架构全景 — DDD 分层与模块拓扑
从顶层俯瞰 Alembic 的 7 层架构,理解每层的边界与职责。
问题场景
一个 12 万行代码的知识引擎,如果不划分清晰的层次,维护者需要理解所有代码才能修改一个功能。更严重的是,循环依赖会让任何重构都变成噩梦——你想修改 Guard 引擎的检测逻辑,却发现它被 Search、Knowledge、Agent 三个模块直接引用,牵一发而动全身。
Alembic 需要一种架构,让每一层只知道它应该知道的事情。这不是过度设计——当系统的消费者是不可控的外部 AI Agent 时,清晰的层次边界就是安全边界。
7 层分层架构
Alembic 的代码组织在 lib/ 目录下,形成 7 个逻辑层。每层有严格的单向依赖规则:上层可以依赖下层,反之不行。
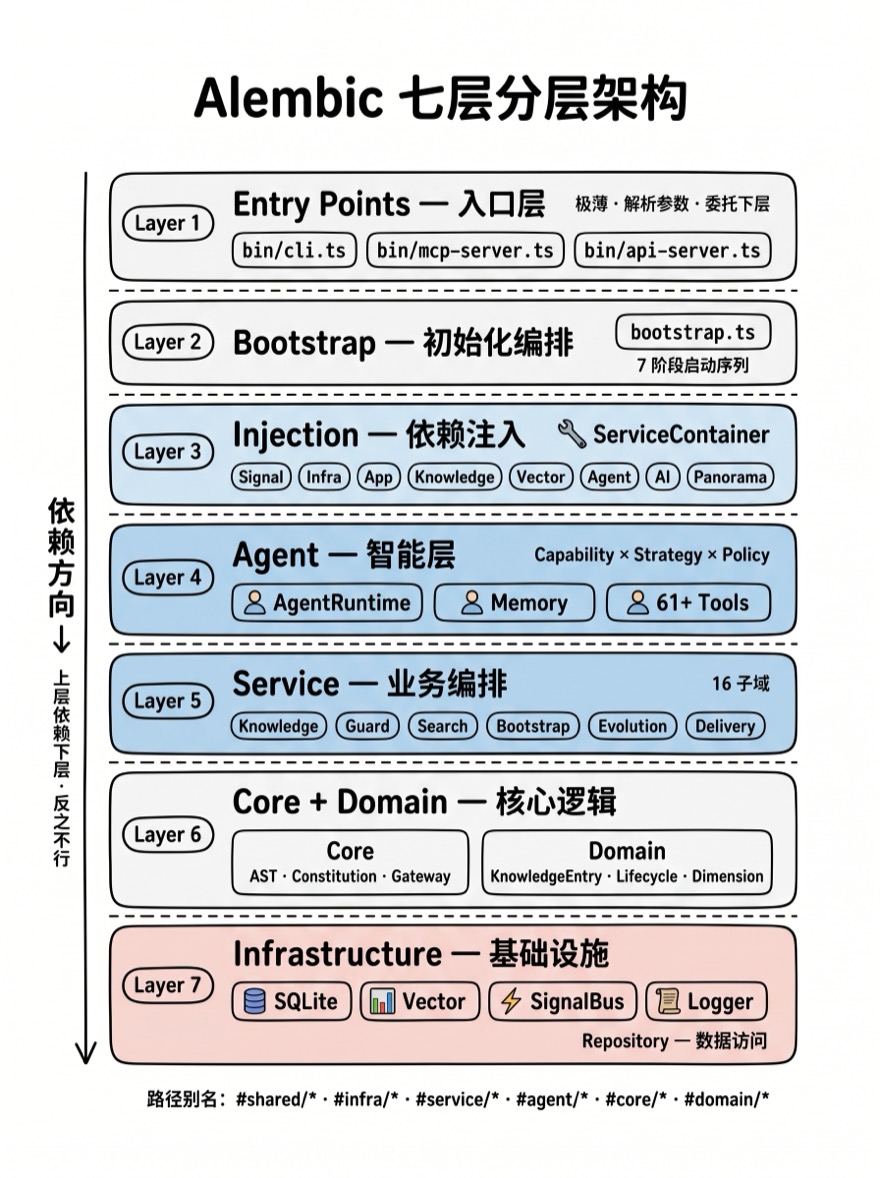
┌─────────────────────────────────────────────────┐
│ Layer 1: Entry Points │
│ bin/cli.ts · bin/mcp-server.ts · bin/api-server│
├─────────────────────────────────────────────────┤
│ Layer 2: Bootstrap │
│ lib/bootstrap.ts — 7 阶段初始化序列 │
├─────────────────────────────────────────────────┤
│ Layer 3: Injection │
│ lib/injection/ — ServiceContainer + 9 模块 │
├─────────────────────────────────────────────────┤
│ Layer 4: Agent │
│ lib/agent/ — AgentRuntime · Memory · 61+ Tools │
├─────────────────────────────────────────────────┤
│ Layer 5: Service │
│ lib/service/ — 16 子域的业务编排 │
├─────────────────────────────────────────────────┤
│ Layer 6: Core + Domain │
│ lib/core/ — AST · Constitution · Gateway │
│ lib/domain/ — KnowledgeEntry · Lifecycle │
├─────────────────────────────────────────────────┤
│ Layer 7: Infrastructure │
│ lib/infrastructure/ — DB · Vector · Signal · Log│
│ lib/repository/ — 数据访问层 │
└─────────────────────────────────────────────────┘Layer 1: Entry Points — 极薄的入口层
入口层负责且仅负责一件事:解析启动参数,把控制权交给下层。每个入口文件都短于 100 行(cli.ts 除外,它包含 20+ 个命令的定义,但每个命令内部仍然是一行委托调用)。
三个入口点覆盖所有使用场景:
| 入口 | 文件 | 消费者 | 职责 |
|---|---|---|---|
| CLI | bin/cli.ts | 开发者终端 | Commander 命令解析 → 委托 Service |
| MCP | bin/mcp-server.ts | IDE AI Agent | stdio 传输 → startMcpServer() |
| HTTP | bin/api-server.ts | Dashboard UI | Bootstrap → DI → HttpServer.start() |
以 MCP 入口为例,整个文件的核心逻辑只有三行:
// bin/mcp-server.ts
process.env.ASD_MCP_MODE = '1'; // 标记 MCP 模式
const { startMcpServer } = await import('../lib/external/mcp/McpServer.js');
startMcpServer().then((server) => {
shutdown.register(() => server.shutdown(), 'mcp-server');
});设置环境变量、动态 import MCP 服务器、注册关闭钩子——没有任何业务逻辑。CLI 入口稍长,但模式相同:每个 program.command() 的 .action() 回调内只做参数校验和一行委托:
// bin/cli.ts — coldstart 命令
program.command('coldstart')
.action(async (opts) => {
const { bootstrap, container } = await initContainer({ projectRoot });
// 一行委托,所有逻辑在 service 层
});这种极薄入口的好处是:三个入口共享完全相同的下层代码。MCP 服务器和 CLI 调用的是同一个 KnowledgeService、同一个 GuardCheckEngine,不存在行为不一致的风险。
Layer 2: Bootstrap — 7 阶段初始化
Bootstrap 类编排应用的启动序列,把"从零到就绪"分解为 7 个确定性阶段:
// lib/bootstrap.ts
async initialize() {
// Phase 0: loadDotEnv() — 加载 .env 环境变量
// Phase 1: loadConfig() — 加载环境相关配置(dev/prod)
// Phase 2: initializeLogger() — 初始化日志系统
// Phase 3: initializeDatabase() — 连接 SQLite + 执行迁移
// Phase 4: loadConstitution() — 解析 constitution.yaml
// Phase 5: initializeCoreComponents() — 构建安全组件栈
// Phase 6: initializeGateway() — 初始化请求网关
}每个阶段的顺序是有依赖关系的:Phase 3(数据库)必须在 Phase 5(核心组件)之前,因为 AuditStore 需要数据库连接;Phase 4(宪法)必须在 Phase 6(网关)之前,因为网关依赖宪法规则做权限检查。
Phase 5 是关键——它在一个方法中构建出整个安全组件栈:
// lib/bootstrap.ts — initializeCoreComponents()
async initializeCoreComponents() {
// Constitution → Validator → Permission → Audit → SkillHooks
const constitutionValidator = new ConstitutionValidator(constitution!);
const permissionManager = new PermissionManager(constitution!);
const auditStore = new AuditStore(db!);
const auditLogger = new AuditLogger(auditStore);
const skillHooks = new SkillHooks();
await skillHooks.load();
}Bootstrap 还有一个静态方法 configurePathGuard(),必须在任何文件写操作之前调用——它配置文件系统沙箱,确保后续所有写操作都在白名单范围内。
Bootstrap 产出的组件集合(BootstrapComponents)会被注入到 Layer 3 的 DI 容器中,成为所有上层服务的根依赖。
Layer 3: Injection — 依赖注入容器
ServiceContainer 是整个系统的组装工厂。它管理 60+ 个服务的创建、缓存和生命周期,通过 9 个模块分批注册。
// lib/injection/ServiceContainer.ts
async initialize(bootstrapComponents) {
// 注入 Bootstrap 核心组件
this.singletons.database = bootstrapComponents.db;
this.singletons.auditLogger = bootstrapComponents.auditLogger;
this.singletons.gateway = bootstrapComponents.gateway;
this.singletons.constitution = bootstrapComponents.constitution;
// AI Provider 初始化(异步:需要检测可用的 provider)
await AiModule.initialize(this);
// 按依赖顺序注册 9 个模块
InfraModule.register(this); // 基础设施 + 仓储
SignalModule.register(this); // 信号总线(eager-load)
this.get('signalBus'); // 预热:确保后续模块可用
AppModule.register(this); // 质量评分 · Recipe 解析
KnowledgeModule.register(this); // 知识服务 · 搜索引擎
VectorModule.register(this); // 向量存储适配
GuardModule.register(this); // 合规引擎
AgentModule.register(this); // Agent 运行时 · 工具注册
AiModule.register(this); // AI Provider 管理
PanoramaModule.register(this); // 全景分析
}注册顺序至关重要:SignalModule 必须在所有业务模块之前,因为 HitRecorder、GuardFeedbackLoop 等服务在创建时需要订阅信号总线。InfraModule 提供仓储层(KnowledgeRepository、ProposalRepository 等),必须在 KnowledgeModule 之前,因为 KnowledgeService 的工厂函数会调用 ct.get('knowledgeRepository')。
模块注册后还有三步后初始化:
// 异步加载 17 个框架增强包(Tree-sitter 语言增强)
await initEnhancementRegistry();
// 绑定 EventBus → SearchEngine.refreshIndex(知识变更时自动刷新索引)
KnowledgeModule.initializeKnowledgeServices(this);
// 跨进程缓存协调器(利用 SQLite PRAGMA data_version 检测外部写入)
this.#initCacheCoordinator();为什么自建 DI 而非用框架
不用 InversifyJS / tsyringe 的原因很实际:
- 避免装饰器 — TypeScript 装饰器在 ESM 中的行为不稳定,且 Node.js 的
--experimentalDecorators和 TC39 Stage 3 装饰器语义不同 - 惰性初始化 —
singleton()模式天然支持按需创建,不需要额外的@lazy标记 - AI 热重载 —
reloadAiProvider()需要精确清除依赖 AI 的缓存单例,框架 DI 很难做到这种细粒度控制
整个 DI 的核心只有两个方法:
// lib/injection/ServiceContainer.ts
singleton(name, factory, options?) {
this.register(name, () => {
if (!this.singletons[name]) {
this.singletons[name] = factory(this);
}
return this.singletons[name];
});
}
get(name) {
return this.services[name](); // 首次调用时触发 factory
}singleton() 注册一个惰性工厂,get() 首次调用时执行工厂并缓存结果。没有反射、没有装饰器、没有 token——就是一个 Map<string, () => unknown> 加上缓存逻辑。类型安全通过 ServiceMap 接口实现:
// lib/injection/ServiceMap.ts
export interface ServiceMap {
// ═══ InfraModule ═══
database: DatabaseConnection;
auditLogger: AuditLogger;
gateway: Gateway;
eventBus: EventBus;
knowledgeRepository: KnowledgeRepositoryImpl;
// ═══ KnowledgeModule ═══
knowledgeService: KnowledgeService;
searchEngine: SearchEngine;
// ═══ GuardModule ═══
guardService: GuardService;
guardCheckEngine: GuardCheckEngine;
// ═══ AgentModule ═══
toolRegistry: ToolRegistry;
agentFactory: AgentFactory;
// ═══ SignalModule ═══
signalBus: SignalBus;
hitRecorder: HitRecorder;
// ═══ PanoramaModule ═══
panoramaService: PanoramaService;
// ... 60+ services total
}container.get('searchEngine') 在编译期就能推导出返回类型是 SearchEngine,不需要泛型参数或类型断言。
Layer 4: Agent — 智能中枢
Agent 层是系统的"大脑"——AgentRuntime 驱动 ReAct 推理循环,ToolRegistry 管理 61+ 个工具,AgentFactory 通过正交组合创建不同配置的 Agent 实例。
Agent 层只依赖 Service 层和 Infrastructure 层,不直接操作数据库或文件系统。所有副作用通过工具调用间接执行——Agent 调用 submit_knowledge 工具,工具内部委托 KnowledgeService.create(),服务操作 KnowledgeRepository,仓储写入 SQLite。
这种间接性是设计约束,不是偶然:Agent 的每个操作都经过工具层的权限检查和参数验证,不可能绕过 Gateway 直接修改数据。
Layer 5: Service — 业务编排
lib/service/ 包含 16 个子域目录,每个子域是一个独立的业务关注点:
| 子域 | 目录 | 核心服务 | 职责 |
|---|---|---|---|
| 知识管理 | knowledge/ | KnowledgeService | CRUD · 相似度检查 · 审计 |
| 搜索引擎 | search/ | SearchEngine | 字段加权 · 向量检索 · 语义 rerank |
| 合规检查 | guard/ | GuardCheckEngine | 四层检测 · 三态输出 |
| 信号采集 | signal/ | HitRecorder | 使用信号批量落盘 |
| 质量评估 | quality/ | QualityScorer | 多维评分 · 反馈循环 |
| 知识进化 | evolution/ | DecayDetector | 衰退检测 · 进化提案 |
| 全景分析 | panorama/ | PanoramaService | 模块图 · 耦合 · 分层 |
| 冷启动 | bootstrap/ | BootstrapTaskManager | 14 阶段编排 |
| 知识交付 | delivery/ | CursorDeliveryPipeline | 6 通道 IDE 推送 |
| Recipe 解析 | recipe/ | RecipeParser | Markdown ↔ KnowledgeEntry |
| 向量服务 | vector/ | VectorService | HNSW 索引 · 上下文增强 |
| 模块管理 | module/ | ModuleService | 代码模块实体合并 |
| 技能系统 | skills/ | SkillHooks | 自定义技能钩子 |
| 任务系统 | task/ | PrimeSearchPipeline | 任务上下文预加载 |
| 源引用 | sourceref/ | SourceRefReconciler | 证据链健康检查 |
| 远程执行 | remote/ | RemoteCommandService | 飞书远程命令 |
Service 层的每个类都通过构造函数注入依赖,不直接实例化其他服务。这使得每个服务都可以独立测试:mock 掉仓储和信号总线,就能测试 KnowledgeService 的业务逻辑。
Layer 6: Core + Domain — 纯逻辑层
lib/core/ 和 lib/domain/ 是系统的"无副作用层"——它们定义领域模型和核心算法,不做 IO 操作。
Domain(领域模型):
KnowledgeEntry— 知识实体,携带 25 维分类、质量评分、置信度Lifecycle— 六态状态机及合法转换表FieldSpec— 字段验证规范DimensionFramework— 25 维分类框架
Core(核心算法):
ast/— Tree-sitter 多语言 AST 解析constitution/— 宪法规则引擎gateway/— 请求网关管线permission/— 3-tuple 权限模型discovery/— 项目类型探测enhancement/— 17 个框架增强包
Domain 层的特点是:所有方法都是纯函数或状态机转换。Lifecycle.canTransit(from, to) 查表返回布尔值,不查数据库、不调 API、不写日志。这种无副作用设计让领域逻辑可以在毫秒级完成单元测试。
Layer 7: Infrastructure — 数据访问与系统集成
最底层提供所有与外部世界交互的能力:
Infrastructure(lib/infrastructure/):
database/— SQLite 连接 · WAL 模式 · 迁移管理vector/— HNSW 向量索引 · BatchEmbeddersignal/— SignalBus · SignalAggregator · SignalTraceWritercache/— CacheCoordinator · GraphCachelogging/— 结构化日志audit/— AuditStore · AuditLoggerevent/— EventBus(进程内发布/订阅)config/— 环境配置加载realtime/— WebSocket 实时推送
Repository(lib/repository/):
- 15 个子域的数据访问实现
- 每个仓储封装 SQL 查询,向上暴露领域友好的接口
KnowledgeRepositoryImpl.findByTrigger(trigger)而非db.query('SELECT * FROM ...')
Infrastructure 层不知道任何业务逻辑。DatabaseConnection 只管连接和迁移,不知道什么是 Recipe;SignalBus 只管信号分发,不知道什么是衰退检测。
启动流程
三个入口点(CLI / MCP / HTTP)共享同一套两阶段初始化流程。以 HTTP 入口为例:
bin/api-server.ts
│
├──→ Bootstrap.configurePathGuard(projectRoot) // 文件系统沙箱
│
├──→ bootstrap = new Bootstrap({ env })
├──→ components = await bootstrap.initialize() // 7 阶段
│ ├── Phase 0: .env │
│ ├── Phase 1: ConfigLoader │
│ ├── Phase 2: Logger │ Stage 1:
│ ├── Phase 3: Database + Migrations │ Bootstrap
│ ├── Phase 4: Constitution │
│ ├── Phase 5: Validator + Permission + Audit│
│ └── Phase 6: Gateway │
│
├──→ container = getServiceContainer()
└──→ await container.initialize(components) // 9 模块注册
├── AiModule.initialize() │
├── InfraModule.register() │
├── SignalModule.register() + eager-load │ Stage 2:
├── AppModule.register() │ DI Container
├── KnowledgeModule.register() │
├── VectorModule.register() │
├── GuardModule.register() │
├── AgentModule.register() │
├── AiModule.register() │
└── PanoramaModule.register() │两阶段设计的意义:Stage 1(Bootstrap)产出的是不可变的基础设施组件(数据库连接、宪法规则、审计系统),Stage 2(DI Container)基于这些组件构建可替换的业务服务。
ServiceContainer 有一个关键的防护机制——多项目防护:
// lib/injection/ServiceContainer.ts
const newRoot = bootstrapComponents.projectRoot;
const existingRoot = this.singletons._projectRoot;
if (newRoot && existingRoot && newRoot !== existingRoot) {
throw new Error(
`不允许在同一进程中切换项目。当前绑定: ${existingRoot}, 请求: ${newRoot}。`
);
}一旦容器绑定了项目根目录,就不允许在同一进程内切换到另一个项目。这防止了 MCP 服务器在不同项目之间串话——每个项目一个独立进程。
请求生命周期
一条 MCP 请求(例如 asd_search({ query: "API 接口" }))从接收到响应的完整路径:
IDE Agent (Cursor / Copilot)
│ stdio / MCP Protocol
▼
bin/mcp-server.ts → McpServer.handleRequest()
│
▼
lib/external/mcp/handlers/searchHandler.ts ← Layer 1: Entry routing
│
▼
Gateway.execute({ action: 'search', role: 'external_agent', ... })
│ 1. validate — 请求格式检查 ← Layer 6: Core
│ 2. guard — 权限验证(Constitution + Permission)
│ 3. route — 分发到注册的处理器
│ 4. audit — 记录审计日志
▼
SearchEngine.search(query, options) ← Layer 5: Service
│ 1. FieldWeighted scoring
│ 2. MultiSignal ranking (usage / guard / quality)
│ 3. Semantic rerank (if AI available)
▼
KnowledgeRepository.findByIds(ids) ← Layer 7: Repository
│ SQL query → SQLite
▼
SearchEngine → formatted results
│
▼
McpServer → MCP Protocol response → IDE Agent请求穿越了所有 7 层,但每层只做分内之事:入口层解析协议,Gateway 做权限检查,Service 做业务编排,Repository 做数据访问。层间通过 DI 容器的 container.get() 获取依赖,不存在跨层直接 import。
代码组织约定
12 条路径别名
Alembic 使用 Node.js 的 package.json imports 字段定义路径别名,替代 TypeScript 的 paths 配置(后者在运行时不生效):
// package.json
"imports": {
"#shared/*": { "asd-dev": "./lib/shared/*", "default": "./dist/lib/shared/*" },
"#infra/*": { "asd-dev": "./lib/infrastructure/*", "default": "./dist/lib/infrastructure/*" },
"#service/*": { "asd-dev": "./lib/service/*", "default": "./dist/lib/service/*" },
"#agent/*": { "asd-dev": "./lib/agent/*", "default": "./dist/lib/agent/*" },
"#domain/*": { "asd-dev": "./lib/domain/*", "default": "./dist/lib/domain/*" },
"#inject/*": { "asd-dev": "./lib/injection/*", "default": "./dist/lib/injection/*" },
"#core/*": { "asd-dev": "./lib/core/*", "default": "./dist/lib/core/*" },
"#external/*": { "asd-dev": "./lib/external/*", "default": "./dist/lib/external/*" },
"#platform/*": { "asd-dev": "./lib/platform/*", "default": "./dist/lib/platform/*" },
"#repo/*": { "asd-dev": "./lib/repository/*", "default": "./dist/lib/repository/*" },
"#types/*": { "asd-dev": "./lib/types/*", "default": "./dist/lib/types/*" },
"#http/*": { "asd-dev": "./lib/http/*", "default": "./dist/lib/http/*" }
}两个条件导出的含义:asd-dev 是开发态(npm run dev:link 时设置 --conditions=asd-dev),直接从 lib/ 源码加载,支持 HMR;default 是发布态,从 dist/ 编译产物加载。
使用示例:
import { resolveProjectRoot } from '#shared/resolveProjectRoot.js';
import Constitution from '#core/constitution/Constitution.js';
import { KnowledgeService } from '#service/knowledge/KnowledgeService.js';注意 .js 后缀——这是 ESM 的强制要求。TypeScript 源文件是 .ts,但 import 路径必须写 .js,因为 Node.js 运行时解析的是编译后的 .js 文件。
单向依赖规则
路径别名的层级暗示了依赖方向:
#agent/* → #service/* → #core/* → #domain/* → (无外部依赖)
→ #repo/* → #infra/*
→ #shared/* (工具函数,任何层可用)禁止的依赖方向:
#infra/*不能 import#service/*(基础设施不知道业务)#domain/*不能 import#infra/*(领域模型不做 IO)#core/*不能 import#agent/*(核心算法不知道 Agent)#service/*不能 import#agent/*(服务不依赖智能层)
#shared/* 是例外——它提供跨层工具函数(PathGuard、package-root、LanguageService),任何层都可以引用,但它自身不依赖任何业务层。
模块规模概览
lib/ 下 14 个目录的代码分布:
| 目录 | 文件数 | 职责层 |
|---|---|---|
infrastructure/ | ~30 | Layer 7: 数据库 · 向量 · 信号 · 缓存 · 日志 |
repository/ | ~20 | Layer 7: 15 个子域的数据访问 |
service/ | ~70 | Layer 5: 16 个子域的业务逻辑 |
agent/ | ~30 | Layer 4: Runtime · Memory · Context · Tools |
core/ | ~20 | Layer 6: AST · Constitution · Gateway · Discovery |
domain/ | ~15 | Layer 6: 领域实体 · 状态机 · 验证 |
injection/ | 11 | Layer 3: ServiceContainer + 9 模块 |
shared/ | ~12 | 跨层: PathGuard · 工具函数 |
external/ | ~10 | 外部接口: MCP · Lark · AI |
http/ | ~8 | HTTP 路由与中间件 |
cli/ | 5 | CLI 专用服务: Setup · AiScan · Upgrade |
types/ | ~8 | TypeScript 类型定义 |
platform/ | ~3 | 平台适配: OpenBrowser · ScreenCapture |
bootstrap.ts | 1 | Layer 2: 启动编排 |
Service 层(~70 文件)是最大的——这符合 DDD 的预期:业务逻辑是系统的核心复杂度所在。Infrastructure(~50 文件)次之,因为 SQLite + 向量索引 + 信号系统 + 缓存的实现细节不可避免地需要大量代码。
递归模式
Alembic 有一个独特的特性:它用自己来开发自己。
项目的 .github/copilot-instructions.md 和 AGENTS.md 由 Alembic 的 Delivery 通道生成——也就是说,开发者在用 Copilot 写 Alembic 代码时,Copilot 读取的编码规范是 Alembic 自己从代码中提取的。这是一个完美的反馈回路:写代码 → 提取规范 → 规范指导写代码 → 提取更好的规范。
但这个递归引入了一个危险:如果 MCP 服务器把 Alembic 源码仓库当作用户项目,它会在源码目录里创建 .asd/ 数据库、Alembic/candidates/ 候选知识——运行时垃圾污染源码树。
isOwnDevRepo() 保护机制
isOwnDevRepo 通过三个同时成立的条件检测当前目录是否是 Alembic 自己的开发仓库:
// lib/shared/isOwnDevRepo.ts
export function isAlembicDevRepo(dir: string): boolean {
const pkg = JSON.parse(fs.readFileSync(path.join(dir, 'package.json'), 'utf-8'));
if (pkg.name === 'alembic') {
const hasBootstrap = fs.existsSync(path.join(dir, 'lib', 'bootstrap.ts'));
const hasSoul = fs.existsSync(path.join(dir, 'SOUL.md'));
return hasBootstrap && hasSoul; // 三条件同时满足
}
return false;
}为什么需要三个条件?只检查 package.json 的 name 字段不够——用户可能 fork 了项目但没改名。加上 lib/bootstrap.ts(源码标记)和 SOUL.md(灵魂文档)的存在性检查,基本排除了误判。
检测结果在多个层面产生效果:
| 组件 | 行为变化 |
|---|---|
DatabaseConnection | DB 路径重定向到 $TMPDIR/alembic-dev/ |
PathGuard | 阻止创建 .asd/ 和知识库目录 |
SetupService | 拒绝执行 asd setup |
这样,开发者可以在 Alembic 源码仓库内正常运行 MCP 服务器(IDE 的 Agent 需要它),但所有运行时数据被隔离到临时目录,不会污染 git 工作树。
权衡与替代方案
为什么不用微服务
Alembic 是一个本地化工具——它运行在开发者的机器上,数据存储在项目目录内的 SQLite 文件中。微服务的核心优势(独立部署、独立扩展)在这个场景下毫无意义:你不需要独立扩展 Guard 检测和 Search 排序,它们跑在同一台笔记本上。
单进程的好处是:服务间调用是内存函数调用(< 0.01ms),不是 HTTP/gRPC 网络请求(> 1ms)。SignalBus 的信号分发是同步的——在微服务架构下这需要 MessageQueue,引入延迟和复杂度。
为什么不用 Monorepo + Turborepo
当前的单包结构已经通过路径别名和分层架构获得了清晰的模块边界。Monorepo 解决的问题(独立版本号、独立发布、独立构建缓存)在 Alembic 中不存在——它是一个整体发布的 CLI 工具:npm install -g alembic 安装一切。
唯一的子项目是 Dashboard(dashboard/,React + Vite)和 VSCode Extension(resources/vscode-ext/),它们有独立的 package.json 和构建流程,但通过 npm scripts 统一编排,不需要 Turborepo 的任务调度。
为什么不用 ORM
SQLite 访问层使用 Drizzle ORM 做类型安全的查询构建,但仓储层(lib/repository/)定义了领域友好的接口。这是一个半 ORM 方案——享受类型安全的查询构建,但保留手写 SQL 的能力(向量搜索和全文搜索的复杂查询很难用 ORM 表达)。
小结
Alembic 的 7 层架构不是为了"看起来专业"而设计的分层,它解决的是一个真实问题:当系统的消费者是不可信任的外部 AI Agent 时,清晰的层次边界就是最基本的安全保障。
- 极薄入口确保三个入口点(CLI / MCP / HTTP)行为一致
- 两阶段初始化将不可变的安全组件和可替换的业务服务分离
- 惰性 DI 容器用 60 行代码管理 60+ 个服务,无框架依赖
- 单向依赖规则通过路径别名在文件名级别强制执行
- 递归保护让系统能安全地用自己开发自己
下一章将深入安全管线——看 Constitution、Gateway 和六层纵深防御如何协同守护每一条进入系统的请求。