Alembic 介绍
将代码库中的模式提取为知识库,供 IDE 中的 AI 编码助手查询——让生成的代码真正符合你们团队的规范。
问题:AI 不知道你们怎么写代码
Copilot 和 Cursor 不知道你们团队怎么写代码。它们生成的东西能跑,但不像你们写的——命名不对、模式不对、抽象层次不对。最后要么你重写 AI 的输出,要么在每次 Code Review 里反复解释同样的规范。
更深层的问题是:这不是提示词能解决的。你可以写一页 System Prompt 告诉 AI "我们用 Repository 模式访问数据",但当项目有 200 个这样的约定时,没有哪个上下文窗口装得下。即使装得下,LLM 在长上下文中的注意力衰减也会让大部分规范形同虚设。
这个问题的本质是:团队的编码知识是分散的、隐式的、持续演化的,而 LLM 需要的是结构化的、可检索的、确定性的输入。
方案:本地化的项目知识引擎
Alembic 在你的代码库和 AI 之间建立一层本地化的项目记忆。它扫描你的代码库,通过 AST 分析和 AI 理解提取有价值的模式(需要你批准),然后通过 MCP 让所有 AI 工具都能按需查询。
你的代码 → AST 分析 + AI 提取 → 你来审核 → 知识库( .md 文件 + 本地 SQLite )
↓
Cursor / Copilot / VS Code / Claude Code / Xcode
↓
AI 按你的模式生成
↓
Guard 引擎自动合规检查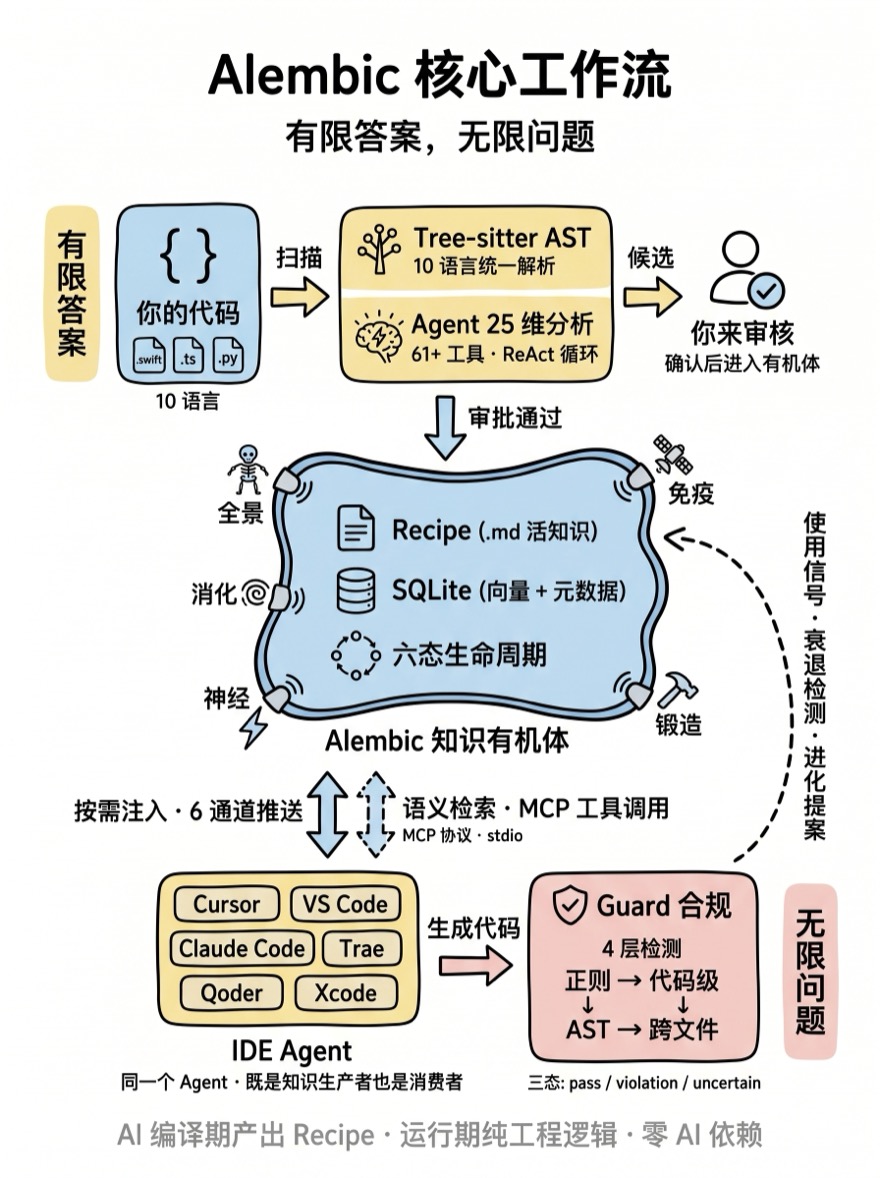
这些知识持久化在本地,不占用 LLM 的上下文窗口,而是在 AI 需要时按需注入——项目知识积累得越多,生成的代码越符合你们的规范。
知识不是静态快照。每条知识有自己的六态生命周期(pending → staging → active → evolving → decaying → deprecated),会随着代码的演进自动衰减、进化或淘汰。SourceRefReconciler 持续检测知识引用的源文件是否存活,其结果通过信号系统被 ReverseGuard、DecayDetector 等消费,驱动知识生命周期转换,确保知识库的可信度。
核心洞察:有限答案,无限问题
传统的 AI 编码辅助是每次对话都从零开始:你给它上下文,它给你代码。上下文窗口是有限的,你的项目约定却在不断膨胀——200 条规范塞不进 128K token,即使塞进去注意力衰减也会让大部分形同虚设。这是一场你注定输掉的军备竞赛。
Alembic 反转了这个等式。
先提交有限的答案,用来回答无限的问题。
一次冷启动产出几十到几百条 Recipe——这是"有限的答案"。但每一条都经过 AST 验证、质量评分、人工审核,是项目真实模式的精确表达。此后,无论团队成员问出什么样的编码问题,Agent 都能从这有限的知识库中组合出准确的回答。知识库不需要覆盖所有可能的问题——它捕获项目的核心模式和约定,剩下的由 Agent 的推理能力补全。
更关键的是:发问与回答在同一个 Agent 内完成。 编程 Agent 通过 MCP 工具与知识库语义对话——不是把知识库塞进上下文,而是通过结构化的工具接口按需检索。同一个 Agent 既是知识的生产者(冷启动时提取模式),也是知识的消费者(日常编码时查询规范、检查合规)。提取知识的 Agent 理解这些知识的语义结构,使用知识的 Agent 知道应该如何提问——这不是两个割裂的系统,而是一个自洽的认知闭环。
这个洞察构成了整个系统的设计原点。后续章节中每一个工程决策,最终都在回答同一组问题:如何让有限的知识覆盖更广的问题空间?如何让知识的生产和消费成本趋近于零?如何让这个闭环自我强化而非自我衰减?
使用速览
npm install -g alembic
cd your-project
asd setup # 初始化工作空间 + 数据库 + MCP 配置
asd ui # 启动后台服务,IDE 和 MCP 工具依赖此服务运行Trae / Qoder 用户:
asd setup后运行asd mirror,将.cursor/配置同步到.trae//.qoder/。
安装完成后,打开 IDE 的 Agent Mode(Cursor Composer / VS Code Copilot Chat / Trae),跟 Agent 对话即可——asd setup 已通过 MCP 协议将 Alembic 注册为工具服务。
首次使用: 需在 IDE 的 MCP 设置中手动开启
alembic服务。
提示: IDE Agent 使用的模型越强,效果越好。推荐选择 Claude Opus 4.6 / Sonnet 4.6、GPT-5.4 或 Gemini 3.1 Pro。
冷启动:建立项目知识库
💬 "帮我冷启动,生成项目知识库"
Agent 扫描整个项目,提取出团队的编码模式、架构约定、调用习惯,同时生成项目 Wiki。冷启动只做一次,之后就进入日常使用。
冷启动背后是一条完整的管线:文件收集 → 10 语言 AST 解析(Tree-sitter)→ 25 维度框架分析 → 61+ 工具编排的 Agent 推理循环 → 人工审核。Agent 不是简单的"让 LLM 读代码然后总结",而是在结构化分析的基础上做确定性标记,只把真正不确定的部分交给 LLM 消解。
日常:说一句话就行
| 你说 | 你得到 |
|---|---|
| ① "项目里 API 接口怎么写" | 直接拿到符合你们项目风格的代码,而不是通用示例 |
| ② "帮我写一个用户注册接口" | 生成的代码自动遵循刚才查到的 API 规范 |
| ③ "检查这个文件符不符合项目规范" | 提交前过一遍规范检查,减少 Code Review 里的反复沟通 |
| ④ "把这段错误处理保存为项目规范" | 一次沉淀,以后所有人的 AI 都会学会这个写法 |
Agent 写完代码后,Guard 合规引擎会自动检查 diff——发现违规即自我修复,不需要你手动介入。
越用越好
候选在 Dashboard(asd ui)中审核并批准 → 变成 Recipe → AI 生成代码时自动参照 → 你发现新的好写法 → 继续沉淀 → AI 越来越像团队的人。这些知识是本地 Markdown 文件,跟 git 走,不会随对话消失,也不占上下文窗口——知识库再大也不会拖慢 AI。
进化架构
Alembic 不是静态知识工具,而是一个知识有机体。Recipe 是它的细胞——IDE Agent 是外部驱动力,每一次交互都会触发有机体内不同器官的协同响应。
IDE Agent (Cursor / Copilot / Trae)
│
│ 沉淀 · 编写 · 搜索 · 偏移 · 完成 · 边界
│
═════════════════▼══════════════════════════════════════
║ Alembic 知识有机体 ║
║ ║
║ ┌─ Panorama (骨骼) ────────── 项目结构全貌 ──────┐ ║
║ │ │ ║
║ │ Signal (神经) ◄────► Governance (消化) │ ║
║ │ ↕ ↕ │ ║
║ │ ┌──────────┐ │ ║
║ │ │ Recipe │ │ ║
║ │ │ 知识生命体│ │ ║
║ │ └──────────┘ │ ║
║ │ ↕ ↕ │ ║
║ │ Guard (免疫) ◄────► Tool Forge (造物) │ ║
║ │ │ ║
║ └────────────────────────────────────────────────┘ ║
║ ║
═════════════════════════════════════════════════════════Agent 行为 × 有机体响应
IDE Agent 的每个行为,都会触发有机体内不同器官的协同响应:
| Agent 行为 | 有机体响应 | 参与器官 |
|---|---|---|
| 沉淀知识 — 提取模式并提交 | 消化系统内部消化:置信度路由 → staging 观察 → 进化或衰退,开发者保留全程干预权 | 消化 → 神经 |
| 编写代码 — 开始写代码 | 神经系统分析意图,自动注入相关 Recipe,附带 sourceRefs 源码证据提升可信度 | 神经 → Recipe |
| 搜索知识 — 主动搜索 | 基于当前意图 + 文件上下文精准检索,多路融合排序,按场景动态调整权重 | 神经 → Recipe |
| 偏移意图 — 改变方向 | 神经系统记录偏移信号,感知问题,免疫系统反向检查 Recipe 是否仍然有效 | 神经 → 免疫 |
| 完成任务 — 写完代码 | 免疫系统触发 Guard Review,挂载相关 Recipe 给 Agent 修复违规 | 免疫 → Recipe |
| 能力边界 — 遇到无法处理的问题 | 造物系统调用 LLM 自建临时工具,vm 沙箱隔离执行,到期自动回收 | 造物 |
五大器官
骨骼 — Panorama
有机体的结构感知。AST + 调用图推断模块角色与分层(四信号融合,13 种角色类型),Tarjan SCC 计算耦合度,Kahn 拓扑排序推断分层,DimensionAnalyzer 生成 11 维健康雷达,输出覆盖率热力图和能力缺口报告。所有器官共享这份项目全貌。→ Ch03 架构全景 · Ch05 代码理解
消化 — Governance
新知识进入有机体后的代谢引擎。ContradictionDetector 检测矛盾,RedundancyAnalyzer 分析冗余,DecayDetector 评估衰退(6 策略 + 4 维评分),ConfidenceRouter 数值路由(≥ 0.85 自动发布,< 0.2 拒绝)。ProposalExecutor 到期自动执行进化提案(7 种类型,差异化观察窗口)。六态生命周期:pending → staging → active → evolving/decaying → deprecated。→ Ch06 KnowledgeEntry · Ch07 生命周期
神经 — Signal + Intent
感知 Agent 的所有行为。IntentExtractor 提取术语、推断语言和模块、中英文同义词展开,识别 4 种场景。SignalBus 统一 12 种信号类型(guard / search / usage / lifecycle / quality / exploration / panorama / decay / forge / intent / anomaly / guard_blind_spot),HitRecorder 批量采集使用事件。当 Agent 偏移意图时,神经系统记录漂移信号,协调免疫系统反向检查。→ Ch12 Panorama · Signal
免疫 — Guard
双向免疫系统。正向:四层检测(正则 → 代码级多行 → tree-sitter AST → 跨文件),内置 8 语言规则,三态输出(pass / violation / uncertain)。反向:ReverseGuard 验证 Recipe 引用的 API 符号是否仍存在(5 种漂移类型)。Agent 完成任务时自动触发 Review,将违规连同相关 Recipe 一起交给 Agent 修复。RuleLearner 追踪 P/R/F1 自动调优。→ Ch10 Guard 引擎
造物 — Tool Forge
能力边界处的创造力。三种模式渐进——复用(0ms)→ 组合(10ms,原子工具拼装)→ 生成(~5s,LLM 写代码 → vm 沙箱验证:5s 超时 + 18 条安全规则)。临时工具 30min TTL,到期自动回收。LLM 只在锻造时参与,执行过程完全确定性。→ Ch13 AgentRuntime · Ch14 正交组合
设计哲学
这些哲学不是抽象原则,而是代码中随处可见的工程决策。Ch02 将深入解读每一项哲学如何化为具体的代码守护点。
- AI 编译期 + 工程运行期 — LLM 产出确定性执行物,运行期纯工程逻辑
- 确定性标记 + 概率性消解 — 每层做确定的事,不确定结构化上抛给 AI
- 正交组合 > 特化子类 — Capability × Strategy × Policy 替代 N 个子类
- 信号驱动 > 时间驱动 — 信号饱和触发,而非定时扫描
- 纵深防御 — Constitution → Gateway → Permission → SafetyPolicy → PathGuard → ConfidenceRouter
工程能力
上面是有机体本身。下面是它对外提供的工程集成能力。
Guard CLI
asd guard src/ # 检查目录
asd guard:staged # pre-commit 只查暂存文件
asd guard:ci --min-score 90 # CI 质量门禁多语言 AST
11 种语言 tree-sitter:Go · Python · Java · Kotlin · Swift · JS · TS · Rust · ObjC · Dart · C#。5 阶段 CallGraph,增量分析,8 种项目类型自动检测。
6 通道 IDE 交付
知识变更自动交付到 IDE 可消费的格式:
| 通道 | 路径 | 内容 |
|---|---|---|
| A | .cursor/rules/alembic-project-rules.mdc | alwaysApply 一行式规则 |
| B | .cursor/rules/alembic-patterns-{topic}.mdc | When/Do/Don't 主题规则 |
| C · D | .cursor/skills/ | Project Skills + 开发文档 |
| F | AGENTS.md / CLAUDE.md / .github/copilot-instructions.md | Agent 指令 |
| Mirror | .qoder/ / .trae/ | IDE 镜像 |
更多
- Bootstrap 冷启动 — 6 阶段 · 10 维分析,一次性建立知识库 → Ch09 Bootstrap
- 知识图谱 — 14 种关联关系,查询影响路径和依赖深度
- 语义搜索 — HNSW 向量索引 + 加权字段匹配混合检索,RRF 融合 + 7 路信号排序 → Ch11 混合检索
- sourceRefs — Recipe 携带源码证据,Agent 无需自行验证
- 飞书远程 — 手机发消息,意图识别分流到 Bot 或 IDE
- 远程仓库 — Recipe 目录转 git 子仓库,多项目共享
AI 驱动功能需 LLM API Key。支持 Google / OpenAI / Claude / DeepSeek / Ollama,自动 fallback。
工程规模
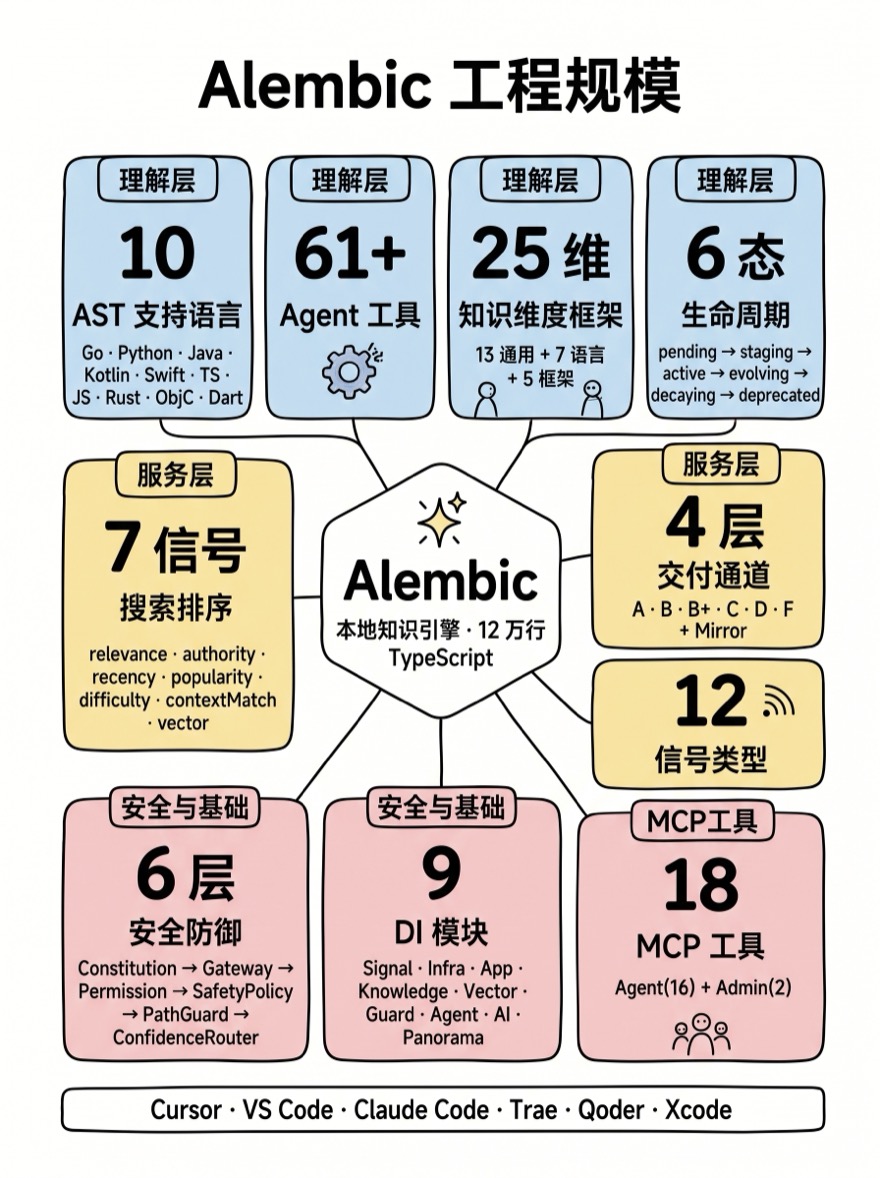
| 维度 | 数据 |
|---|---|
| AST 支持语言 | 10 种(Go · Python · Java · Kotlin · Swift · TS · JS · Rust · ObjC · Dart) |
| Agent 工具 | 61+ |
| 知识维度框架 | 25 维(13 通用 + 7 语言特定 + 5 框架特定) |
| 搜索信号 | 6 维加权 |
| Guard 检测层 | 4 层(正则 → 代码级 → AST → 跨文件) |
| 知识生命周期 | 6 态状态机 |
| 交付通道 | 6 通道 |
| 信号类型 | 12 种 |
| 安全防御层 | 6 层 |
| 支持 IDE | Cursor · VS Code · Claude Code · Trae · Qoder · Xcode |
| DI 模块 | 9 个(Signal · Infra · App · Knowledge · Vector · Guard · Agent · AI · Panorama) |
展望
"有限答案回答无限问题"不是一个已经到达的终点,而是一个持续逼近的方向。当前系统的每一项改进,本质上都在优化同一个等式的两端——让"有限的答案"更精准、更鲜活、更广泛,让"无限的问题"被回答得更快、更准、更自然。
Agent 能力的深度挖掘
目前产出的 Recipes 能够保证正确且有价值,但与全景分析对比仍有知识空白。25 维框架覆盖了分析的广度,但 Agent 在每个维度的深度挖掘能力仍有提升空间——目标是 90% 覆盖的可信任 Recipes。
快速演化项目的知识跟随
Alembic 自身就是一个架构频繁调整的项目,知识库需要设计更稳定的快速跟随方案。SourceRefReconciler 和 DecayDetector 已经解决了"知识过时"的检测问题,下一步是让知识在架构重构时能够自动重组而非逐条衰退。
主项目与子项目的知识共享
不同主项目中的同一子模块可能产出不一致的 Recipe。计划设计云端共享能力,子项目通过配置指向一份共享 Recipe 源,同时保留本地覆写的能力。
飞书讨论的快速落地
基于飞书 Lark Transport 的衍生功能:将技术讨论中确认的规范直接生成 Recipe,通过 Guard 引擎标注代码中的不合规处,支持自然语言提示词的一键修复。
Git 流水线集成
多人开发场景下,Guard 检查接入 CI/CD(asd guard:ci),Recipe 变更走 Pull Request 审核流程,知识库与代码仓库保持同步的版本控制。
本书结构
本书按照 Alembic 的架构层次组织,每一章对应一个核心模块,从设计动机到实现细节逐层展开:
- Part 1(起点与哲学):本章介绍 → 本地记忆主权 → SOUL 设计原则
- Part 2(工程基石):架构全景 → 安全管线 → 代码理解
- Part 3(知识领域):KnowledgeEntry 实体 → 六态生命周期 → 质量评分
- Part 4(核心服务):Bootstrap 冷启动 → Guard 合规 → Search 检索 → 信号代谢
- Part 5(Agent 智能层):Agent Runtime → 正交组合 → 工具与记忆
- Part 6(平台与交付):数据基础设施 → MCP 六通道交付 → 界面层