用的信息空间,应该转入下一阶段。
错误恢复
2-Strike AI 错误策略
LLM API 调用可能因网络抖动、速率限制、服务故障而失败。AgentRuntime 用"两次机会"策略处理:
第 1 次失败:
consecutiveAiErrors++
tracker?.rollbackTick() // 不消耗迭代预算
等待 2000ms
continue → 下一轮重试
第 2 次失败:
重置消息历史到只剩初始 prompt
break → 退出循环,返回已有结果每次 AI 错误都会调用 rollbackTick()——因为失败不是 Agent 的决策,不应该消耗宝贵的迭代预算。
为什么重置消息历史?因为连续两次 AI 错误可能意味着上下文本身有问题——比如包含了无法解析的 token、超长的工具返回结果、或者触发了内容过滤。resetToPromptOnly() 清空所有中间状态,给系统一个干净的重启点。
熔断器感知
如果 AI Provider 的熔断器已经打开(Ch09 中的 CircuitBreaker 检测到连续失败),reactLoop 跳过重试直接退出:
catch (aiErr) {
if (aiErr.code === 'CIRCUIT_OPEN') {
// 不重试——熔断器通常需要 30-60 秒恢复
// 直接退出循环,返回已有结果
return null;
}
// 正常的 2-strike 流程
...
}这避免了一个恶性循环:AI 服务宕机 → 每个循环都在 2-strike 中消耗 4 秒等待 → 大量请求堆积。熔断器打开后,所有循环立即退出,等待服务恢复。
AbortSignal 全链路传播
PipelineStrategy 的每个阶段有独立的 hard timeout。当阶段超时时,不只是丢弃 Promise.race 的结果——还需要取消正在进行中的 LLM HTTP 请求,否则这个请求会继续占用资源直到自然超时(通常 30–60 秒)。
// lib/agent/PipelineStrategy.ts — #runWithTimeout
const abortController = new AbortController();
const reactPromise = runtime.reactLoop(stagePrompt, {
...opts,
abortSignal: abortController.signal, // 注入到 LoopContext
});
// hard timeout 触发时:先 abort 再 reject
hardTimer = setTimeout(() => {
abortController.abort(); // ① 取消进行中的 HTTP 请求
reject(new Error('__STAGE_HARD_TIMEOUT__')); // ② 触发超时处理
}, hardLimitMs);信号从 PipelineStrategy 一路穿透到 HTTP 层:
PipelineStrategy (AbortController)
→ LoopContext.abortSignal
→ #shouldExit() 检查 aborted → 立即退出
→ #callLLM() 传给 aiProvider.chatWithTools()
→ #handleAiError() 区分 AbortError → 不计入 2-strike
→ AiProvider._post(externalSignal) 联动本地 controller
→ fetch({ signal }) → HTTP 请求立即终止三个 AI Provider(Claude、Gemini、OpenAI)的 _post() 方法都用相同模式联动外部信号和本地超时 controller:
// 所有 Provider 共用模式
const controller = new AbortController();
const timer = setTimeout(() => controller.abort(), this.timeout);
// 外部中止信号 → 联动本地 controller
const onExternalAbort = () => controller.abort();
externalSignal?.addEventListener('abort', onExternalAbort, { once: true });
try {
const res = await fetch(url, { signal: controller.signal, ... });
} finally {
clearTimeout(timer);
externalSignal?.removeEventListener('abort', onExternalAbort);
}AiProvider 基类的重试逻辑也感知 AbortError——如果错误是 AbortError,直接抛出不重试,因为这是调用方主动取消而非暂时性故障。
空响应 Rollback
LLM 有时返回既没有文本也没有工具调用的空响应——通常是因为上下文中存在矛盾指令或者 token 刚好截断。
if (!llmResult.text && !llmResult.functionCalls) {
// SUMMARIZE 阶段特殊处理:允许 2 轮 grace
if (tracker?.phase === 'SUMMARIZE' && metrics.phaseRounds < 2) {
consecutiveEmptyResponses++;
await sleep(1500);
continue; // 不 rollbackTick,让 phaseRounds 计入
}
// 系统模式:重试最多 2 次
if (isSystem && ++consecutiveEmptyResponses < 2) {
tracker?.rollbackTick(); // 不计入迭代次数
await sleep(1500);
continue; // 重试
}
// 用户模式或重试耗尽:退出
break;
}两种空响应场景的 rollbackTick 策略不同:SUMMARIZE 阶段不回退(让 phaseRounds 如实增长,便于 grace 判断),普通系统重试回退(不浪费迭代预算)。
优雅退出保护
当 Tracker 进入 SUMMARIZE 阶段,toolChoice 被设为 none——但 LLM 有时会忽略这个约束,仍然返回工具调用。AgentRuntime 用硬保护兜底:
if (tracker?.isGracefulExit && llmResult.functionCalls?.length > 0) {
// 忽略工具调用
if (llmResult.text) {
ctx.lastReply = cleanFinalAnswer(llmResult.text);
break; // 有文本 → 提取文本,强制退出
}
continue; // 无文本 → 重试,期望下一轮输出文本
}提交去重
在知识生产循环中(insight/bootstrap preset),Agent 可能反复尝试提交相同或高度相似的知识候选。sharedState 中维护了三个 Set:
submittedTitles: Set<string>— 已提交的标题(精确匹配)submittedTriggers: Set<string>— 已提交的 trigger(跨维度去重,防止不同标题使用相同 trigger)submittedPatterns: Set<string>— 已提交的模式签名(代码指纹去重)
ToolExecutionPipeline 的去重中间件在执行 submit_knowledge 工具前依次检查这三个 Set——如果 trigger、标题或模式已存在,返回错误消息而不实际调用工具:
⚠ 重复 trigger: "@xxx" 已被其他候选占用。
⚠ 重复提交: "xxx" 已存在。LLM 看到这个错误后通常会尝试提交不同的内容,而不是陷入重复循环。
三级上下文压缩
问题:上下文窗口膨胀
一次深度分析可能执行 20+ 轮工具调用。每轮的工具参数、返回结果、AI 推理文本都会追加到消息历史中。到第 15 轮时,上下文可能已经超过了模型的有效窗口——即使技术上没超过 token 限制,上下文过长也会导致 LLM "遗忘"早期的关键信息。
ContextWindow 用三级压缩策略管理这个问题:
| 级别 | 触发阈值 | 操作 | 恢复比例 |
|---|---|---|---|
| L1 | 60% | 截断旧的工具返回结果,保留文本摘要 | ~20% |
| L2 | 80% | 历史对话摘要为 digest,只保留最后 2 轮 | ~40-50% |
| L3 | 95% | 激进裁剪,只保留 prompt + 最后 1 轮 + 已提交列表 | 最大 |
Token 预算的自适应
不同模型的上下文窗口差异巨大(GPT-5.4 / Gemini 3.1 Pro / Claude Opus 4.6 均为 1M,GPT-5.4-mini 400K,Claude Haiku 4.5 200K)。ContextWindow 根据模型名称自动调整预算:
// lib/agent/context/ContextWindow.ts
static resolveTokenBudget(modelName, opts) {
const contextSize = detectModel(modelName);
if (contextSize >= 400_000) {
return opts.isSystem ? 48_000 : 36_000; // XLarge: 1M 级模型可容纳更多上下文
} else if (contextSize >= 200_000) {
return opts.isSystem ? 32_000 : 24_000; // Large: 系统 +33%
} else if (contextSize >= 64_000) {
return opts.isSystem ? 24_000 : 20_000; // Medium: 系统 +20%
} else if (contextSize >= 16_000) {
return opts.isSystem ? 14_000 : 12_000; // Small: 系统 +17%
} else {
return Math.floor(contextSize * (opts.isSystem ? 0.75 : 0.65)); // Micro: 系统 +15%
}
}系统模式比用户模式多分配 15–33% 的预算——因为系统循环(如 insight)执行更多工具调用,需要更大的上下文空间来容纳中间结果。超大模型(≥400K)预算最高(48K/36K),大模型(≥200K)次之(32K/24K),小模型差距较小(15%)。
压缩日志
每次压缩操作都记录到 compactionLog——这让调试成为可能。如果 Agent 的输出质量在某一轮突然下降,开发者可以检查 compactionLog 看是否刚好执行了 L2 压缩,导致关键上下文被摘要掉了。
Token 预算双轨制
上节讲了 ContextWindow 如何管理输入侧的上下文膨胀。但 Token 管理实际上有两个独立维度:
| 维度 | 来源 | 值域 | 控制什么 |
|---|---|---|---|
| ContextWindow.tokenBudget | resolveTokenBudget(model) | 12K–32K | 累积消息历史的输入上下文上限 |
| BudgetPolicy.maxTokens | Preset 配置 | 4096–8192 | 单次 LLM 调用的输出 token 上限 |
两者完全独立。ContextWindow 管"喂给 LLM 多少",BudgetPolicy 管"LLM 每次最多吐多少"。
// 每次 LLM 调用的参数
aiProvider.chatWithTools(prompt, {
messages: ctx.messages.toMessages(), // ← ContextWindow 压缩后的历史(输入侧)
systemPrompt: effectiveSystemPrompt, // 不计入 ContextWindow
toolSchemas: effectiveToolSchemas, // 不计入 ContextWindow
maxTokens: budget.maxTokens ?? 4096, // ← BudgetPolicy 控制的输出上限
temperature: budget.temperature ?? 0.7,
})注意:system prompt 和 tool schemas 不计入 ContextWindow 估算——它们作为独立参数传给 LLM provider。这也是系统模式多分配 15–33% 预算的原因——为 tool schemas 占用的隐形空间留余量。
为什么需要输出上限? LLM 每轮的输出会追加到消息历史,成为下一轮的输入。如果不限制输出长度:
灾难场景:
Iter 1: LLM 一次吐出 15K tok 的分析报告
→ 追加到消息历史 → usage 直接跳到 71%
Iter 2: 可用空间只剩 ~7K → L1 压缩触发
→ 工具结果被大幅截断,信息质量断崖下降输出上限本质上是保护输入空间不被自己的输出挤占——让 24 轮迭代能真正跑满,而不是前 3 轮就耗尽 ContextWindow。
Chat Preset 设 4096 tok(大部分迭代是工具调用,JSON 通常 200-500 tok,最终文本回复 4096 ≈ 3000 中文字足够);Insight Preset 同样设 4096 tok(虽然知识生产阶段 submit_knowledge 参数较大,但单次输出限制迫使 LLM 分轮次提交,避免单轮输出膨胀挤占上下文空间)。
动态工具结果配额
ContextWindow 不只被动压缩——它还主动控制新增内容的大小。getToolResultQuota() 根据当前上下文填充度,动态缩减工具返回结果的截断阈值:
// lib/agent/context/ContextWindow.ts
getToolResultQuota() {
const usage = this.getTokenUsageRatio();
if (usage < 0.4) return { maxChars: 6000, maxMatches: 15 };
if (usage < 0.6) return { maxChars: 3000, maxMatches: 8 };
if (usage < 0.8) return { maxChars: 1500, maxMatches: 5 };
return { maxChars: 800, maxMatches: 3 };
}maxChars 控制单条工具结果的最大字符数,maxMatches 控制搜索类工具返回的最大匹配条数。效果:前几轮搜索返回丰富信息(15 条 × 6K 字符),后期返回精炼摘要(3 条 × 800 字符)。
这和三级压缩形成互补——压缩处理"已经在历史中的旧内容",动态配额控制"即将加入历史的新内容"。两者协作,让上下文使用率平缓增长而非阶梯式跳变。
一次 Insight 循环(24K budget)的典型 Token 流:
Iter 1-4: usage 10-30% → 配额 6000 字符/条, 搜索返回完整
Iter 5-8: usage 30-55% → 配额降到 3000, L1 尚未触发
Iter 9-12: usage 55-70% → L1 压缩截断旧结果, 配额降到 1500
Iter 13-18: usage 回落到 45%, 再爬升 → L2 压缩保留最后 2 轮, 配额 3000
Iter 19-24: usage 波动 → 知识生产阶段, submit 参数占主要空间工具执行管线
Agent 的工具调用不是直接调 toolRegistry.execute()——中间有一条中间件管线,每个工具调用都要经过:
allowlistGate → safetyGate → cacheCheck → [execute] → observationRecord → trackerSignal → traceRecord → submitDedup[execute] 是管线的核心动作(不是中间件),前三个中间件在执行前拦截,后四个在执行后记录和检查:
| 中间件 | 职责 | 拦截时行为 |
|---|---|---|
| allowlistGate | 拒绝不在当前 Capability 允许列表中的工具 | 返回 "Unknown tool" 错误 |
| safetyGate | SafetyPolicy 检查(文件范围、命令黑名单) | 返回 "Blocked by policy" 错误 |
| cacheCheck | MemoryCoordinator 缓存命中 | 返回缓存结果,跳过执行 |
| observationRecord | 记录到 MemoryCoordinator 的情景记忆 | — |
| trackerSignal | 收集信号(新文件、新模式、查询) | 更新 Tracker metrics |
| traceRecord | 记录到 ActiveContext 推理链 | — |
| submitDedup | 检查知识提交是否重复 | 返回 "Duplicate" 错误 |
allowlistGate 防止 LLM 幻觉工具——LLM 有时候会编造不存在的工具名称,或者调用当前 Preset 没有授权的工具。比如 chat Preset 没有 execute_command 能力,但 LLM 可能因为 system prompt 中提到了终端操作就尝试调用它。allowlistGate 会拦截这种调用。
每个工具调用的结果包含元数据:
interface ToolMetadata {
cacheHit: boolean;
blocked: boolean;
isNew: boolean; // 发现了新文件/新模式
durationMs: number;
dedupMessage?: string;
isSubmit?: boolean; // 是否为有效的知识提交
}isNew 尤其重要——它驱动 ExplorationTracker 的 roundsSinceNewInfo 计数器。一轮中有 isNew=true 的工具调用,计数器重置为 0;否则加 1。
AgentFactory 与 Preset
配置化 Runtime
Alembic 没有 ChatAgent、BootstrapAgent、LarkAgent 这样的特化子类。只有一个 AgentRuntime 类,通过 Preset 配置来改变行为。AgentFactory 的工作是把 Preset 名称翻译为 Runtime 实例:
// lib/agent/AgentFactory.ts
createRuntime(presetName: string, overrides: RuntimeOverrides): AgentRuntime {
const preset = getPreset(presetName, overrides);
// 实例化 Capability(字符串名 → 对象实例)
const capabilities = preset.capabilities.map(name =>
CapabilityRegistry.create(name, opts)
);
// 实例化 Policy(支持工厂函数)
const policies = preset.policies.map(p =>
typeof p === 'function' ? p(overrides) : p
);
const strategy = preset.strategyInstance;
return new AgentRuntime({
presetName, aiProvider, toolRegistry, container,
capabilities, strategy, policies, persona, ...
});
}Policy 支持工厂函数而非纯对象——因为有些 Policy 需要根据运行时参数(比如用户传入的超时时间)动态构造。
Preset 配置对比
每个 Preset 定义了三个维度:Capability(能做什么)、Strategy(怎么组织工作)、Policy(什么约束)。下一章会深入讲解这三个维度的正交组合设计,这里先看 Preset 的全景:
| Preset | Capability | Strategy | 迭代/超时 | 场景 |
|---|---|---|---|---|
| chat | Conversation, Code Analysis | Single | 8 轮 / 120s | Dashboard/飞书对话 |
| insight | Code Analysis, Knowledge Production | Pipeline(Analyze → Gate → Produce → Gate) | 24 轮 / 3600s | 深度分析 + 知识提取 |
| evolution | Evolution Analysis | Pipeline(Evolve → Evolution Gate) | 16 轮 / 180s | Recipe 演进决策 |
| lark | Conversation, Code Analysis | Single | 12 轮 / 180s | 飞书知识管理对话 |
| remote-exec | Conversation, Code Analysis, System Interaction | Single | 6 轮 / 60s | 远程执行 |
insight 是最复杂的 Preset——它使用 PipelineStrategy 把任务分为四个阶段。
Analyze 阶段的预算不是固定的——computeAnalystBudget() 根据项目文件数自适应缩放:
// lib/agent/domain/insight-analyst.ts
function computeAnalystBudget(fileCount: number) {
if (fileCount <= 40) maxIter = 24; // 小型项目:基线
else if (fileCount <= 100) maxIter = 24→32; // 中型:线性插值
else if (fileCount <= 200) maxIter = 32→40; // 大型:线性插值
else maxIter = 40; // 封顶,避免单维度成本失控
return {
...ANALYST_BUDGET,
maxIterations: maxIter,
searchBudget: round(maxIter × 0.75), // 保持 75% 比例
timeoutMs: round((maxIter / 24) × 300_000), // 等比缩放 (24轮→300s, 40轮→500s)
};
}Orchestrator 在创建 Analyst Tracker 时注入:ExplorationTracker.resolve('analyst', computeAnalystBudget(projectInfo.fileCount))。这意味着分析一个 150 文件的项目会拿到 36 轮/375s 预算,而 30 文件的项目只用 24 轮/300s——既不浪费小项目的时间,也不让大项目因预算不足而分析不充分。
Stage 1: Analyze(分析)
Capability: code_analysis
Budget: 24~40 轮(自适应), temperature 0.4, timeout 300~500s(阶段级)
SystemPrompt: ANALYST_SYSTEM_PROMPT
PromptBuilder: buildAnalystPrompt(dimConfig, projectInfo, ...)
Phase: SCAN → EXPLORE → VERIFY → SUMMARIZE
↓
Stage 2: Quality Gate(质量门)
Evaluator: insightGateEvaluator
三种结果: pass / retry / degrade
↓
Stage 3: Produce(生产)
Capability: knowledge_production
Budget: PRODUCER_BUDGET, temperature 0.3, timeout 180s
RetryBudget: { maxIterations: 5, temperature: 0.3, timeout 120s }
SystemPrompt: PRODUCER_SYSTEM_PROMPT
PromptBuilder: buildProducerPromptV2(gateArtifact, dimConfig, ...)
Phase: EXPLORE → PRODUCE → SUMMARIZE
↓
Stage 4: Rejection Gate(拒绝门)
Evaluator: producerRejectionGateEvaluator
检查: rejected > success 且 rejected ≥ 2Quality Gate 是三态评估器——不是简单的 pass/fail:
| 评估结果 | 条件 | 动作 |
|---|---|---|
| pass | V2: 质量分 ≥ 60;V1: 证据 ≥ 400 字符 + 文件引用 ≥ 3 + 结构完整 | 继续到 Produce 阶段 |
| retry | V2: 质量分 ≥ 40;V1: 证据不足但有基础 | 重新执行 Analyze(最多 1 次) |
| degrade | 拒绝模式匹配("I cannot"、"无法分析")或完全无输出 | 跳过 Produce,直接输出摘要 |
degrade 模式很实用——当项目代码量极少或结构简单时,强行进入知识生产阶段只会产出低质量候选。不如优雅降级,告诉用户"这个项目结构简单,暂时不需要深度知识提取"。
超时零输出快速重试
当 Analyze 阶段 hard timeout 且零工具调用(LLM 完全卡住,通常是因为上下文过于复杂导致模型"思考"超时),PipelineStrategy 不走正常的 gate → retry 流程,而是立即用 retryBudget 降级重跑:
if stageResult.timedOut and stageResult.toolCalls == 0 and not isRetry:
# 重置 ContextWindow(清空上一轮的空消息)
contextWindow.resetForNewStage()
# 用 retryBudget(更短时限)重建 tracker
retryTracker ← resolveStageTracker(stage, retryBudget)
# 立即重跑,跳过 gate 往返
stageResult ← runWithTimeout(runtime, retryPrompt, retryBudget)这比走完整的 gate → retry 路径快得多——后者需要等 gate evaluator 判定、构建 retry prompt、重新初始化 tracker,额外消耗 2–5 秒。快速重试把这个延迟压缩到接近零。
AgentRouter 与意图分类
路由优先级
用户消息到达后,AgentRouter 按照递减优先级决定使用哪个 Preset:
1. 手动指定(opts.preset 参数) → 直接使用
2. 通道启发式(如 "> command" 前缀) → remote-exec
3. 关键词匹配(正则规则,零延迟) → insight / remote-exec / ...
4. LLM 分类(语义准确,~500ms) → 任意 Preset
5. 默认 → chat关键词匹配是零延迟的——不调用 LLM,只执行正则表达式:
// lib/agent/AgentRouter.ts
KEYWORD_ROUTES = [
{
preset: 'insight',
keywords: [
/冷启动|cold[\s-]?start|bootstrap/i,
/扫描|analyze.*folder/i,
/深度分析.*路径/i,
]
},
{
preset: 'remote-exec',
keywords: [
/^[>$]\s*/, // Shell 前缀
/运行命令|exec.*command/i,
]
},
]如果关键词匹配不命中,降级到 LLM 分类——给 LLM 一个简短的分类 prompt,让它返回结构化的意图判断:
LLM_CLASSIFICATION_SCHEMA = {
preset: 'chat' | 'insight' | 'lark' | 'remote-exec', // required
confidence: number, // 0-1, required
reasoning?: string, // optional
}IntentClassifier 三层分类
IntentClassifier 更早一步——在 AgentRouter 之前——负责判断消息应该由哪个 Agent 处理(不同于 Preset 选择):
| 层 | 延迟 | 规则 | 示例 |
|---|---|---|---|
| 系统规则 | 0ms | 硬编码 /status、/screenshot 等 | /status → system |
| IDE 强信号 | ~1ms | 文件路径、代码操作、git 命令 | "重构 auth 模块" → ide_agent |
| Bot 信号 | ~1ms | 知识库、搜索、分析关键词 | "分析设计模式" → bot_agent |
IntentClassifier 还处理元语言包装——用户说"让 Copilot 帮我重构 auth 模块",实际意图只是"重构 auth 模块"。分类器会剥离"让 Copilot 帮我"这类包装词:
"在编辑器内输入新增按钮" → "新增按钮"
"让 Copilot 帮我重构 auth 模块" → "重构 auth 模块"
"修复 bug" → "修复 bug"(无包装,原样返回)AgentMessage 统一信封
四通道 → 一格式
Alembic 接收来自四个渠道的消息,格式各异:
- HTTP:JSON body,带
conversationId、userId、lang - Lark(飞书):带
chatId、messageId、senderName - CLI:带
cwd、sessionId - MCP:带
clientId、toolName
AgentMessage 用工厂方法把它们统一为一种格式:
// lib/agent/AgentMessage.ts
class AgentMessage {
id: string; // UUID
content: string; // 用户输入
channel: 'http' | 'lark' | 'cli' | 'mcp' | 'internal';
session: { id, history? };
sender: { id, type: 'user' | 'system' | 'agent' };
metadata: Record<string, unknown>;
replyFn?: (text: string) => Promise<void>;
timestamp: number;
}
// 四个工厂方法:
AgentMessage.fromHttp(req, replyFn?)
AgentMessage.fromLark(msg, replyFn?)
AgentMessage.fromCli(options)
AgentMessage.fromMcp(request)replyFn 是回调函数——每个通道有自己的回复方式:
| 通道 | replyFn 实现 |
|---|---|
| HTTP | (text) => res.json({ reply: text }) |
| Lark | (text) => bot.sendMessage(chatId, text) |
| MCP | (text) => stream.write(text)(SSE) |
| CLI | (text) => console.log(text) |
此外还有 AgentMessage.internal(content, opts) 用于 Agent 间内部通信(如 FanOut 子任务),channel 为 internal。
AgentRuntime 不关心消息从哪来——它只看 content 和 metadata,结束时调用 replyFn 把结果发回去。消息通道的差异被完全封装在工厂方法和回调函数中。
强制总结生成
当循环因预算耗尽或超时而终止时,Agent 可能还没来得及输出最终回复。produceForcedSummary 根据上下文类型生成不同格式的总结:
| 模式 | pipelineType | 输出格式 | 消费者 |
|---|---|---|---|
| 分析模式 | analyst | Markdown 结构化分析报告 | Quality Gate 评估 |
| Bootstrap 模式 | bootstrap | dimensionDigest JSON | 编排器 |
| 用户模式 | — | Markdown 自然语言摘要 | Dashboard/前端 |
强制总结通过一次额外的 LLM 调用实现——把工具调用历史的摘要作为上下文,让 LLM 生成结构化输出。toolChoice 设为 none 确保 LLM 不会再尝试调用工具。
运行时行为
场景 1:Chat 快速问答
用户(Dashboard):"API 接口怎么写?"
1. AgentMessage.fromHttp(req) → 统一格式
2. IntentClassifier: "API 接口" → bot_agent
3. AgentRouter: 无关键词命中 → LLM 分类 → chat Preset
4. AgentFactory.createRuntime('chat') →
Capability=[Conversation, CodeAnalysis], Strategy=Single,
Budget={iter:8, timeout:120s}
5. reactLoop():
Iter 1: LLM → search_knowledge("API 接口 设计模式")
→ toolPipeline: allowlist ✓ → execute → 返回 3 条 Recipe
Iter 2: LLM → 纯文本回复(基于搜索结果)
→ tracker.onTextResponse() → isFinalAnswer=true
→ break
6. replyFn(lastReply) → HTTP JSON 响应
total: 2 轮, ~3 秒场景 2:Insight 深度分析
用户:"深度分析 NetworkKit 模块"
1. AgentRouter: "深度分析" 命中关键词 → insight Preset
2. AgentFactory → PipelineStrategy, Budget={iter:24, timeout:3600s}
3. Stage 1 — Analyze (Analyst 策略: SCAN→EXPLORE→VERIFY→SUMMARIZE):
reactLoop(SCAN phase):
Iter 1-2: list_files, read_file → 获取项目骨架
reactLoop(EXPLORE phase):
Iter 3-7: search_code, read_file → 深入发现 15 个文件
ExplorationTracker: searchBudget 60% 耗尽 → VERIFY nudge
reactLoop(VERIFY phase):
Iter 8-9: 确认关键类的继承关系和协议实现
reactLoop(SUMMARIZE phase):
Iter 10: toolChoice=none → Markdown 分析报告 (2000 字)
4. Quality Gate:
insightGateEvaluator(report):
len=2000 > 500 ✓, fileRefs=8 > 3 ✓ → pass
5. Stage 2 — Produce (Bootstrap 策略: EXPLORE→PRODUCE→SUMMARIZE):
reactLoop(EXPLORE→PRODUCE phase):
Iter 1-8: submit_knowledge × 6 (2 被去重拦截)
softSubmitLimit=8 → SUMMARIZE nudge
reactLoop(SUMMARIZE):
Iter 9: 输出总结文本
6. Rejection Gate:
rejected=1, success=5 → 1 > 5? false → pass
total: ~20 轮, ~45 秒, 产出 4 条有效知识候选场景 3:错误恢复
系统(Bootstrap):扫描 Payment 模块
1. reactLoop():
Iter 1: LLM → search_code("Payment") → 正常返回
Iter 2: LLM → AI API 超时
→ consecutiveAiErrors=1, 等待 2000ms, continue
Iter 3: LLM → AI API 超时(第二次)
→ consecutiveAiErrors=2
→ resetToPromptOnly() → break
2. 已有 Iter 1 的搜索结果
→ produceForcedSummary():
"基于已搜索的 Payment 模块文件,初步发现..."
→ 返回部分结果(而非空回复)2-strike 的价值在于:用户看到的不是"服务不可用",而是"基于已有信息的部分结果"。这比完全失败好得多。
权衡与替代方案
为什么不用 LangChain
LangChain 是最流行的 Agent 框架,Alembic 为什么自建引擎?
- 依赖体积。LangChain 的依赖树超过 300 个包。Alembic 的整个 Agent 模块约 7400 行 TypeScript,零外部 Agent 框架依赖。
- DI 集成。Alembic 的 ServiceContainer 依赖注入贯穿全栈——从 DatabaseConnection 到 AgentRuntime。LangChain 有自己的组件模型,两套系统叠加会导致混乱的生命周期管理。
- 可控性。ReAct 循环的每一步——从 toolChoice 的动态选择到空响应的 rollback 策略——都是 Alembic 特有的需求。用框架做这些定制需要频繁绕过框架的抽象,不如从头实现。
为什么最大迭代不超过 24 轮
实验数据表明:
- 1–8 轮:ROI 最高。搜索和初步分析在前 8 轮完成。
- 8–16 轮:边际收益递减。更多的搜索通常返回已知信息。
- 16–24 轮:主要用于知识生产(提交候选),而非新发现。
- > 24 轮:几乎没有新信息。LLM 开始"自说自话"或重复之前的操作。
Chat 场景设 8 轮是因为用户期望快速响应——等 3 分钟得到一个更完整的答案,不如等 10 秒得到一个 80% 质量的答案。Insight 场景设 24 轮但超时放宽到 1 小时,因为它通常在后台执行(Bootstrap),用户对延迟容忍度高。Lark 场景设 12 轮/180s,在即时通讯的快速响应和足够深度之间取平衡。
为什么不用 Plan-and-Execute
Plan-and-Execute 架构是先生成完整计划("Step 1: 搜索文件, Step 2: 分析结构, Step 3: 提取模式"),然后逐步执行。它的问题:
- 计划在执行前就过时了。Agent 在 Step 1 搜索时发现了意料之外的文件结构——原先的 Step 2 和 Step 3 基于错误的假设。ReAct 的"每步重新思考"天然适应这种不确定性。
- 计划本身消耗 token。生成一个详细的 5 步计划可能消耗 1000+ token,但其中 3 步可能在执行后被修改。ReAct 的增量式推理更节省 token。
- ExplorationTracker 已经提供了"软计划"——SEARCH → VERIFY → SUMMARIZE 的阶段划分给了 ReAct 循环足够的结构感,同时保留了每一步的灵活性。
小结
AgentRuntime 的设计可以归结为两个核心选择:
统一引擎 + 配置分化。不创建 Agent 子类,而是用 Preset 配置 Capability/Strategy/Policy 三个维度。同一个
reactLoop()方法既跑 8 轮的快速对话,也跑 24 轮的深度分析流水线。代码复用最大化,行为差异通过配置表达。容错优于正确。2-strike 错误恢复、空响应 rollback、熔断器感知、提交去重——这些机制的共同思路是"部分结果好过无结果"。LLM 不是可靠的函数调用——它会超时、会返回空、会幻觉工具、会重复提交。AgentRuntime 的每一层防护都基于这个现实假设。
下一章深入 Capability × Strategy × Policy 三维正交组合——Alembic Agent 架构最独特的设计。